
Attention from Alignment, Practically Explained
Learn from what matters, Ignore what doesn’t.


Attention, as popularized by the landmark paper Attention Is All You Need (2017), is arguably the most important architectural trend in machine learning right now. Originally intended for sequence to sequence modeling, attention has exploded into virtually every sub-discipline of machine learning.
This post will describe a particular flavor of attention which proceeded the transforner style of attention. We’ll discuss how it works, and why it’s useful. We’ll also go over some literature and a tutorial implementing this form of attention in PyTorch. By reading this post, you will have a more thorough understanding of attention as a general concept, which is useful in exploring more cutting edge applications.
The Reason For Attention
The attention mechanism was originally popularized in Neural Machine Translation by Jointly Learning to Align and Translate(2014), which is the guiding reference for this particular post. This paper employs an encoder-decoder architecture for english-to-french translation.

This is a very common architecture, but the exact details can change drastically from implementation to implementation. For instance, some of the earlier literature in sequence to sequence encoder-decoders were recurrent networks that would incrementally “build” and then “deconstruct” the embedding.
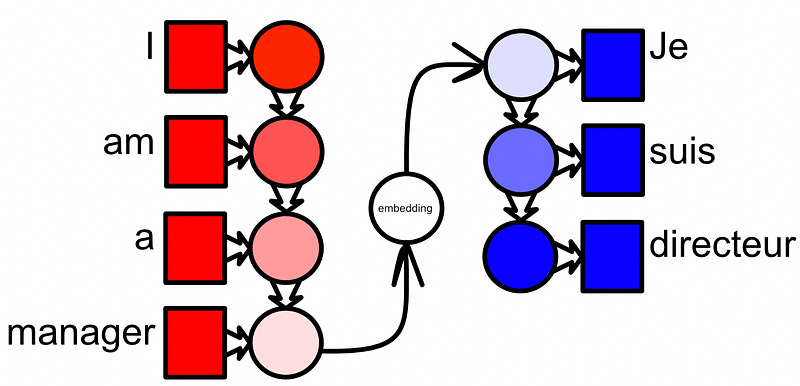
This general idea, and minor variations therein, was state of the art for several years. However, one problem with this approach is that the entire input sequence has to be embedded into the embedding space, which is generally a fixed sized vector. As a result, these models can easily forget content from sequences which are too long. The attention mechanism was designed to alleviate the problem of needing to fit the entire input sequence into the embedding space. It does this by telling the model which inputs are related to which outputs. Or, in other words, the attention mechanism allows a model to focus on relevant portions of the input, and disregard the rest.

How Attention is Done, From a High Level
Practically, the attention mechanism we will be discussing ends up being a matrix of scores, called “alignment” scores. These alignment scores encode the degree to which a word in an input sequence relates to a word in the output sequence.

The alignment score can be computed many ways. We’ll stick with our 2014 paper and pick apart it’s particular alignment function:

When calculating the allignment for the ith output, this approach uses the previous embedded state of the decoder (s_i-1), the embedding of an input word (h_j), and the learnable parameters W_a, U_a, and v_a, to calculate the alignment of the ith output with the jth input. The tanh activation function is included to add non-linearity, which is vital in training a model to understand complex relationships.
In other words, the function above calculates a score between the next output word and a single input word, denoting how relevant an input word is to the current output. This function is run across all input words (h_j) to calculate an alignment score for all input words given the current output.

A softmax function is applied across all of the computed alignments, turning them into a probability. This is referred to in the literature as a “soft-search” or “soft-alignment”.
Exactly how attention is used can vary from implementation to implementation. In Neural Machine Translation by Jointly Learning to Align and Translate(2014), the attention mechanism decides which input embeddings to provide to the decoder.

It does this selection process with a weighted sum. All input embeddings are multiplied by their respective alignment score (in practice most of the alignment scores have a value of zero, while one or two might have a value of 0.8 and 0.2 for instance), then those weighted embeddings are added together to create the context vector for a particular output.

The context vector is the combination of all of the inputs which are relevant to the current output.
The following figure ties together how attention fits into the bigger picture:
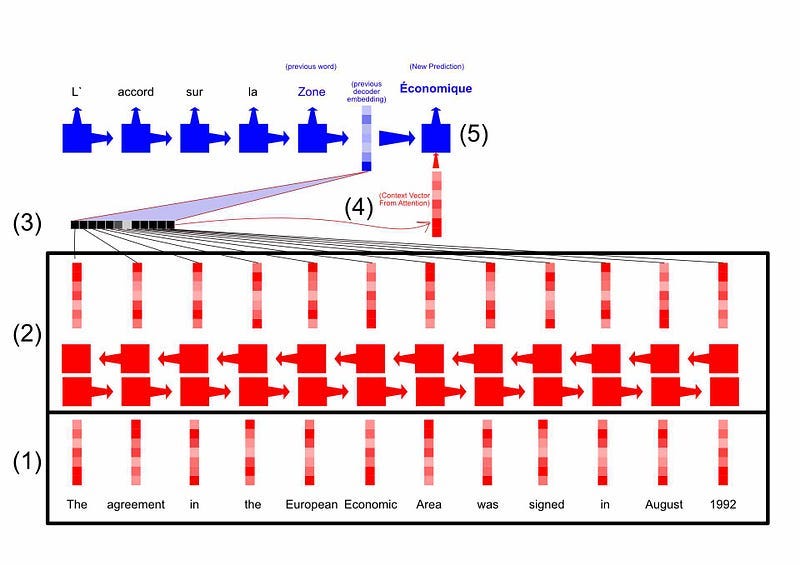
The inputs are embedded into some initial vector representation (using word2vect, for instance).
Those are passed through a bi-direcional LSTM, to create a bit of context awareness between the embeddings
Alignment scores are calculated for each input using the previous decoder embedding and the learned parameters within the alignment function.
The soft-maxed alignments are multiplied against each input, added together, and used to construct the context vector
The decoder uses the previous decoder hidden state, along with the context vector, to generate the prediction of the current word.
In the next section we will implement this attention mechanism in PyTorch.
Attention in PyTorch
While I originally set out to implement the entire english to french example, it became apparent that the implementation would be excessively long, and contain many intricacies which are irrelevant to the explanation of attention itself. As a result, I created a toy problem which mimics the grammatical aspects of english to french translation to showcase the attention mechanism specifically, without the bulk of implementing LSTM’s, embeddings, utility tokens, batching, masking, and other problem specific components.
The full code can be found here, for those that are interested
As previously mentioned, english to french translation can be thought of as two subproblems; alignment and translation. The various networks within the encoder and decoder translate values, while the attention mechanism re-orients the vectors. In other words, Attention is all about alignment. To emulate the alignment problem of english to french translation the following toy problem was defined:
given some shuffled input of values
[[ 0. 1.], [17. 18.], [10. 11.], [13. 14.], [14. 15.], [ 2. 3.] ... ]Organize them into a sequential output:
[[0. 1.], [1. 2.], [ 2. 3.], [ 3. 4.], [ 4. 5.], [ 5. 6.] ...]Practically, the toy question posed to the attention mechanism is: Given the previous output vector, which output should come next, given a selection of possible outputs? This is a very similar question to the gramatical question in english to french translation, which is: Given a previous output word, which inputs are relevant to the next one? Thus, by solving this toy problem, we can show the power of attention mechanism without getting too far in the weeds.
Defining the Alignment Function
Recall the alignment function

This function, essentially, decides the weight (α) of an input (hj) given the previous output (si-1). This can be implemented directly in PyTorch:
Keep reading with a 7-day free trial
Subscribe to Intuitively and Exhaustively Explained to keep reading this post and get 7 days of free access to the full post archives.