
Retrieval Augmented Generation — Intuitively and Exhaustively Explain
Making language models that can look stuff up


In this post we’ll explore “retrieval augmented generation” (RAG), a strategy which allows us to expose up to date and relevant information to a large language model. We’ll go over the theory, then imagine ourselves as resterauntours; we’ll implement a system allowing our customers to talk with AI about our menu, seasonal events, and general information.

Who is this useful for? Anyone interested in natural language processing (NLP).
How advanced is this post? This is a very powerful, but very simple concept; great for beginners and experts alike.
Pre-requisites: Some cursory knowledge of large language models (LLMs) would be helpful, but is not required.
The Core of the Issue
LLMs are expensive to train; chat GPT-3 famously cost a cool $3.2M on compute resources alone. If we opened up a new restaurant, and wanted to use an LLM to answer questions about a menu, it’d be cool if we didn’t have to dish out millions of dollars every time we introduced a new seasonal salad. We could do a smaller training step (called fine tuning) to try to get the model to learn a small amount of highly specific information, but this process can still be hundreds to thousands of dollars.
Another problem with LLMs is their confidence; sometimes they say stuff that’s flat out wrong with abject certainty (commonly referred to as hallucinating). As a result it can be difficult to discern where an LLM is getting its information from, and if that information is accurate. If a customer with allergies asks if a dish contains tree-nuts, it’d be cool if we could ensure our LLM uses accurate information so our patrons don’t go into anaphylactic shock.
Attorney Steven A. Schwartz first landed himself in hot water through his use of ChatGPT, which resulted in six fake cases being cited in a legal brief. — A famous example of hallucination in action. source
Both the issue of updating information and using proper sources can be mitigated with RAG.
Retrieval Augmented Generation, In a Nutshell
In-context learning is the ability of an LLM to learn information not through training, but by receiving new information in a carefully formatted prompt. For example, say you wanted to ask an LLM for the punchline, and only the punchline, of a joke. Jokes come in a setup-punchline combo extremely often, and because LLMs are statistical models it can be difficult for them to break that prior knowledge.

One way we can solve this is by giving the model “context”; we can give it a sample in a cleverly formatted prompt such that the LLM gives us the right information.

This trait of LLMs has all sorts of cool uses. I’ve written an article on how this ability can be used to talk with an LLM about images, and how it can be used to extract information from conversations. In this article we’ll be leveraging this ability to inject information into the model via a carefully constructed prompt, based on what the user asked about, to provide the model in-context information.

the RAG process comes in three key parts:
Retrieval: Based on the prompt, retrieve relevant knowledge from a knowledge base.
Augmentation: Combine the retrieved information with the initial prompt.
Generate: pass the augmented prompt to a large language model, generating the final output.

Retrieval
The only really conceptually challenging part of RAG is retrieval: How do we know which documents are relevant to a given prompt?
There’s a lot of ways this could be done. Naively, you could iterate through all your documents and ask an LLM “is this document relevant to the question”. You could pass both the document and the prompt to the LLM, ask the LLM if the document is relevant to the prompt, and use some query parser to get the LLM to give you a yes or no answer.
Alternatively, for an application as simple as ours, we could just provide all the data. We’ll probably only have a few documents we’ll want to refer to; our restaurant’s menu, events, maybe a document about the restaurants history. we could inject all that data into every prompt, combined with the query from a user.
However, say we don’t just have a restaurant, but a restaurant chain. We’d have a vast amount of information our customers could ask about: dietary restrictions, when the company was founded, where the stores are located, famous people who’ve dined with us. We’d have an entire franchise’s worth of documents; too much data to just put it all in every query, and too much data to ask an LLM to iterate through all documents and tell us which ones are relevant.
We can use word vector embeddings to deal with this problem. With word vector embeddings we can quickly calculate the similarity of different documents and prompts. The next section will go over word vector embeddings in a nutshell, and the following section will detail how they can be used for retrieval within RAG.
Word Vector Embeddings in a Nutshell
This section is an excerpt from my article on transformers:
Transformers — Intuitively and Exhaustively Explained

Machine Learning | Accelerated Computation | Artificial Intelligence In this post you will learn about the transformer architecture, which is at the core of the architecture of nearly all cutting-edge large language models. We’ll start with a brief chronology of some relevant natural language processing concepts, then we’ll go through the transformer step by step and uncover how it works.
In essence, a word vector embedding takes individual words and translates them into a vector which somehow represents its meaning.

The details can vary from implementation to implementation, but the end result can be thought of as a “space of words”, where the space obeys certain convenient relationships. Words are hard to do math on, but vectors which contain information about a word, and how they relate to other words, are significantly easier to do math on. This task of converting words to vectors is often referred to as an “embedding”.
Word2Vect, a landmark paper in the natural language processing space, sought to create an embedding which obeyed certain useful characteristics. Essentially, they wanted to be able to do algebra with words, and created an embedding to facilitate that. With Word2Vect, you could embed the word “king”, subtract the embedding for “man”, add the embedding for “woman”, and you would get a vector who’s nearest neighbor was the embedding for “queen”.
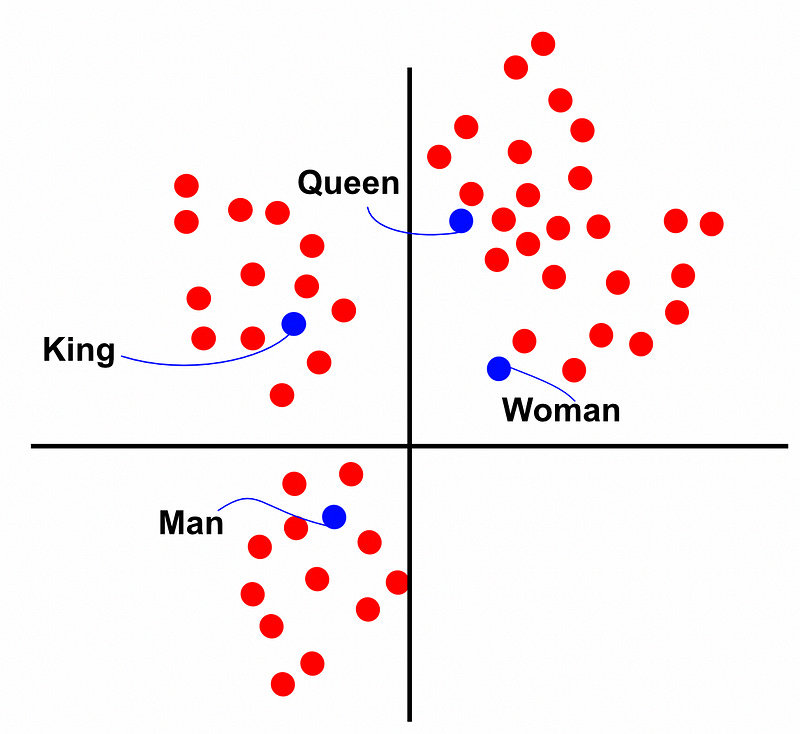
I’ll cover word embeddings more exhaustively in a future post, but for the purposes of this article they can be conceptualized as a machine learning model which has learned to group words as vectors in a meaningful way. With a word embedding you can start thinking of words in terms of distance. For instance, the distance between a prompt and a document. This idea of distance is what we’ll use to retrieve relevant documents.
Using Word Embeddings For Retrieval
We know how to turn words into a point in some high dimensional space. How can we use those to know which documents are relevant to a given prompt? There’s a lot of ways this can be done, it’s still an active point of research, but we’ll consider a simple yet powerful approach; the manhattan distance of the mean vector embedding.
The Mean Vector Embedding
We have a prompt which can be thought of as a list of words, and we have documents which can also be thought of as lists of words. We can summarize these lists of words by first embedding each word with Word2Vect, then we can calculate the average of all of the embeddings.

Conceptually, because the word vector encodes the meaning of a word, the mean vector embedding calculates the average meaning of the entire phrase.

Manhattan Distance
Now that we’ve created a system which can summarize the meaning of a sequence of words down to a single vector, we can use this vector to compare how similar two sequences of words are. In this example, we’ll use the manhattan distance, though many other distance measurements can be used.

Combining these two concepts together, we can find the mean vector embedding of the prompt, and all documents, and use the manhattan distance to sort the documents in terms of distance, a proxy for relatedness.

And that’s the essence of retrieval; you calculate a word vector embedding for all words in all pieces of text, then compute an mean vector which represents each piece of text. We can then use the manhattan distance as a proxy for similarity.
In terms of actually deciding which documents to use, there’s a lot of options. You could set a maximum distance threshold, in which any larger distance would count as irrelevant, or you could always include the document with the minimum distance. The exact details depend on the needs of the application. To keep things simple we’ll always retrieve the document with the lowest distance to the prompt.
A Note on Vector Databases
Before I move onto augmentation and generation, a note.
In this article I wanted to focus on the concepts of RAG without going through the specifics of vector data bases. They’re a fascinating and incredibly powerful technology which I’ll be building from scratch in a future post. If you’re implementing RAG in a project, you’ll probably want to use a vector database to achieve better query performance when calculating the distance between a prompt and large number of documents. Here’s a few options you might be interested in:
typically RAG is achieved by hooking up one of these databases with LangChain, a workflow I’m planning on tackling in another future post.
Augmentation and Generation
Cool, so we’re able to retrieve which documents are relevant to a users prompt. How do we actually use them? This can be done with a prompt formatted to the specific application. For instance, we can declare the following format:
"Answer the customers prompt based on the folowing context:
==== context: {document title} ====
{document content}
...
prompt: {prompt}"This format can then be used, along with whichever document was deemed useful, to augment the prompt. This augmented prompt can then be passed directly to the LLM to generate the final output.
RAG From Scratch
We’ve covered the theory; retrieval, augmentation, and generation. In order to further our understanding, we’ll implement RAG more or less from scratch. We’ll use a pre-trained word vector embedder and LLM, but we’ll do distance calculation and augmentation ourselves.
you can find the full code here:
Keep reading with a 7-day free trial
Subscribe to Intuitively and Exhaustively Explained to keep reading this post and get 7 days of free access to the full post archives.