
Speculative Sampling — Intuitively and Exhaustively Explained
Exploring the drop-in strategy for making language models 3x faster


In this article we’ll discuss “Speculative Sampling”, a strategy that makes text generation faster and more affordable without compromising on performance. In doing so, we’ll take a thorough look at some of the more subtle aspects of language models.

First we’ll discuss a major problem that’s slowing down modern language models, then we’ll build an intuitive understanding of how speculative sampling elegantly speeds them up, then we’ll implement speculative sampling from scratch in Python.
Who is this useful for? Anyone interested in natural language processing (NLP), or cutting edge AI advancements.
How advanced is this post? The concepts in this article are accessible to machine learning enthusiasts, and are cutting edge enough to interest seasoned data scientists. The code at the end may be useful to developers.
Pre-requisites: It might be useful to have a cursory understanding of Transformers, OpenAI’s GPT models, or both. If you find yourself confused, you can refer to either of these articles:


Language Models Are Getting Too Big
Over the last four years OpenAI’s GPT models have grown from 117 million parameters in 2018 to an estimated 1.8 Trillion parameters in 2023. This rapid growth can largely be attributed to the fact that, in language modeling, bigger is better.

As a result, the last few years have been an arms race. Numerous companies have been dropping billions of dollars on fancy graphics cards to the schagrin of Fortnite players everywhere.
The issue is, the models are simply getting too big. Language models, like the ones used in ChatGPT, have to generate their responses one word at a time through a process called “autoregressive generation”. The bigger the model gets, the more money and time it takes to generate output word by word.

OpenAI’s GPT-4, based on a leak by some guy on twitter, uses a bunch of technologies to get around this problem. One of them, the topic of this article, is speculative sampling.
Speculative Sampling in a Nutshell
Speculative sampling (also known as “Speculative Decoding” or “Speculative Generation”) was simultaneously proposed in two papers, both of which suggest a speedup in text generation by around 3x:
“Accelerating Large Language Model Decoding with Speculative Sampling”, a paper by DeepMind,
“Fast Inference from Transformers via Speculative Decoding”, a paper by Google.
Despite being published independently, both approaches are functionally identical, so we’ll treat them synonymously.
The fundamental idea of speculative sampling is that bigger language models are better because some examples of text generation are difficult, but not all examples. For instance, suppose you ask a language model about the geological composition of the moon. To formulate a coherent response the model has to understand fancy sciency stuff, and also has to put words like “a”, “and”, and “of” in the right spots. Knowing the moon consists of something called “Breccias” is more difficult than knowing the word “are” might come after the word “which”.

Speculative sampling exploits the idea of varying degrees of difficulty by using two language models; a target model and a draft model:
The target model is the super big, super smart model we’re trying to speed up.
The draft model is a smaller, dumber, and faster model.
The idea is to use the draft model to predict numerous words in the sequence, then ask the target model to confirm that all the generated words are good. We can throw away all disagreements, resulting in an output which is identical to what the target model would output if it was working alone.

A Natural Question
If you’re anything like me, you might be a bit confused. The common intuition, and the intuition that I communicated in both my article on transformers and my article on GPT, is that language models predict output word by word. Under that intuition it’s not exactly obvious how a target model might efficiently “double check” the output of the draft model; if the target model has to check predictions one by one, then what’s the point of going through the trouble of using the draft model in the first place?

The idea of speculative sampling requires a thorough understanding of the exact output of transformers. There are some quirks which normally aren’t relevant, but are very relevant for speculative sampling.
The Secret Outputs of Transformers, and How Speculative Sampling Uses Them
As I discussed in my article on the original transformer architecture, the thing that made transformers so special was their ability to parallelize training. Before transformers, models like LSTMs had to be trained word by word, which was a slow and expensive process.
When a model like GPT is trained, an entire input sequence is provided at input, and the model is asked to predict that same sequence, just shifted by one word. The model is then trained to minimize the flaws of its predictions.
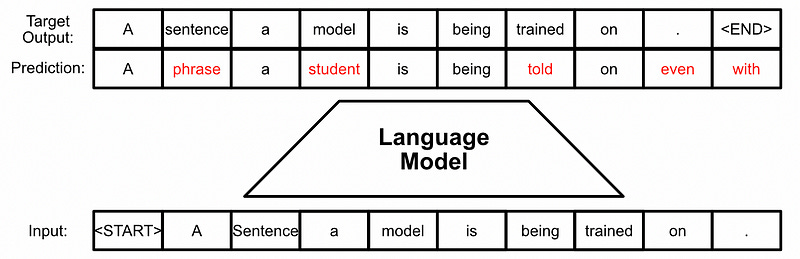
So, if the model has access to the entire input sequence, wouldn’t it cheat by just moving each word over by one space? No, and that’s because of masking.
Transformers use “masked” self attention, which essentially blocks out information about future words from reaching the information for a given word. I’ll probably cover masking in it’s own dedicated article, it’s definitely worthy of a deeper dive, but the intuition is this: By setting certain values in the self attention mechanism to zero, the prediction of a given word is not influenced by future words.

Typically, when using a transformer, we only care about a prediction of the next word in a sequence; that’s how we get text to generate and cause venture capitalists to empty their pockets. However, technically, the model has outputs for the entire sequence as if the next words in the sequence did not exist, because of the way the model is trained.

And that’s how the target model can quickly check numerous predictions from the draft model. If we give the draft models output to the target model as input, and ask the target model to predict the next word, we can compare the predicted values for every word in the sequence. If there’s a discrepancy we can stop there and use the target model’s output.

A cool note about this process generally. Every single time we run the target model, it predicts the next word in the sequence. The target model might confirm all of the predictions of the draft model, or it disagree with all of them. Regardless, the target model will always predict a new word. As a result, in a worst case scenario where the draft model consistently outputs incorrect information, the entire system is as fast as if we were only using the target model. In other words, speculative sampling can’t slow down generation, it can only make generation faster (at least, when it’s implemented correctly).
Sequences, Tokens, TokenIds, Logits, and Probabilities
That was the theory. Before we dive into the code we should discuss some technical details about how transformers function.
Text, from a language modeling perspective, is conceptualized as a sequence; a list of “things” that come one after another. Typically these “things” can be conceptualized as words, but in reality they’re a bit more abstract than that.
A machine learning model first breaks the input sequence into tokens, which are the “things” that make up a sequence. This can be done using one of many algorithms, but the end result is that the input sequence is divided into atomic chunks. These might be individual words, portions of words, multiple words, punctuation, numbers, or spaces.

Each of the tokens extracted from a tokenizer has a unique number, called the TokenId. Typically, a transformer style model learns a representative vector for each TokenId, which then becomes the input to the model. There’s one vector associated with each TokenId, which the model optimizes throughout training.

After the data goes through numerous rounds of self attention within the model, the data becomes an abstract sequence of vectors, one for each output. This is sometimes referred to as the “final hidden state”.

This is passed through a language modeling head, which converts the model’s abstract representation into a representation that corresponds directly to the tokenizer. There’s a set number of TokenIds for a given tokenizer, and the language modeling head converts the output of the model into vectors which contain the same number of values.
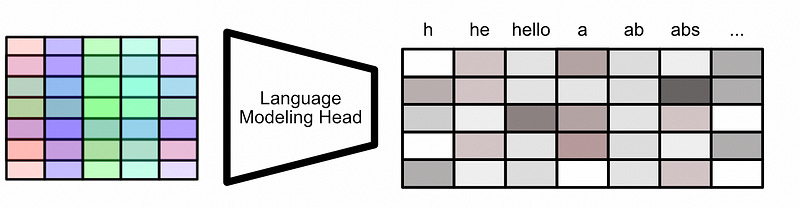
These outputs are called logits. Typically, the term “logit” is used to refer to the unfiltered, unprocessed, true output of the model. This is the thing that usually gets optimized. logits are typically compared to each other using a softmax function, which converts the logits into probabilities. Big logit values become big probabilities, small logit values become small probabilities.

These probabilities can then be converted into tokens, which then can be used to construct the output sequence. There are a few ways to go about doing that though.
You can simply always choose to use the highest probability token
You could randomly select an output in a manner which is weighted by probability
You could do a more complex strategy like “top K sampling”.
Regardless, the probabilities become a tokenId, that tokenId becomes the token itself, and from the tokens, the output can be constructed.
So, to recap:
Sequence: This is typically used in reference to the input and output text, but can also be conceptualized as a sequence of tokens, sequence of tokenIds, sequence of logits, sequence of probabilities, whatever. “The sequence” can mean a few things, depending on the context of the discussion
Token: Text can be divided into atomic tokens with a tokenizer. These are used to break text up into atomic, predefined chunks. Sometimes these cleanly correspond to words, and sometimes they don’t.
TokenId: Each token has a corresponding TokenId, which is simply a number. The model uses this number to retrieve a learned vector for that token, thus constructing the input to the model
Logits and Probabilities: After the model does its thing, it outputs a series of values. These are typically softmaxed, and thus turned into probabilities. The probabilities are used to select output tokens.
Speculative Sampling in PyTorch
Now that we understand logits, probabilities, and tokens, we can start diving into a practical example of Speculative Sampling.
Let’s keep it simple: We’ll use the maximum logit to decide which token gets generated on each step. If both the draft and target models output the same max value, we’ll say they agree.
Full code can be found here.
Loading the Models
First, we need a draft and a target model. I’m using T5 in this example, which stands for “Text to Text Transfer Transformer”. It’s an encoder-decoder style transformer (like the one I talk about in this article), which differs from a decoder only model (like the one I talk about in this article). Regardless, it has a decoder, so it will work for our purposes. Also, conveniently, T5 comes in a variety of sizes, pre-trained, and easily available on huggingface.
"""Loading the draft model
"""
from transformers import T5Tokenizer, T5ForConditionalGeneration
#loading the draft model
draft = "google/flan-t5-large"
draft_tokenizer = T5Tokenizer.from_pretrained(draft)
draft_model = T5ForConditionalGeneration.from_pretrained(draft)"""Loading the target model
"""
#loading the target model
target = "google/flan-t5-xl"
target_tokenizer = T5Tokenizer.from_pretrained(target)
target_model = T5ForConditionalGeneration.from_pretrained(target)The whole idea of speculative decoding relies on the draft and target model having the same tokens. So, just to double check, I confirmed that the tokenizers for both models behaved similarly.
"""Ensuring the tokenizers are identical
in order for speculative sampling to work, tokenization for both the draft
and target model must be identical. This is a sanity check to make sure they are.
"""
#tokenizing a test sequence
tokenizer_test = "this, is, some [text] for 1234comparing, tokenizers adoihayyuz"
ex1 = target_tokenizer(prompt, return_tensors="pt").input_ids
ex2 = draft_tokenizer(prompt, return_tensors="pt").input_ids
#zero means all tokenized values are the same, so the tokenizers are
#more than likely identical
print((ex1-ex2).abs().max())
Building Speculative Sampling
Once you have the models, you just, kinda.. do speculative sampling. Of course, as previously mentioned, to do speculative sampling productively you need a whole architecture that can handle parallelized cues of information. In this example I’m simply doing drafting and checking within the same loop on a single machine. It’s not a very complicated process, but there are some loops and logic that need to happen to get it all working. Here’s the code:
"""Performing Speculative Sampling
"""
#initializing an empty input to feed to the decoder.
#this is updated each loop with valid generations
decoder_ids = draft_model._shift_right(draft_tokenizer("", return_tensors="pt").input_ids)
#defining input. T5 is an encoder-decoder model, so input and output are handled seperatly
input_ids = draft_tokenizer("Translate to German \n Battle not with monsters, lest ye become a monster, and if you gaze into the abyss, the abyss gazes also into you.", return_tensors="pt").input_ids
#defining the number of draft generations
k = 5
#keeps track of generation information, for later printouts
generated = []
#Generating Text
iter = 0
for _ in range(15):
print('========== Speculative Sampling Iteration {} =========='.format(iter))
iter+=1
#creating a holding place for the generated draft
decoder_ids_draft = decoder_ids.clone()
before_text = draft_tokenizer.decode(decoder_ids_draft[0])
initial_length = decoder_ids.shape[1]
#generating draft
for i in range(k):
#predicting the next token with the draft model
with torch.no_grad():
logits = draft_model(input_ids=input_ids, decoder_input_ids=decoder_ids_draft).logits
genid = torch.argmax(logits, dim=2)[0][-1]
#appending the generated id to the draft
genid = genid.expand(1,1)
decoder_ids_draft = torch.cat((decoder_ids_draft,genid),1)
print('=== Draft Generation')
current_draft = draft_tokenizer.decode(decoder_ids_draft[0])
print('generated draft tokens: {}'.format(decoder_ids_draft))
print('generated draft text: {}'.format(current_draft))
#Generating all next token predictions with the target
logits = target_model(input_ids=input_ids, decoder_input_ids=decoder_ids_draft).logits
genids = torch.argmax(logits, dim=2)[0]
print('=== Target Generation')
current_target = draft_tokenizer.decode(genids)
print('generated target tokens: {}'.format(genids))
print('generated target text: {}'.format(current_target))
#checking draft against target
for i, (dv, tv) in enumerate(zip(decoder_ids_draft[0,1:],genids[:-1])):
#target does not agree with the draft
if dv != tv:
#genids is next word, so this is done to preserve the first token
first_token = decoder_ids[0][:1]
decoder_ids = genids[:i+1]
decoder_ids = torch.cat((first_token,decoder_ids),0)
break
else:
#no disagreements
decoder_ids = genids
print('=== Validated Generation')
current_target = draft_tokenizer.decode(decoder_ids)
print('generated target tokens: {}'.format(decoder_ids))
print('generated target text: {}'.format(current_target))
#expanding dimensions so that the shape of the tensor is the same
decoder_ids = decoder_ids.expand(1,len(decoder_ids))
#logging
numgen = decoder_ids.shape[1] - initial_length
generated.append({'tokens generated': numgen, 'text before': before_text, 'text after': current_target})Once concluded, we can observe how many tokens were generated in each loop. In this example we’re asking the model to translate a famous quote from English to German:

As you can see, with the chosen task and models, most iterations did not have useful draft output. In some examples however, like 8 and 11, the draft model allowed the system to effectively generate five tokens in one run of the target model. The models used in this example are fairly small. I imagine, when dealing with larger models, the draft model would be more useful more often.
Conclusion
And that’s it. Speculative sampling is an incredibly elegant way to drastically speed up text generation. We use a small language model to quickly generate output, then (by using a quirk of masked attention during training) we can use a large language model to double check that work essentially for free. We only keep generated text that the larger model agrees with, so at the end we get the same output, only faster.
Attribution: All of the images in this document were created by Daniel Warfield, unless a source is otherwise provided. You can use any images in this post for your own non-commercial purposes, so long as you reference this article, https://danielwarfield.dev, or both.
i like the article. Nonetheless, I must have a misconception. If the method depends on the draft token being checked against the target token, where is the speed gain? Thanks again for your insight.
>