


Dropout — Intuitively and Exhaustively Explained
Encouraging robust learning in AI


“Dropout” is a fundamental approach that involves randomly deactivating components of an AI model throughout the training process. As we’ll discuss, this random deactivation of elements can drastically improve the performance of AI models, which is why it’s featured in the training process of virtually all cutting-edge AI.
We’ll begin our exploration of dropout by reviewing how neural networks are trained. Once we do that, we’ll discuss how dropout can be applied to the training process and how it can lead to more generalized learning in AI systems. After we’ve formed a thorough conceptual understanding of dropout, we’ll go through an example using PyTorch.
Who is this useful for? Anyone who wants to form a complete understanding of the state of the art of AI, especially those interested in training AI models.
How advanced is this post? This article is great for beginners and serves as a good refresher for more experienced data scientists.
Pre-requisites: None
A Brief Review of the Neural Network
The following is a brief summarization from my article on neural networks

Neural networks take direct inspiration from the human brain, which is made up of billions of incredibly complex cells called neurons.

When we use certain neurons more frequently, their connections become stronger. When we don’t use certain neurons, those connections weaken. This general rule has inspired the phrase “Neurons that fire together, wire together” and is the high-level quality of the brain that is responsible for the learning process.

Neural networks are, essentially, a mathematically convenient and simplified version of neurons within the brain. A neural network is made up of elements called “perceptrons”, which are directly inspired by neurons.

A neural network can be conceptualized as a big network of these perceptrons, just like the brain is a big network of neurons.

One of the fundamental ideas of AI is that you can “train” a model. This is done by asking a neural network (which starts its life as a big pile of random data) to do some task. Then, you somehow update the model based on how the model’s output compares to a known good answer.

This happens via a process called back propagation. You feed some input into the model and observe how the model's output deviates from the expected output.

You then look backward through the model and adjust each parameter a tiny bit so that the desired output is more likely.

The training process, then, is an iterative process of feeding large amounts of data through an AI model, calculating how different the output is from a desired answer, and adjusting the parameters of the model accordingly.
If you want to understand this process in depth, feel free to check out my article on neural networks. For our purposes, though, there’s one important detail I would like to discuss.
Because of how the training process works out mathematically, when two perceptrons “fire” together (have an output greater than zero), they are updated together. This is somewhat similar to the idea that “Neurons that fire together wire together” within the human brain.

A single perceptron is an incredibly simple learner, but a large cluster of them can learn to interact with each other in such a way that incredibly complex inferences can be made. This is chiefly the result of certain perceptrons learning to, or not to, fire together.
This is great, but it has some pitfalls when applying neural networks to real-world problems.
Have any questions about this article? Join the IAEE Discord.
Over Fitting
Over-fitting is possibly the most fundamental problem in artificial intelligence and is essentially the reason why dropout exists. Recall that when you train a model, you update that model based on some example training data.
Let’s say we have a few pictures of cats and dogs, and we want to use them to train a model to be able to distinguish between cats and dogs.

The question is, how thoroughly do we want our model to learn from this dataset? That might sound like a silly question, but it’s one of great profundity where AI is concerned. One way our model could learn to distinguish between these photos is by learning the macroscopic features of cats and dogs, which is great.

Another way our model could learn to distinguish cats from dogs is by looking at the top left pixel and memorizing which color is from a dog or a cat photo.

The model's job is to learn which image is of a cat or a dog. Nothing more and nothing less. Memorizing which top left pixel color corresponds to a cat or a dog could result in a high level of accuracy when applying our model to our training data, so it’s a perfectly valid approach as far as our model is concerned.
When a model that learns features like this is applied to new problems, however, we’d likely have some problems.

This is why, when training an AI model, data scientists often employ a “holdout set”. This is a set of data that the model is not trained on and thus can be used to evaluate how well an AI model can generalize to data it’s never seen before.

Often, when training an AI model, the model will initially get better at both the training set and the hold-out set as the model learns fundamental aspects of the problem it’s being trained on. However, as the AI model looks at the training data more and more, it might begin to over-memorize the training data, which causes a reduction in performance of the holdout set.
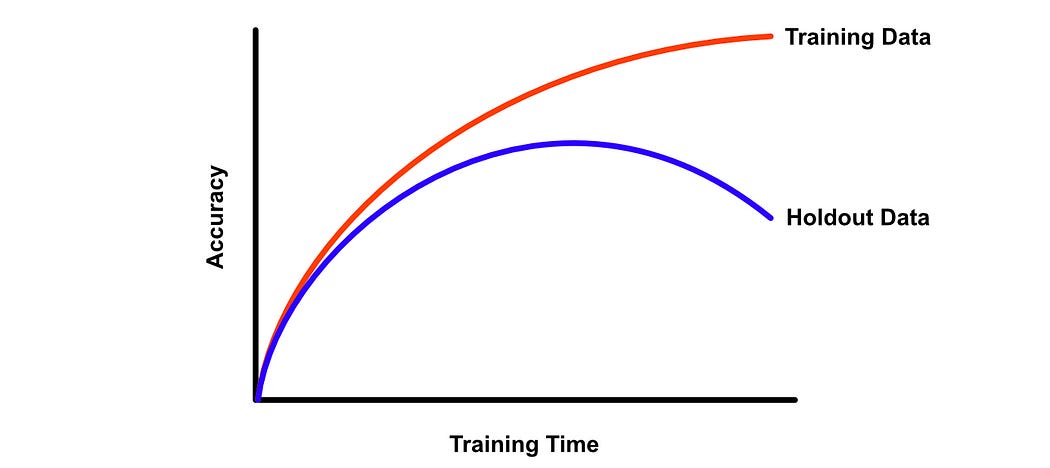
When a model begins to memorize the training data rather than learn about the underlying problem, we call that “over-fitting”. There are a lot of ways to deal with overfitting, but one of them is dropout.
Dropout
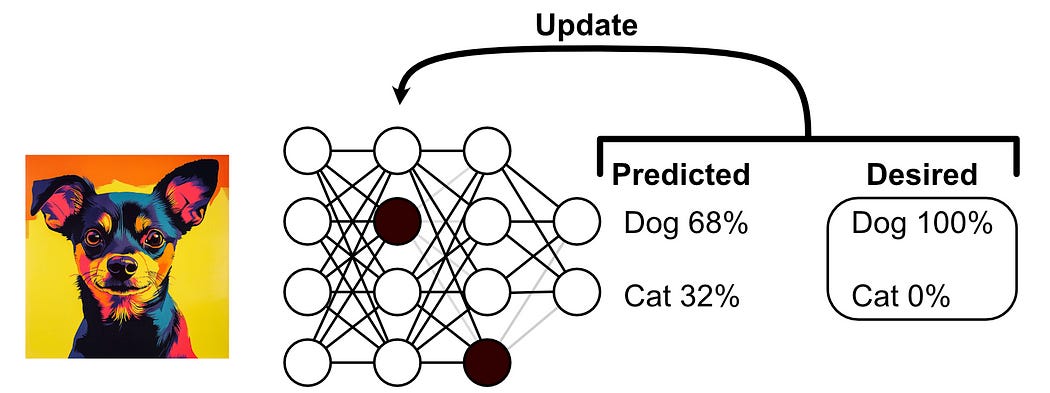
The idea of dropout is to randomly turn off neurons throughout a neural network during the training process. Recall that when training a neural network, we have a forward pass, which results in a prediction, and a backward pass, where we update the model based on how that prediction compares to a desired result.
When doing this process with dropout, you randomly deactivate a small, random subset of perceptrons. You then update the output of that model based on how the expected output deviates from the desired output.
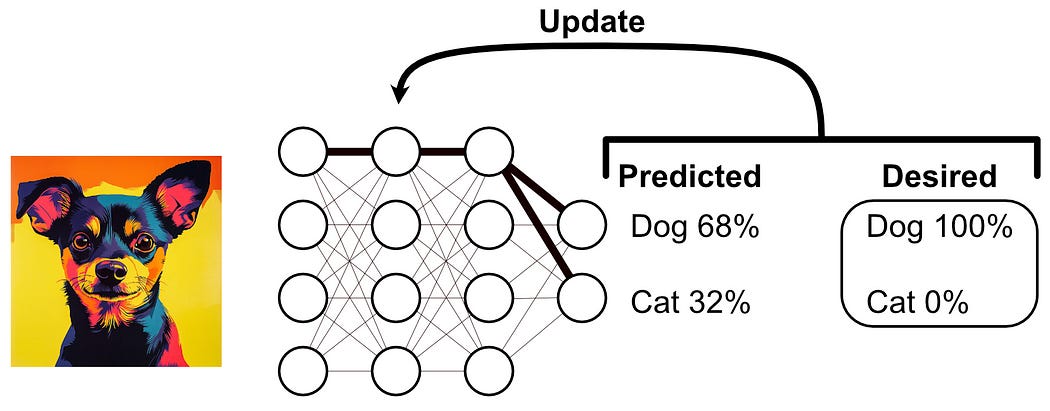
When you train a model, you feed it data over and over again in a loop. In dropout, you randomly deactivate different perceptrons in the neural network at every iteration.

This approach of randomly deactivating data has proven to be a fundamental approach when training complex AI systems, and I think there are some intuitive reasons why. Here are three potential explanations:
Why Dropout Works 1) Reduced Co-Adaptation
As previously mentioned, when training a neural network, perceptrons that fire together tend to update together. This can cause a feedback loop where certain neurons that fired together update together and, thus, are more likely to fire together in the next training iteration.
Once a certain group of perceptrons in a neural network has been sufficiently updated together, it can be very hard for the training process to break up that group of neurons. This can be good because neurons firing together is a big part of neural network learning, but it’s easy for this phenomenon to result in a sub-optimal rut that is hard to train the model out of.
If we randomly deactivate a few of the neurons in these clusters throughout the training process, it can allow new forms of learning to emerge.
Why Dropout Works 2) Redundant Representations
Imagine you had a pretty good set of neurons that magically wire together to correctly predict if the dog was a dog 90% of the time.
Throughout training, it might be difficult for the model to learn some other representation of a dog because learning that representation might somehow damage the super good one we’re relying on. When you train with dropout, every once in a while, you’ll turn off a very important section of the model, forcing the model to consider how the remaining perceptrons can be used to solve the problem.

This has the effect of encouraging multiple, slightly different representations of the problem within the neural network, allowing the model to still perform well when the odd perceptron is deactivated.
This is essentially the same as the idea of reduced co-adaptation, but in my mind, “reduced-coadaptation” applies to breaking the model out of a rut, whle “redundent representations” applies to thinking of the model as many small learners working together within the model. This is purely conceptual, though, so feel free to reflect and build your own intuition.
Why Dropout Works 3) Noise
A simple but fundamental characteristic of dropout is that it’s random. The model has no way of knowing which neurons will deactivate. As a result, if you feed the same image multiple times, each instance of feeding the image into the model can look very different to the neural network.
This makes it harder for the neural network to rely on simplistic memorization because there is a fundamental randomness in the training process. Thus, the model is forced to learn more general characteristics of the problem.
Using Dropout in PyTorch
If you’re unfamiliar with PyTorch, I have an article that covers the subject in depth. The implementation section of this article will assume basic PyTorch knowledge:

{kind=link}
{kind=link}
{kind=link}
Full code can be found here:
Let’s define a toy problem for us to play with. Here, I’m defining a function that takes in two inputs and results in a single output.
Keep reading with a 7-day free trial
Subscribe to Intuitively and Exhaustively Explained to keep reading this post and get 7 days of free access to the full post archives.