
AI for the Absolute Novice — Intuitively and Exhaustively Explained
From “I’ve never coded” to making an AI model from scratch


In this article we’ll build an AI model, the same way the pros do, assuming no prior knowledge. This article does not assume any software development experience, at all, whatsoever.
We’ll start by setting up an environment where we can run code, then we’ll learn basic Python, and go through a few practice problems as we learn. Once we have a solid foundation in Python, we’ll learn the basics of PyTorch, a popular tool in Python used to develop AI models. Finally, we’ll use PyTorch to train a neural network to understand images.
Who is this useful for? Anyone who wants to start learning to make AI models, or wants to understand the topic of data science deeply.
How advanced is this post? This article is tailor-made for absolute beginners and may be useful for both beginners and novices.
Pre-requisites: None.
The Basic Theory of AI
AI, data science, machine learning; these are all incredibly broad terms which include a vast number of concepts. In this article we’ll conceptualize AI as training a computer system to solve a problem by looking at examples of the problem being solved. This process is called training.

Once an AI model has been trained, we’ll use that AI model to make predictions.

And that’s what we’ll be doing in this tutorial. Before we get into the AI stuff, though, we need to set up an environment so we can start running code.
Setting Up a Coding Environment
Both novices and pros alike use Google Colab to develop AI models. If you already have a Google account, you can set up Google Colab easily. First, click this link. This will open something called a “Colab Notebook”:

Colab Notebooks are where we’ll be doing all of our coding for the rest of the article. If the window labeled “Open Notebook” doesn’t appear for you, you can open it by going to “file” and selecting “open notebook”

If the “open notebook” window is not open, you can access it via “File” > “Open notebook”
With the “Open Notebook” window up, click “New Notebook” on the bottom left.
When you do this, Google Collab will create a new notebook.
It will also add a new folder to your Google Drive, called “Colab Notebooks”, which will contain the notebook you just created.

Basically, Google Colab is like Google Sheets, Google Slides, or other products within the greater G-Suite offering. By creating a new notebook you essentially add Google Colab to your bag of tricks in Google Drive. You’ll notice, now that you’ve made a notebook, you can make another notebook by right clicking in your google drive, selecting “more”, then selecting “Google Colaboratory”.

We’ve already created a notebook, which is currently titled “Untitiled0.ipynb” and is in “My Drive > Colab Notebooks”. We’ll use that to get an idea of how colab works. If you can’t find it, you should be able to just create a new notebook and follow along.
An Introduction to Google Colab

Here we are, in our first Colab Notebook. First of all, let’s change the name. You can do that by selecting the name in the top left and editing it. I’ll call this “My First Notebook”. This name change will be reflected in Google Drive as well.

When you’re doing stuff in Google Colab, you’re not actually running code on your computer. Rather, you’re defining the code on your computer and you’re sending that code to a computer on the cloud so it can run your code. This is what’s called a “runtime”, a “runtime” being a computer allocated, right now, to run your code. When using Colab for the first time, the first big step is to press “Connect” on the top right. When you do that, the “Connect” button will disappear and a little widget with graphs will pop up.

If you click those little graphs a side panel will come up.

The two graphs are the RAM and the disk space of the computer you’re currently connected to for your runtime. Because you don’t have a paid Google Colab subscription you only have access to tiny computers, and you might lose access to it if there are a lot of users on, but it should be good enough to get started. Press “X” next to “Resources” to get rid of the side panel.
now that we’re connected to a runtime we can start playing around with writing Python code. We can do that by clicking in the box that says “start coding” and type out some code. If we press the play button we’ll get a result.

We just edited something called a “Code Cell”. A code cell is a block which we can use to write and run code. If you hover your mouse just below the center of the code cell, you can create a new code cell. (or you can select “Insert” in the menu and click “Code Cell”).

Once we’ve created a new code cell, we can write and run a different block of code.

Data science is a highly experimentative discipline, so documentation is very important. We can write notes, thoughts, and descriptions about what’s going on using a text cell.

Text cells allow you to write text in a style called markdown. Markdown is essentially a very simple programming language for writing documents that contain headers, images, and other stuff. Markdown is super useful to know, but we won't mess with it in this article.

Take another look at the “Welcome to Colab” notebook we opened previously. As you can see, Colab allows for rich documentation interwoven between code blocks, which is why the platform is so popular for building AI models and other data science stuff.

Ok, now that we know the basics of Colab, we can start learning Python.
An Introduction to Python
Python is an incredibly popular and powerful programming language with a rich set of features and massive community. We certainly won’t be covering all of Python’s functionality in a single article. However, we will be covering all the fundamentals we need to build our first AI model.
First, we’ll go through a bunch of Python concepts, then we’ll go through a few practice problems to explore those concepts more in depth. Once we have a grasp of the fundamentals, we’ll move onto implementing AI.
Comments
In python you can write arbitrary text which is ignored by the programming language in the form of a “comment”. Comments are useful because it allows you to explain, in plain English, what’s going on in your code.

I’ll be using comments regularly to describe what’s going on in the code.
Variables
Variables are the most fundamental idea in pretty much any programming language, including Python. They’re used to store data within a program, and are written like so:
var = 3If we stick that in a code cell, then print what var is, we’ll see that the code cell prints out 3

In this case var is a variable that stores the value 3 . We can make more variables, and then add them together for instance:
var1 = 1
var2 = 17
print(var1+var2)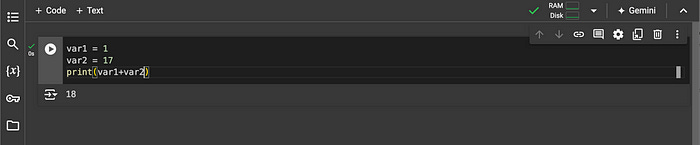
In this case we’re only using integers, but variables can hold a diversity of different types of information, which we’ll cover in the following sections.
Data Types: Integers
We’ve already touched on one data type, the Integer . This is a whole number like 1 or -27 for instance.

Data Types: Strings
Another common data type is the String . This data type represents a “string of characters” (a.k.a. text). A string can be defined by wrapping text either in quotes (””) or apostrophes ('').

Data Types: Floats
Floats are kind of like Integers, but instead of whole numbers they can be decimal numbers as well. They’re defined with a . somewhere in the number.

Note: now that we’re hopefully getting comfortable with the concept of code blocks, I’ll be writing the code blocks in the article itself rather than using a bunch of unnecessary screenshots. I’ll still provide screenshots when they’re necessary.
Data Types: Lists
Lists are a bit more complex than all the other data types discussed. Basically, instead of being one thing, a list is a list of things. You can create a list of integers:
list_of_ints = [1,2,3,10,20,30]A list of strings:
list_of_strings = ['string 1', 'string 2', 'another string!']even a list of lists
list_of_lists = [[1,2,3], [4,5,6], [7,8,9]]Lists unlock a bunch of exciting workflows in Python. For one, you can do something called “iteration”. You can iterate over every element in a list and do something with it:
list_of_numbers = [1, 2, 3]
for num in list_of_numbers:
print(num+10)
you can also get specific values out of a list by “indexing”. You use a square bracket notation ([]) to extract a certain item from the list. One quirk that trips up a lot of new developers is that, in computers, we start counting at zero rather than one.
list_of_numbers = [10, 20, 30]
print('value at index 0:')
print(list_of_numbers[0])
print('------')
print('value at index 2:')
print(list_of_numbers[2])
Indexing and iteration allow for incredibly complex functionality, which we’ll explore later in the article.
Functions
It’s common to create some block of code which does something important, then want to reuse that code many times. As a very simple example, imagine you were coding something with blocks, and you kept needing to calculate the volume of those blocks.
# several blocks (rectangular prisms), expressed as a list with
# [length, width, height]
block1 = [2,3,5]
block2 = [3,6,7]
block3 = [2,9,1]
# calculating the volume of each block (length * width * height)
volume1 = block1[0] * block1[1] * block1[2]
volume2 = block2[0] * block2[1] * block2[2]
volume3 = block3[0] * block3[1] * block3[2]
In this case it might be useful to create a function which calculates the volume of a block.
#defining a function which takes in a block and outputs a volume
def calc_volume(block):
return block[0]*block[1]*block[2]
# several blocks (rectangular prisms), expressed as a list with
# [length, width, height]
block1 = [2,3,5]
block2 = [3,6,7]
block3 = [2,9,1]
# calculating the volume of each block
volume1 = calc_volume(block1)
volume2 = calc_volume(block2)
volume3 = calc_volume(block3)When creating a function, you use the keyword def to tell python you’re making a function, you then name the function (in this case calc_volume), and then specify the inputs (in this case block). The return statement specifies the output of the function.
Any time you want to define some process with code, no matter how complex, it can usually be expressed as a function with some inputs and some outputs. Functions can thus be very simple, very complex, or anywhere in between.
Classes
Classes are a way to make your own data types which contain certain data and functionality. Formally, in computer science, this is called object-oriented programming.
Instead of defining blocks as lists, we can create a class Block which explicitly requests a length, width, and height.
class Block:
def __init__(self, length, width, height):
self.length = length
self.width = width
self.height = heightThis defines a class called Block . In this case, the class Block contains a function within it called __init__ . __init__ is a special function which specifies how a new Block gets created (called an “initialization” function). When we want to create a new Block, we need to tell that new Block what it’s width, length, and height are. This function then saves that data in the new Block that’s been created. The keyword self is used to represent the specific block being created. Don’t worry about understanding this perfectly right now, this should start to make more sense in a bit.
Once we’ve implemented this class we can create “instances” of that class, essentially turning the abstract blueprint of a Block into several specific examples of blocks.
class Block:
def __init__(self, length, width, height):
self.length = length
self.width = width
self.height = height
# creating instances of the Block class.
block1 = Block(2,3,5)
block2 = Block(3,6,7)
block3 = Block(2,9,1)What’s cool about this general approach is that we can take our function to calculate volume and put it in the Block itself. Whenever you create a function within a class (also commonly referred to as a method) it automatically receives the self variable, which is all handled under the hood in python. We can use this to get the length, width, and height of a particular instance of Block to calculate it’s volume.
class Block:
def __init__(self, length, width, height):
self.length = length
self.width = width
self.height = height
def calc_volume(self):
return self.length * self.width * self.height
# creating instances of the Block class.
block1 = Block(2,3,5)
block2 = Block(3,6,7)
block3 = Block(2,9,1)
#calculating the volumes of each block
volume1 = block1.calc_volume()
volume2 = block2.calc_volume()
volume3 = block3.calc_volume()Feel free to experiment with this code yourself so you can get a better idea of how it works. Putting print statements at various parts of the code is usually a pretty good strategy for getting a better intuition of what’s going on. For instance, if we add the following print statements:
class Block:
def __init__(self, length, width, height):
self.length = length
self.width = width
self.height = height
print('initialized block') #<----------------------- print statement
def calc_volume(self):
print('calculating volume...') #<------------------- print statement
return self.length * self.width * self.height
print('volume calculated!') #<---------------------- print statement
# creating instances of the Block class.
block1 = Block(2,3,5)
block2 = Block(3,6,7)
block3 = Block(2,9,1)
#calculating the volumes of each block
volume1 = block1.calc_volume()
volume2 = block2.calc_volume()
volume3 = block3.calc_volume()we get the following results when we run that code block:

I invite you to reflect on this output. Every time we create a new block, the print statement for initialized block runs, hence why there are three initialized blocks. What might be unintuitive is the fact that calculating volume... is printed while volume calculated! is not. That’s because, when you call return in a function that function returns a value then stops executing the function. Because return exists before the print statement for volume calculated! , volume calculated! is never actually printed. There's all sorts of little quirks like this which you only learn by trying to code in Python yourself, so I invite you to play around with this code and see what happens.
Note the use of the . to calculate a blocks volume:
volume1 = block1.calc_volume()The . operator, in this context, essentially says “get something from this object”, in this case that’s the calc_volume function. We can also get out data in the object, like so:
block1 = Block(2,3,5)
print('block length:')
print(block1.length)
print('block width:')
print(block1.width)
print('block height:')
print(block1.height)
There’s one more topic which I want to cover before we start learning the fancy AI stuff, and that’s inheritance.
Inheritance
The idea of inheritance is, essentially, what if one class could inherit some of the functionality from another class.
For instance, what if we wanted to specify a cube, which is like a block except the length, width, and height of a cube are all the same number. We could simply use our Block class to do that:
cube = Block(10,10,10)That’s perfectly acceptable, but for more complex projects this might be a bit cumbersome. We also have the option of creating a new class Cube which inherits some of the core functionality of Block .
#the class for Block
class Block:
def __init__(self, length, width, height):
self.length = length
self.width = width
self.height = height
def calc_volume(self):
return self.length * self.width * self.height
#the class for Cube, which inherits from class Block
class Cube(Block):
def __init__(self,length):
super().__init__(length, length, length)
cube = Cube(10)
print('volume of cube with an edge length of 10:')
print(cube.calc_volume())
Here we define a class Cube(Block) , which means we’re creating a class Cube which inherits the functionality of the class Block .
As you can see, from this code, we create a class for Cube which is capable of calling the calc_volume function from Block. Under the hood Cube has a length width and height (because it inherits from Block), but instead of defining them explicitly we pass the single input length in the Cube’s __init__ function to all of the inputs in the Block’s __init__ function. We Do that with the line super().__init__(length, length, length). In this line, super means “the class this class inherits”, which is Block, .__init__ gets the initialization function from that class, and (length, length, length) passes the input length of the Cube to length, width, and height of the Blocks initialization function.
This might seem like a lot, and it is. Luckily you don’t need to be an expert on inheritance, you just need to understand the core concept to start experimenting with AI in Python. As long as you understand that a class can inherit functionality from another class, you’re good.
Ok, we’ve covered the most important fundamentals of Python for our purposes. Let’s go over a few practice problems to lock it in, then start playing around with AI.
Python Practice Problems
Take a look at the following code cells and try to guess what the output will be. Then, run the code cells yourself and review what’s going on. If you don’t understand a problem stick the code cell in ChatGPT, tell ChatGPT you’re a beginner, and ask it to describe the code cell.
Problem 1
What is the output of the following code?
var1 = 3
var2 = 7 + var1
print(var)Problem 2
What is the output of the following code?
arr = [1,2,3,4,5]
print(arr[2])Problem 3
What is the output of the following code?
class Printer:
def __init__(self, number):
self.number = number + 1
print('number set!')
def print(self):
print('the number is:')
print(self.number)
p = Printer(3)
p.print()Problem 4
What is the output of the following code?
vals = [0,1,2,3,4]
for v in vals:
print(v+10)Problem 5
What is the output of the following code? Hint: Think like a computer, and take it line by line from top to bottom, and character by character from left to right.
matrix = [[0,1,2],[3,4,5],[6,7,8]]
print(matrix[1][2])Problem 6
What is the output of the following code block? Hint: When you’re calling multiple functions at the same time, start with thinking from the innermost function to the outermost function.
def func1(value):
return value+3
def func2(value):
return value/3
print(func1(func2(10)))Problem 7
What is the output of the following code block? Hint: Note how this problem has an equivalent output to the previous problem.
def func1(value):
return value+3
def func2(value):
return value/3
value = func2(10)
value = func1(value)
print(value)Libraries in Python, and an introduction to PyTorch
A library in Python is a collection of various classes and functions which are all designed to work together to do something. There are libraries which allow you to plot things, communicate over the internet, and all sorts of other fancy stuff. In this article we’ll be using a library called PyTorch to make an AI model.
Google Colab already has PyTorch installed, so we can use PyTorch by simply running the following code:
import torchProbably the most fundamental thing in PyTorch to understand to start playing with AI is the “tensor”.
PyTorch Concept 1: Tensors
Here’s an example of a tensor being created.
import torch
tensor = torch.tensor([[1.0, -1.0], [2.9, -3.1]])
print(tensor)
A tensor is a block of numbers in some dimension. You could have a 0-dimension tensor (just a single number):
# making a 0D tensor
tensor = torch.tensor(42)
print(tensor)
A 1-dimension tensor (aka. a vector, or list):
# making a 1D tensor
tensor = torch.tensor([1,2,3,4,5])
print(tensor)
A 2-dimension tensor (aka. a matrix):
# making a 2D tensor
tensor = torch.tensor([[1.0, -1.0], [2.9, -3.1]])
print(tensor)A 3-dimensional tensor:
# making a 2D tensor
tensor = torch.tensor([[[1, 2], [3, 4]], [[5, 6], [7, 8]]])
print(tensor)
And so on and so forth. Tensors can be arbitrarily large and have an arbitrary number of dimensions. A common thing to do when dealing with tensors is to find out how many dimensions they have, and how large each of those dimensions is. we can do that by getting the shape of the tensor.
# getting the shape of a 3D tensor
tensor = torch.tensor([[[1, 2], [3, 4]], [[5, 6], [7, 8]]])
print(tensor.shape)
Tensors are used all over the place in AI. When working on a problem you turn whatever data you’re dealing with into a tensor, then the model does math on the tensor to turn it into an output, which is a tensor. The parameters in the model itself are, in fact, also tensors. Having an intuition about tensors is very valuable in understanding AI; it’s all tensors under the hood.
PyTorch Concept 2: Building AI Models
Ok, now let’s actually build a simple model. In PyTorch this is done by creating a class which represents the AI model. That class should inherit another class from PyTorch called Module
import torch
import torch.nn as nn #<- we'll be using the module `nn` within torch often
# which is why we're importing it seperatly
# Define our first AI model
class MyFirstAIModel(nn.Module):
# the implementation for our modelThis is a common approach to building AI models in PyTorch. The folks who made PyTorch have made a bunch of handy functionalities which we can take for granted by simply inheriting nn.Module. Let’s use this to make a simple neural network.
A neural network, the prototypical AI model, is a bunch of “neurons” connected with one another. these connections have weights, which are updated to change the way the model “thinks”. We’ll get more into the theory of that later, but for now let’s just try to build some random neural network in PyTorch to get an idea of how PyTorch works.

We can implement the neural network from the image above in PyTorch with the following code:
1 import torch.nn as nn
2
3 # Define the neural network
4 class MyFirstAIModel(nn.Module):
5 def __init__(self, input_size, hidden_size, output_size):
6 super(MyFirstAIModel, self).__init__()
7 self.fc1 = nn.Linear(input_size, hidden_size)
8 self.fc2 = nn.Linear(hidden_size, output_size)
9
10 def forward(self, x):
11 x = self.fc1(x)
12 x = self.fc2(x)
13 return x
14
15 model = MyFirstAIModel(3,4,2)Let’s go line by line.
Line 1: We import
torch.nn, which contains classes and functions which we can use to make an AI model.Line 4: We’re defining a new AI model as a class which inherits
nn.Modulewith the lineclass MyFirstAIModel(nn.Module):. This means our AI model inherits a bunch of functionality which we don’t have to worry about.Line 5: We’re defining the initialization function for
MyFirstAIModelwith the linedef __init__(self, input_size, hidden_size, output_size):. This is a function which takes an inputself(which is the case for all functions within a class), as well as theinput_sizeof our neural network, thehidden_size(the size of the layer in the middle), and theoutput_size. Ultimately these inputs are what define the size of our model.Line 6: Within the initialization function, we call the initialization function of the class we inherited (
nn.Module). What exactly does this line do? I have no idea, probably 99% of data scientists don’t totally know. You can look into it if you want, but the whole point of PyTorch is that you don’t have to know everything. This line sets up our AI model as an AI model by running the initialization function fornn.ModuleLine 7: In PyTorch, a layer of a neural network is called a linear layer. Here, we’re saying how many inputs the layer should have, and how many outputs the layer should have. Linear layers are also often called fully connected layers, hence the variable name
fc1.Line 8: We define the second fully connected layer
fc2.Line 10: Now that we’ve created our initialization function, we can specify how data flows through the model to achieve some output. The process of giving a model some input, and having the model generate some output, is commonly referred to as the “forward pass”. We implement the forward pass in PyTorch by specifying a
forwardfunction, which accepts some input (in this casex).Line 11: We give the input to our first layer of our neural network, and save the result as
xLine 12: We take the output of the previous layer (
x), pass it through the next layer, and then save that value asxLine 13: We return
x, thus returning the output of the entire model.Line 15: Actually creating an instance of the model, with layers consisting of 3 neurons, 4 neurons, and 2 neurons.
We can go ahead and whip up a tensor and pass it through our model to see what happens.
import torch
import torch.nn as nn
# Define the neural network
class MyFirstAIModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(MyFirstAIModel, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.fc2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
x = self.fc1(x)
x = self.fc2(x)
return x
model = MyFirstAIModel(3,4,2)
data_input = torch.tensor([1, 2, 3], dtype=torch.float32)
output = model(data_input)
print(output)
As you can see, we put in a tensor of length 3 (corresponding to the 3 inputs of our neural network) and got a tensor of length 2 (corresponding to the two outputs of the neural network). This AI model hasn’t been trained, so the parameters within the model are random, which is why we get a random output.
At this point you probably have two questions. what is grad_fn and how do we train the model? You might also still be shaky about the idea of of a neural network and how it actually works. Let’s take a break from PyTorch and take a moment to describe some of the theory behind AI.

The Theory of AI
Of course, the entire theory of AI is a pretty broad topic. We’ll keep the theory constrained to what is relevant to this article.
Let’s roll back and review the core concepts of a neural network. Under the hood a neural network can be conceptualized as spots where data gets stored, and weights which the model uses to process the input and turn it into some output.
Let’s say you were trying to predict if an image contained a dog or a cat. You might flatten the image into a vector, pass it through a neural network, and then get two values which represent if the model thinks that image is of a Dog or a Cat.
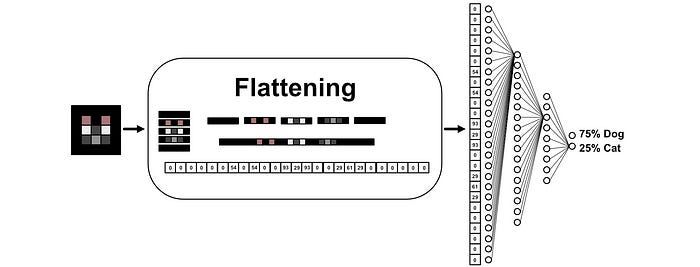
The neural network makes these predictions by using a combination of addition and multiplication. Across every connection there is a weight which the input is multiplied by. Each neuron has multiple connections, which are all added together.

When we pass data through our model there will always be some output, though the output will likely be very wrong for a new model. If we give the model an input which we know contains a dog or a cat, we can have the model predict weather it thinks it contains a dog or a cat. Then, we can use the discrepancy between what the model predicted, and what we know, to update the model to be better. This process is called training.

The way training actually gets done can be a bit complex, but the core concept is fairly simple. If the output was 20% dog, and the output should have been 100% dog, then we simply tweak the parameters of the model so the output is a little less wrong. If we do that process, over and over again, for numerous pictures of dogs and cats, then we’ll end up with a model that has learned to distinguish dogs from cats.
In the underlying math behind AI, the thing that keeps track of if a parameter should have been bigger or smaller is called a “gradient”. We won’t dive too far into gradients in this article, but I have a few articles which explore the subject if you’re curious:


One problem with our simple neural network we previously defined is that it’s linear. Recall that, back when we defined our model, we used “linear” layers from Torch.
1 import torch.nn as nn
2
3
4 class MyFirstAIModel(nn.Module):
5 def __init__(self, input_size, hidden_size, output_size):
6 super(MyFirstAIModel, self).__init__()
7 self.fc1 = nn.Linear(input_size, hidden_size) #<----Recall
8 self.fc2 = nn.Linear(hidden_size, output_size) #<----Recall
9
10 def forward(self, x):
11 x = self.fc1(x)
12 x = self.fc2(x)
13 return xIn this model each neuron’s values are calculated with simple addition and multiplication. In math speak, we say that a neuron is linearly related to the input. This is the default behavior of PyTorch’s nn.Linear layers.
This might work for some problems, but many problems in the real world cannot be modeled with simple linear relationships. To get around this, we bake non-linearity into the model using something called an “activation function”. There are a variety of activation functions, and they all have the same goal; to allow a linear model to learn non-linear relationships. Take the sigmoid activation function, for instance:

This function maps some input into an output in a nonlinear way. We can pass values within our neural network through these non-linear functions.

As the model learns throughout training, it will learn to exploit these non-linear functions in a way that makes the model better at the underlying modeling task. Even though we’re still using a model with linear relationships, those linear relationships are passed through non-linear functions, meaning the model can learn to use these nonlinear relationships to model complex things.
Ok. We understand the basics of Python, we understand a bit about PyTorch and how it works, and we have a decent understanding of the basic theory of AI. I think we’re finally ready to build a simple AI model.
Building an AI Model
First, let’s pick a toy problem to experiment with. The full code for the AI we’ll be building can be found here.
The Problem We’ll Be Solving
We’ll be building a simple model on MNIST. MNIST is the “first boss” for any fledgling data scientist. Basically, MNIST consists of thousands of images of hand drawn numbers with corresponding labels. The objective of modeling on MNIST is to predict what number any given image corresponds to.

PyTorch is a big library with a lot of stuff. To keep things clean, the folks at PyTorch decided to make a companion library called torchvision which has some utilities for visual modeling stuff. We’ll use that to download the MNIST dataset.
#Downloading the MNIST training and testing data. There's a lot of ways to
#get this data, this is just one example.
from torchvision import datasets
from torchvision.transforms import ToTensor
train_data = datasets.MNIST(
root = 'data',
train = True,
transform = ToTensor(),
download = True,
)
test_data = datasets.MNIST(
root = 'data',
train = False,
transform = ToTensor()
)The MNIST dataset is divided into two sections, the train and test sections. We’ll be training our model on the training data, then we’ll apply our model to the test data to get an idea of how good our model is at dealing with new data it’s never seen before.
train_data and test_data are a special data type called a “dataset”. For our purposes, we’ll just think of them as a tensor. Really, datasets are just tensors with some quality-of-life things built around them. We can go into our training dataset and get out the tensor that represents the image, and the tensor that represents the labels for the images, and print out their shape to get an idea of what we’re dealing with.
#printing the shape of the data.
#60,000 exampls of 28x28 images.
print(train_data.data.shape)
#60,000 labels, each one corresponding to an image.
print(train_data.targets.shape)
Here, the first tensor represents all of the images in the training set, and the second tensor represents all of the corresponding labels.
We didn’t cover matplotlib, so don’t worry about understanding the following code block completely, but we can draw a single image and print out it’s corresponding label.
#rendering a particular example
import matplotlib.pyplot as plt
i = 3
print(train_data.targets[i])
plt.imshow(train_data.data[i], cmap='gray')
plt.show()
We can do that with another example, by setting i=10 for instance…

I think you get the idea. There are 60,000 of these images and corresponding labels in the training set, and we just printed out the examples in spot 3 and spot 10. We’ll use all 60,000 of them to train our AI model.
It’s worth noting, we don’t actually have images of the numbers, we have tensors which we’re using to construct images of the numbers. Here, I’m telling PyTorch it can print out in super long lines, then printing the actual values in the tensor that represents an image.
#printing the actual tensor for an image
import torch
torch.set_printoptions(linewidth=200)
i = 10
print(train_data.data[i])
We’ll feed these numbers into the model, then expect the model to predict that this tensor represents a 3.
Building the Model
Instead of going through element by element, let’s take a look at the model as a whole, then unpack its individual elements.
from torch import nn
import torch
class MNISTModel(nn.Module):
def __init__(self):
super(MNISTModel, self).__init__()
self.fc1 = nn.Linear(784, 128)
self.activation1 = nn.ReLU()
self.fc2 = nn.Linear(128, 64)
self.activation2 = nn.ReLU()
self.fc3 = nn.Linear(64, 10)
def forward(self, x):
x = torch.flatten(x)
x = self.fc1(x)
x = self.activation1(x)
x = self.fc2(x)
x = self.activation2(x)
x = self.fc3(x)
return xThis is very similar to the model we defined previously, with a few subtle differences.
The name of the model is
MNISTModelThe model now not only has linear layers a la
nn.Linear, it also has activation functions in between the linear layers. This allows the model to learn non-linear relationships as we previously discussed. We’re using a specific activation function called “Rectified Linear Unit”, aka ReLU. You could also use Sigmoid if you wanted to.Notice how the first step of the forward pass is to flatten the images from a 2D representation into a 1D representation via
torch.flatten(x). That means the input of the first fully connected layer is not a 28 by 28 matrix, but rather a vector of length 28x28, which is 784. Recall that the images in MNIST are 28 by 28 pixels.The final fully connected layer has an output of 10, meaning our model will output 10 numbers. These will represent the models confidence for every number (0–9).
Now that we’ve defined a model, we can train it on the MNIST dataset.
Training the Model
Alrighty, let’s look at the training code. It contains some new concepts we’ll have to go over.
1 import torch.nn.functional as F
2 import torch.optim as optim
3
4 #Defining important stuff
5 model = MNISTModel()
6 loss_fn = nn.CrossEntropyLoss()
7 optimizer = torch.optim.SGD(model.parameters(), lr=1e-4)
8
9 losses = []
10
11 for (x, y) in zip(train_data.data, train_data.targets):
12
13 #changing data type
14 x = x.type(torch.float32)
15
16 #asking the model to make a prediction
17 y_pred = model.forward(x)
18
19 #re-formatting the output to instead of 0-10 it's [1,0,0,0,0,0,0,0,0,0] - [0,0,0,0,0,0,0,0,0,1]
20 y = F.one_hot(y,10).type(torch.float32)
21
22 loss = loss_fn(y_pred, y)
23
24 # Backward pass (updating model based on gradients)
25 optimizer.zero_grad()
26 loss.backward()
27 optimizer.step()
28
29 #keeping track of loss
30 losses.append(float(loss))First of all, in line 1 we have a new import, import torch.nn.functional as F . functional is a set of handy functions that are generally useful in building AI models. We’ll use it later in the code.
In line 2 we import another sub-module from torch with import torch.optim as optim . We talked about the theory of how AI models get updated throughout the training process in previous sections. We’ll use optim to actually make that happen.
We define our model in line 5, then in lines 6 and 7 we define two critical elements in the training process. The loss function, defined in line 6, is used to calculate how wrong a particular prediction is. If our model says an image is 60% a 4, 20% an 8, and 20% a 2, and the image is actually a 7, we’ll get a very high loss value because the model was very wrong. If the model is 90% sure an image is of a 4, and the image is of a 4, the loss value will be low. The loss value is used to tell the model how wrong it was during the training process and can also be kept track of over time to see if the model is improving.
In line 7 we define the optimizer. The optimizer is used to update the model based on how wrong it was (the loss). There are many optimizers to choose from, but the most common is “stochastic gradient descent” (SGD). I have an article that explores that concept in depth, if you’re curious:
The optimizer in line 7 is used to update the model throughout the training process, which is why the expression model.parameters() exists. The optimizer will update these parameters through training. The input lr is used to define how much the models' parameters will be changed based on every training example; this is typically a very small number; in this case it’s 0.0001
As we show our model examples of data, and update the model based on those examples, we should expect the model to get less wrong over time. To make sure that’s happening, we’ll keep track of the loss at each training example. We’re defining a placeholder for that in line 9.
Line 10 specifies what’s called our training loop. We’re going to iterate over every single example in the training set and use each of them to update our model. To train the model we need each image and it’s corresponding label, so we need to iterate over both the images and the labels at the same time. If you have two lists of the same size, you can use zip to iterate over both of them simultaneously. This allows us to get the image and label at index 0, the image and label at index 1, the image and label at index 2, etc. Here, we’re saving the image as x and the label as y.
Line 15 is a fiddly little detail. PyTorch has a lot of different data types for numbers, but the data type for the numbers have to be the same for PyTorch to do math between two numbers. The model we defined has model weights of torch.float32 by default, so we need to turn our input (the image x ) into a torch.float32 as well.
Line 17 passes the image through our model and generates a prediction which we save as y_pred . y_pred is a tensor of 10 values, which represents the models prediction of every number. When given an image the model might be 70% sure that number is a zero, 5% sure it’s a one, 5% sure it’s a two, etc. Hence why there are 10 outputs (an output for the numbers 0–9). All 10 of those values are within a single tensor, which is saved as y_pred .
Line 20 reformats our label via a process called one-hot encoding. As previously discussed, the model outputs a list of 10 probabilities. To judge how wrong our model is, we need the desired output represented as a list of 10 probabilities so we can compare it to our model’s output. So, whatever our image is labeled as (a three for instance) we need to convert that label into a list of probabilities (0% a zero, 0% a one, 0% a two, 100% a three, 0% a four, etc.). Ultimately, we’ll compare the model's output probabilities to the one-hot encoded probabilities to judge how wrong the model was.
Line 22 calculates the loss. We know what the model predicted ( y_pred ), and we know what the model should have predicted ( y , which is a one-hot encoded list of probabilities with one value that’s 100% and the rest being 0%). We can pass what the model predicted, and should have predicted, into our loss function and it will give us a single number. If the model did a good job this number will be small, and if the model did a bad job this number will be large.
Lines 25, 26, and 27 are where the actual training of the model happens. A lot of stuff happens behind the scenes, but we can keep it high level for our purposes. Line 25 essentially “resets” the model and makes it ready to learn based on a new example. On the first training example this doesn’t matter, but it’s important to do on the second, third, and subsequent examples. Then, line 26 tells PyTorch “Figure out what parameters need to be bigger, and what parameters need to be smaller”. Line 27 then tells PyTorch “now that we know which parameters need to be bigger or smaller to have a better output, use the optimizer to make the changes”. The optimizer controls if those changes are big or small. Recall that, in AI, we usually do a lot of tiny updates across many different examples.
Finally, in line 30, we’re adding the most recent loss value to the end of a list. As we train across our 60,000 training examples, we’ll get 60,000 loss values which we should expect to generally get smaller as the model trains.
And we can actually check that. We can use matplotlib to plot the values from the losses . Of course, we didn’t cover matplotlib, so don’t worry if you don’t understand this code completely.
import matplotlib.pyplot as plt
import numpy as np
#if we just plot the loss of individual samples we'll get a very sporadic line.
#This smooths out the trend of our data.
def moving_avg(x, n):
cumsum = np.cumsum(np.insert(x, 0, 0))
return (cumsum[n:] - cumsum[:-n]) / float(n)
#Plotting a smoothed version of loss over successive training examples.
plt.plot(moving_avg(losses, 1000))
plt.xlabel('training iteration')
plt.ylabel('loss')
plt.show()
As can be seen from the graph of loss over successive training examples, the loss gets much lower very quickly in the beginning, and then gradually gets lower over successive training examples. This is a very common trend in training and is indicative of the model quickly learning obvious trends in the data, then slowly learning more subtle characteristics of the images over successive training steps.
And with that, we’ve built and trained a model. Now we just need to make sure it works by testing it.
Testing
If you recall, earlier in the article, MNIST came in two sections; the “training data” and the “testing data”. It’s fine to say our model got better from looking at the training data, but how do we know it didn’t do that by learning some quirk in the training dataset? How do we make sure it didn’t memorized some of the examples in the training set rather than actually learning to solve the problem?
The test set is sometimes referred to as the “holdout” set because we’ve withheld that data from the model. The model has never seen the test set. If we run our model on our test set, compare what the model predicted to the actual labels, and decide the model did a good job, then that probably means our model is good at the task it’s been trained to do.
The following code does exactly that. It applies our model to all test examples, compares the predicted vs actual value, and calculates how accurate the model was as a percentage.
num_true = 0
test_quant = 0
for (x_test, y_test) in zip(test_data.data, test_data.targets):
#running test example through model
y_pred_test = model(x_test.type(torch.float32))
#getting predicted value (highest value)
y_pred_test = torch.argmax(y_pred_test)
#checking to see if the right value was predicted
if bool(y_pred_test == y_test):
num_true += 1
test_quant += 1
print(f'Accuracy %:')
print((num_true/test_quant)*100)
Our model predicted 96% of the test data correctly. Not too shabby!
Conclusion
In this article we went from knowing nothing about code to building an AI model. First we set up Google Colab so we could run Python code, then we learned and practiced a few Python concepts. We then discussed some of the fundamental ideas of AI, like how AI models are trained and how they make predictions. Finally, we implemented, trained, and tested an AI model ourselves.
I’m excited for you to begin your journey with AI! It’s a fascinating technology which is equal parts intuitive and mind boggling, and holds tremendous opportunity in terms of professional development and positive world impact. If you want to learn more about AI I think a good next step is convolutional networks, which you can find a link to here:
Convolutional Networks — Intuitively and Exhaustively Explained

Convolutional neural networks are a mainstay in computer vision, signal processing, and a massive number of other machine learning tasks. They’re fairly straightforward and, as a result, many people take them for granted without really understanding them. In this article we’ll go over the theory of convolutional networks, intuitively and exhaustively, and we’ll explore their application within a few use cases.
Join Intuitively and Exhaustively Explained
At IAEE you can find:
Long form content, like the article you just read
Thought pieces, based on my experience as a data scientist, engineering director, and entrepreneur
A discord community focused on learning AI
Regular Lectures and office hours
