
LangGraph — Intuitively and Exhaustively Explained
Building powerful LLM agents within constraints.


In this article we’ll explore “LangGraph”, a cutting-edge tool for making LLM agents that are actually useful.
First we’ll review what an “LLM agent” is, a few popular agentic design approaches, and some of their practical shortcomings. We’ll then discuss how LangGraph can be used to address these shortcomings to make more useful and maintainable agents.
Once we understand why LangGraph exists, we’ll explore the technology practically through something called a “State Graph”. We’ll use this state graph to build an agent which is capable of performing a complex task which requires the agent to deal with natural conversation, hard rules, and application logic. This will serve as a demonstration of how robust and customizable LangGraph agents are.
By the end of this article you’ll understand why LangGraph exists, why it’s important, and how to use it within your own projects.
Who is this useful for? Anyone who wants to form a complete understanding of the state of the art of AI. This article will be particularly interesting to those who are interested in developing AI products.
How advanced is this post? This post contains simple but cutting-edge AI concepts. It’s relevant to readers of all levels.
Pre-requisites: None
Agents
The basic idea of an agent is to enable a language model to reason, plan, and interact with the world. They’re pretty cool. In fact, I think they’re so compelling that they’ll evolve to be a fundamental tool in technology moving forward.

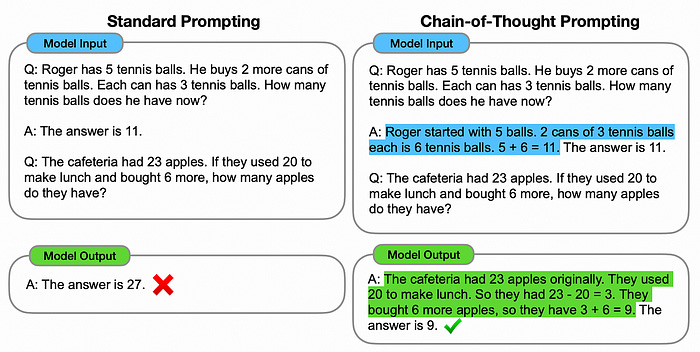
One of the first big breakthroughs in agents was “Chain of Thought Prompting” (proposed in this paper). The basic idea of chain of thought prompting is to use examples of logical reasoning within a prompt to teach a model how to “think through” a problem. By providing the model with an example of your thought process, the model will emulate that thought process in answering your question.

This is useful because language models output text “autoregressively”. Basically, a language model constructs it’s output word by word, using the previous words it’s output to inform how the model generates future words.

A common failure mode of language models is spitting out an incorrect answer in the beginning, then just outputting information that might justify that answer afterward (a phenomenon called hallucination). By asking a model to formulate a response using chain of thought, you’re asking it to think about the final output before outputting it; fundamentally changing the way the language model comes to conclusions about complex questions.
One of the most compelling technologies to build on top of chain of thought is “ReAct”, as proposed in ReAct: Synergizing Reasoning and Acting in Language Models. ReAct is similar to chain of thought in many ways, but with two key deviations:
ReAct forces the model to output it’s response into explicit steps called “thought”, “action”, and “observation”, whereas chain of thought has no such forced structure.
In ReAct we tell the model that when an “action” is output we will execute some tool based on the “action” the model specifies, like searching the internet or executing some function on a calculator.
These two ideas inspired the “reasoning” and “Acting” loop, which gives “ReAct” it’s name.

Practically, a ReAct agent looks something like this:

You don’t have to understand ReAct agents completely to follow this article, but there’s one big takeaway I want to impress. When you build a ReAct agent you essentially construct a big prompt which tells the agent how it should output text, what tools it can use, the problem it should solve, etc. You then hand this prompt to the agent, and it’s off to the races.
This “hands off” approach can be super powerful, and allow agents built on the ReAct architecture to make interesting and compelling decisions, but it also allows them to crash and burn in a practically infinite number of subtle ways. As a result, ReAct style agents don’t have the robustness required to cut the mustard in many production settings, a sentiment I explored in this podcast:
AI agents built on things like ReAct are cool for tech demos, but they’re not robust enough to be used in actual products people care about. We need a way to build agents which is more predictable, testable, and robust. Really, the whole idea of LangGraph is to get around this problem.
LangGraph
Funnily enough, I actually invented and wrote an article on an approach which is very similar to LangGraph about six months before LangGraph came out. I wonder if they used it as inspiration, that would be cool.

The approach I came up with and the approach the LangGraph team took are fundamentally similar: the idea is to use a graph to constrain an agent into a series of steps with pre-defined transitions. Instead of talking about the idea theoretically, let’s explore from a practical perspective.
Imagine you own a real-estate company, and you find a significant amount of your time is spent performing the same repetitive task at the beginning of each new engagement. someone says they’re interested in a house, and you have to collect their name, age, budget, readiness to move, and all sorts of other information before you can do productive work with the client. In real-estate this is commonly referred to as “lead qualification”.
Naively you could just stick the new client in a chat room with an LLM, or LLM wrapped in something like ReAct if you wanted to get fancy, and then you could try to get this information. You might use a prompt like this:
"You are a real-estate agent trying to qualify a new client.
Extract the following information:
- name
- budget
....
Once all information has been extracted from the client, politely
thank them you will be re-directing them to an agent"This would be a great way to start experimenting with an LLM for this use case, but is also a great way to realize how fragile LLMs are to certain types of feedback. The conversation could quickly derail if a user asked a benign but irrelevant question like “Did you catch the game last night?” or “Yeah, I was walking down the road and I saw your complex on second.” Ideally, we want to get the information we need in as human a way as possible, but also in a way that’s predictable and clear.
What if, instead of thinking of lead qualification as a big soup of conversation, we thought of the conversations as specific phases which feed into one another.
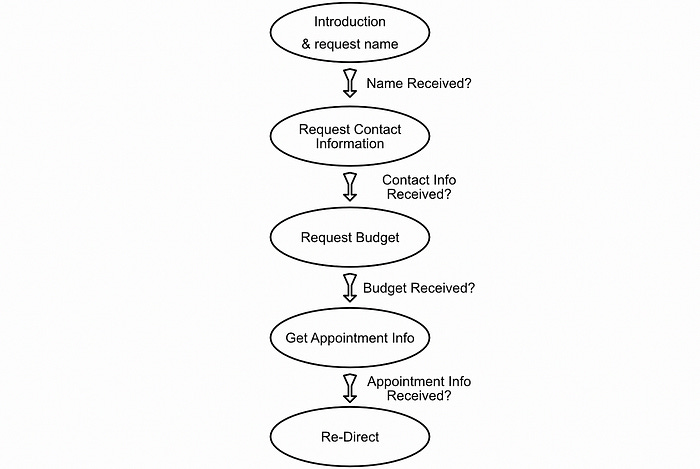
If we’re in the phase of the conversation where we want to get the lead’s contact information and they ask us “if we saw the game last night”, we can use a language model to judge if contact information existed in the users response and then consequently decide that we did not receive that information and the conversation cannot progress until that information is received. This general approach can be used to construct a logical backbone around an otherwise organic seeming conversation.
Probably the most powerful quality of this approach to building agents is iterability. In a ReAct style agent when things go wrong you have to modify a massive prompt. If you fix the problem you might create a bunch of other problems. In a graph one has the option to add nodes and decisions in certain locations which don’t impact other nodes, allowing for developers to add certain conditions based on unexpected edge cases that come up in production.
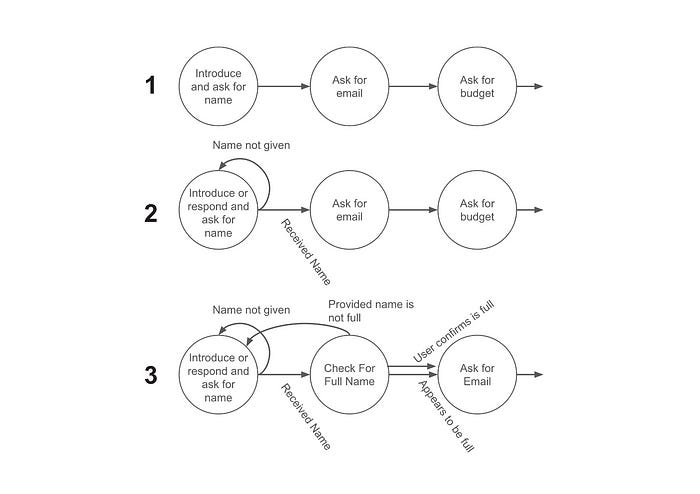
When dealing with practical real world use cases there can be a litany of edge cases one might want to consider and handle. In dealing with these edge cases the resulting graphs can become very complex, making these systems difficult to make performant and elegant. However, after the learning curve around designing graphs has been conquered, thinking of many agentic workflows as graphs can be tremendously powerful and can allow developers to handle many difficult edge cases deftly.
Practically, the challenge of building graph based agents is one of design rather than technical complexity. After we explore how LangGraph works we’ll cover a few design examples.
State Graphs
I think we understand the high level idea of LangGraph, now let’s dig into some of the nitty gritty. As you might imagine there are a ton of ways to actually implement the graphs discussed in previous sections. In this article we’ll be focusing on the “state graph”.
The idea of a state graph is to define some common state that will get passed around the graph as the graph executes.

Within the graph each node takes in state then serves as a function which modifies the state. This can be pretty much any function under the sun, and might include some inference from an AI model or some API call to an external system. You can even use another agent, like a ReAct agent, within a node. The only rule is you get state in, and you send state out.

When a decision has to be made you define another function which can contain pretty much any code. This functions job is to decide which node should be triggered next. We’ll be doing a lot of LLM parsing later in the tutorial, which is a common and super powerful tool in this type of application.
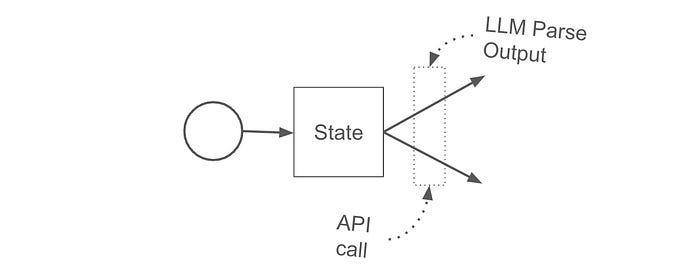
And… that’s pretty much it. Intrinsically there’s actually nothing “AI” about the graph itself, it’s just run of the mill state and logic. Things get crazy when we start adding AI into this system though. Let’s get into it!
Doing Lead Qualification in LangGraph
In the following sections we’ll build an agent using LangGraph to do lead qualification. We’ll start with a fairly simple approach and incrementally build in complexity until we’ve implemented a fairly advanced graph that can handle numerous edge cases.
Full code can be found here.
Installing Stuff
First of all, we need to install some dependencies
!pip install langgraph langchain-openaiWe’ll be using langgraph for obvious reasons, and we’ll be using langchain-openai to call OpenAI models within our graph. The LLMs from OpenAI will be responsible for a variety of tasks including generating conversational dialogue and analyzing the users responses.
Making A Super Simple State Graph
Before we get into the fancy stuff, let’s make a graph that spits out Hello World
from typing import TypedDict
from langgraph.graph import StateGraph, END
# Defining state
class GraphState(TypedDict):
incrementor: int
workflow = StateGraph(GraphState)
# function for hello_world node
def handle_hello_world(state):
print('Hello World')
state['incrementor'] += 1 # Correctly update the state
return state # Return the modified state
# Add the node to the graph
workflow.add_node("hello_world", handle_hello_world)
# Set entry point and edge
workflow.set_entry_point("hello_world")
workflow.add_edge('hello_world', END)
# Compile and run the workflow
app = workflow.compile()
inputs = {"incrementor": 0} # Provide the initial state
result = app.invoke(inputs)
print(result)
LangGraph uses mermaid under the hood to allow us to render the graph as well, which is pretty handy.
from IPython.display import Image, display
display(Image(app.get_graph(xray=True).draw_mermaid_png()))
Within the code, you’ll notice we explicitly defined the state GraphState , which contains a field incrementor . There are a few quirks in LangGraph which one is quickly confronted with, one of which is that the state has to be modified in every node. So you can’t have a node that does not modify the state. We can get around this trivially by simply having each node increment the incrementor field of the state.
You’ll also notice that nodes are named. The expression workflow.add_node(“hello_world”, handle_hello_world) creates the only user-defined node in the graph, giving it a name "hello_world" and the function handle_hello_world . These names are used throughout LangGraph for connecting nodes together and routing between nodes during execution, which will come up later.
You might notice I call my definition of the graph workflow and then the graph gets “compiled” into app . This is, from what I can tell, the standard convention in the LangGraph documentation. Really they’re both the graph, but the workflow is the representation in which we build the graph and the app is the representation in which we run the graph. I’m sure there’s some magic under the hood which allows the app to be efficient and what not.
At the end of the day the graph gets run with app.invoke(inputs) , which in turn spits out the final state representation. The state was passed through the hello_world node which ran the handle_hello_world function on the state, which in turn incremented the incrementor field in the state by one, hence the output.
Saying Hello and Getting a Name
Now that we have an idea of how LangGraph works, let’s do the simplest possible lead qualification: asking the user for their name.
from typing import TypedDict
from langgraph.graph import StateGraph, START, END
# Defining state
class GraphState(TypedDict):
name: str
incrementor: int
workflow = StateGraph(GraphState)
# a node for introducting the bot to the user
def handle_intro(state):
state['incrementor'] += 1
print('Hello!')
return state
# a node for getting the users name
def handle_name_request(state):
state['incrementor'] += 1
state['name'] = input('What is your name? ')
return state
# Adding Nodes to Graph
workflow.add_node("intro", handle_intro)
workflow.add_node("name_request", handle_name_request)
# Set entry point and edge
workflow.set_entry_point("intro")
workflow.add_edge('intro', 'name_request')
workflow.add_edge('name_request', END)
# Compile and run the workflow
app = workflow.compile()
inputs = {"incrementor": 0} # Provide the initial state
result = app.invoke(inputs)
print('output state:')
print(result)Here we have two nodes, one which simply prints out “hello”, and another which asks the user for their name and saves that name to the name field within the state. Here’s an example of me running the code.

This is pretty cool, but it’s pretty basic. Let’s get some AI magic in here to do some more advanced stuff.
Parsing First and Last Name
Imagine we want to get an idea of what their first and last name is. If the user responds “Oh hey, my name is Daniel Warfield”, we want to extract, in a structured manner, that the users first name is “Daniel” and the users last name is “Warfield”.
Luckily, LangChain has a handy tool for extracting a structured output from an LLM. First we define an object that represents the data in a way that we want.
class Name(TypedDict):
first_name: str
last_name: strThen we can define a prompt in LangChain that describes the data we want to extract.
name_parse_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"""Parse the first and last name from the users message""",
),
("placeholder", "{messages}"),
]
)Then we can construct a chain (which is out of scope of this article, but in essence a chain is a sequence of LLM operations that can be chained together) which uses that prompt and class to parse an input into a structured output.
name_parser = name_parse_prompt | ChatOpenAI(
model="gpt-4o", temperature=0
).with_structured_output(Name)Under the hood the name_parserchain takes in a message, like “Oh hey, my name is Daniel Warfield”, and constructs a prompt around it which tells the AI model that we want to extract the first and last name in a structured output. LangChain handles a bunch of the fiddly prompting strategies to make that work consistently, and we can essentially treat this like a function that spits out structured output.
# we can take in whatever the user said and output a Name object
# consisting of name.first_name and name.last_name
name = name_parser.invoke({"messages": [("user", user_reponse)]})
first_name = name.first_name
last_name = name.last_nameIf you want to know a bit more about getting structured output from LangChain, I cover the subject in depth in my article on conversations as directed graphs.
We can use this chain in our function to parse out the first name and last name from our user within our greater graph, we just need to inject the parser in our node function and update the state to support a first and last name.
from typing import TypedDict
from langgraph.graph import StateGraph, START, END
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
# Defining state
class GraphState(TypedDict):
first_name: str
last_name: str
incrementor: int
workflow = StateGraph(GraphState)
# introducing the user to the
def handle_intro(state):
state['incrementor'] += 1
print('Hello!')
return state # Does not modify state
# ===== building Parser =====
class Name(TypedDict):
first_name: str
last_name: str
name_parse_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"""Parse the first and last name from the users message""",
),
("placeholder", "{messages}"),
]
)
name_parser = name_parse_prompt | ChatOpenAI(
model="gpt-4o", temperature=0
).with_structured_output(Name)
# ===========================
# Creating Parsing Node
def handle_name_request(state):
state['incrementor'] += 1
user_reponse = input('What is your first and last name? ')
name = name_parser.invoke({"messages": [("ai", "What is your first and last name?"),("user", user_reponse)]})
state['first_name'] = name['first_name']
state['last_name'] = name['last_name']
return state
# Adding Nodes to Graph
workflow.add_node("intro", handle_intro)
workflow.add_node("name_request", handle_name_request)
# Set entry point and edge
workflow.set_entry_point("intro")
workflow.add_edge('intro', 'name_request')
workflow.add_edge('name_request', END)
# Compile and run the workflow
app = workflow.compile()
inputs = {"incrementor": 0} # Provide the initial state
result = app.invoke(inputs)
print('output state:')
print(result)
Checking for Full First and Last Name
We’re making something cool, but maybe we don’t want the user to be able to submit an abbreviation of their name. Maybe we want to insist that the user provides their full name. To do that we’ll implement our first “conditional edge”. This is an edge that makes some decision based on the state, where that decision is based on the output of a function. Here’s an example of a conditional edge that might be used to check if the user provided their full name:
# =========== Defining Chain with Structured Output ===========
class IsFullName(TypedDict):
is_full_name: bool
name_check_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"""Is the name a full and complete first and last name?""",
),
("placeholder", "{messages}"),
]
)
name_checker = name_check_prompt | ChatOpenAI(
model="gpt-4o", temperature=0
).with_structured_output(IsFullName)
# =============================================================
# Defining name checker function
def check_full_name(state):
state['incrementor'] += 1
name_check = name_checker.invoke({"messages": [("user", f"first name: \"{state['first_name']}\", last name: \"{state['last_name']}\"")]})
if name_check['is_full_name']:
return '__end__'
else:
print('The name provided was not complete')
return 'name_request'
# creating conditional edge
workflow.add_conditional_edges(
'name_request',
check_full_name,
["name_request", "__end__"]
)Here I’m showing only the conditional components in isolation, the graph also has a node for requesting the users name ( name_request ) and ending (__end__ ). You can see the full code here if you’re inclined.
First we’re defining a chain called name_checker that asks, given some input, does the name specified consist of a full name, which is output as a boolean (true or false). Then, we can use that chain to check the state of the name itself. The check_full_name function turns the first and last name into a string, sends it to the name_checker , then outputs which node the edge should lead to based on if the name was full or not. Note how we’re returning the names of the nodes we will navigate to.
As a quirk of this approach, because we’re using a function to dynamically route to any node in the graph, it’s impossible to know ahead of time which nodes the edge actually points to. This causes problems if you want to render the graph, so we can define a list of nodes the conditional edge points to as the third argument in add_conditional_edges so the rendering happens nicely.
Here’s an example of me interacting with this agent where I first say my name is “dan w”, then say my name is “daniel warfield”.

And here’s a printout of the graph, where conditional edges are drawn with dotted lines.

If you observe the output of my conversation with the agent you’ll notice it’s not very conversational. That’s because we’re not actually using an LLM to do any text generation, only parsing. Let’s fix that.
Making the Agent Conversational
Previously we passed the users inputs to some system then carried on our merry way. If they said their name was “dan w” we said that was invalid and asked them to try again. If we were to create a more conversational bot we might want to store that they said “dan w” so we could use that information to respond with something like “hey dan, can I get your full name?”. To achieve this we’ll add a new component to the state variable which records the conversation. This will be a list of tuples of strings, where the list corresponds to messages in sequential order and the tuple contains who said a thing (the AI or the user) and what was said.
# an example of what the conversational state may look like as the conversation
# progresses
[('ai', 'hello! whats your name?'),
('user', 'dan w'),
('ai', 'hey dan, can I get your full name?'),
('user', 'sure, its daniel warfield')
]Throughout critical points of the conversation we can add system prompts which we use to inform the agent on what it should be saying.
# an example of what the conversational state may look like as the conversation
# progresses with system prompts used to guide the agents output
[('system', 'introduce yourself and ask for the users name'),
('ai', 'hello! whats your name?'),
('user', 'dan w'),
('system', 'the users name is not full. Ask for their full name'),
('ai', 'hey dan, can I get your full name?'),
('user', 'sure, its daniel warfield')
]Thus we can build organic conversation which uses the graph as a logical backbone. Here’s the code.
from typing import TypedDict
from langgraph.graph import StateGraph, START, END
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
# Defining state
class GraphState(TypedDict):
first_name: str
last_name: str
incrementor: int
conversation: list[tuple[str]]
workflow = StateGraph(GraphState)
# =========== Defining name request node ================
class Name(TypedDict):
first_name: str
last_name: str
name_parse_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"""Parse the first and last name from the users message""",
),
("placeholder", "{messages}"),
]
)
name_parser = name_parse_prompt | ChatOpenAI(
model="gpt-4o", temperature=0
).with_structured_output(Name)
# name request node handler
def handle_name_request(state):
state['incrementor'] += 1
#if the conversation has just started, append a system prompt
if state['conversation'] is None:
system_prompt = '''
You are an AI agent tasked with doing lead qualification for a real-estate
company. Your present objective is to introduce yourself as "Rachael", say
you're excited to help them get set up with a new home. After you introduce yourself,
ask them for their name in full so you can get started.
'''
state['conversation'] = [('system', system_prompt)]
chat = ChatOpenAI(model="gpt-4o", temperature=0)
ai_request_to_user = chat.invoke(state['conversation']).content
user_reponse = input(ai_request_to_user +'\n')
state['conversation'].append(('user', user_reponse))
name = name_parser.invoke({"messages": state['conversation']})
state['first_name'] = name.get('first_name', '')
state['last_name'] = name.get('last_name', '')
return state
workflow.add_node("name_request", handle_name_request)
# =========== Defining name checker ================
class IsAcceptable(TypedDict):
is_acceptable: bool
name_check_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"""Is the name a full and complete first and last name? The name should either
be an obvious full legal name, or the user should have confirmed that it is their full name.
If either are true, then the name is considered acceptable.""",
),
("placeholder", "{messages}"),
]
)
name_checker = name_check_prompt | ChatOpenAI(
model="gpt-4o", temperature=0
).with_structured_output(IsAcceptable)
# defining name checking function used in the conditional edge
def check_full_name(state):
state['incrementor'] += 1
name_check = name_checker.invoke({"messages": state['conversation']+[("user", f"first name: \"{state['first_name']}\", last name: \"{state['last_name']}\"")]})
if name_check['is_acceptable']:
return '__end__'
else:
system_prompt = '''
The provided name appears to be incomplete. Please notify the user
that the name does not appear to be complete and request that they either
provide their full name or confirm that that is indeed their full name. You don't need to re-introduce yourself anymore.
'''
state['conversation'].append(('system', system_prompt))
return 'name_request'
# ===========================
# Set entry point and edge
workflow.set_entry_point('name_request')
#defining conditional edge
workflow.add_conditional_edges(
'name_request',
check_full_name,
["name_request", "__end__"]
)
# Compile and run the workflow
app = workflow.compile()
inputs = {"incrementor": 0, "conversation":None} # Provide the initial state
result = app.invoke(inputs)
print('output state:')
print(result)Let’s render this out for reference
display(Image(app.get_graph(xray=True).draw_mermaid_png()))
In this example we ditch the idea of having a seperate introduction node and instead use prompting to get the AI model to introduce itself on the first run of name_request . Notice how, in the handle_name_request function, if the current conversation is None (i.e. we just started) we inject a system prompt into the conversation which tells the AI model to introduce itself and ask for the users full name.
After the user has entered their name the graph passes the state to our conditional edge which employs the function check_full_name . This function uses a chain to ask an AI model if the provided name is full. If the name is full the graph concludes and outputs the full name. What’s interesting is if the name is not full.
If the names not full the conditional edge passes the state back to the name_request node, except before doing so it injects a system prompt into the current dialogue between the AI and the user. This prompt tells the model that the name provided is incomplete, and the AI model should ask for the full name again. Also, as a funny little quirk, the model would often re-introduce itself again at this stage, so I added a note that the model didn’t have to re-introduce itself. This is an example of the fine grained and conditional adjustments that are possible with a system built on graphs.
Once that all shakes out we end up with a fairly conversational agent. Here’s an example.

As you can see, even though the agent exists across isolated node executions, because we keep track of the conversation we can maintain a coherent dialogue.
Ok, we covered a lot of interesting ideas. Let’s make something that ticks up some eyebrows.
Adding Bells and Whistles
I wanted to play around with this system and create something a bit more advanced. It uses all the same ideas as the previous examples just more of them. This agent
asks for a first and last name
checks if the name is full or not
asks for a new name or a confirmation that it’s a full name
asks if the user has an account
sends account setup info if they don’t have an account yet
asks for the users account email
sends a short verification code to that email (simulated) to confirm the users identity
asks for that verification code back
sends the code to the server (simulated) to confirm the identity of the user.
In constructing an agent in this way we’re adding hard prgramatic steps within the flow of the agent, allowing for user confirmation. This ability to impose rigid rules and structures is one of the most exciting powers of graph based agents. Here’s the code:
from typing import TypedDict
from langgraph.graph import StateGraph, START, END
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
# Defining state
class GraphState(TypedDict):
first_name: str
last_name: str
incrementor: int
conversation: list[tuple[str]]
has_account: bool
email: str
verification_code: int
workflow = StateGraph(GraphState)
# ===========================
class Name(TypedDict):
first_name: str
last_name: str
name_parse_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"""Parse the first and last name from the users message""",
),
("placeholder", "{messages}"),
]
)
name_parser = name_parse_prompt | ChatOpenAI(
model="gpt-4o", temperature=0
).with_structured_output(Name)
def handle_name_request(state):
state['incrementor'] += 1
#if the conversation has just started, append a system prompt
if state['conversation'] is None:
system_prompt = '''
You are an AI agent tasked with doing lead qualification for a real-estate
company. Your present objective is to introduce yourself as "Rachael", say
you're excited to help them get set up with a new home. After you introduce yourself,
ask them for their name in full so you can get started.
'''
state['conversation'] = [('system', system_prompt)]
chat = ChatOpenAI(model="gpt-4o", temperature=0)
ai_request_to_user = chat.invoke(state['conversation']).content
user_reponse = input(ai_request_to_user +'\n')
state['conversation'].append(('user', user_reponse))
name = name_parser.invoke({"messages": state['conversation']})
state['first_name'] = name['first_name']
state['last_name'] = name['last_name']
return state
workflow.add_node("name_request", handle_name_request)
# ===========================
class IsAcceptable(TypedDict):
is_acceptable: bool
name_check_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"""Is the name a full and complete first and last name? The name should either
be an obvious full legal name, or the user should have confirmed that it is their full name.
If either are true, then the name is considered acceptable.""",
),
("placeholder", "{messages}"),
]
)
name_checker = name_check_prompt | ChatOpenAI(
model="gpt-4o", temperature=0
).with_structured_output(IsAcceptable)
def check_full_name(state):
state['incrementor'] += 1
name_check = name_checker.invoke({"messages": state['conversation']+[("user", f"first name: \"{state['first_name']}\", last name: \"{state['last_name']}\"")]})
if name_check['is_acceptable']:
return 'has_account_node'
else:
system_prompt = '''
The provided name appears to be incomplete. Please notify the user
that the name does not appear to be complete and request that they either
provide their full name or confirm that that is indeed their full name. You don't need to re-introduce yourself.
'''
state['conversation'].append(('system', system_prompt))
return 'name_request'
# ===========================
class HasAccount(TypedDict):
has_account: bool
has_account_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"""Does the user have an account or not?""",
),
("placeholder", "{messages}"),
]
)
has_account_parser = has_account_prompt | ChatOpenAI(
model="gpt-4o", temperature=0
).with_structured_output(HasAccount)
def handle_has_account(state):
state['incrementor'] += 1
system_prompt = '''
The users name has been acquired. Now, ask if they have an account
already set up.
'''
state['conversation'].append(('system', system_prompt))
chat = ChatOpenAI(model="gpt-4o", temperature=0)
ai_request_to_user = chat.invoke(state['conversation']).content
user_reponse = input(ai_request_to_user +'\n')
state['conversation'].append(('user', user_reponse))
has_account = has_account_parser.invoke({"messages": state['conversation']})
state['has_account'] = has_account['has_account']
return state
workflow.add_node("has_account_node", handle_has_account)
# ===========================
def check_has_account(state):
state['incrementor'] += 1
if state['has_account']:
return 'get_email'
else:
system_prompt = '''
The user does not have an account set up. Tell them to set one up at
danielwarfield.dev then ask them to come back when they're done.
Respond directly to the previous users message as if in a continuous
conversation
'''
state['conversation'].append(('system', system_prompt))
chat = ChatOpenAI(model="gpt-4o", temperature=0)
ai_request_to_user = chat.invoke(state['conversation']).content
user_reponse = input(ai_request_to_user +'\n')
state['conversation'].append(('user', user_reponse))
return 'get_email'
# ===========================
class Email(TypedDict):
email: str
email_parse_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"""What email did the user provide?""",
),
("placeholder", "{messages}"),
]
)
email_parser = email_parse_prompt | ChatOpenAI(
model="gpt-4o", temperature=0
).with_structured_output(Email)
def handle_request_email(state):
state['incrementor'] += 1
system_prompt = '''
The user has an email associated to their account. Ask them for it.
'''
state['conversation'].append(('system', system_prompt))
chat = ChatOpenAI(model="gpt-4o", temperature=0)
ai_request_to_user = chat.invoke(state['conversation']).content
user_reponse = input(ai_request_to_user +'\n')
state['conversation'].append(('user', user_reponse))
email = email_parser.invoke({"messages": state['conversation']})
state['email'] = email['email']
return state
workflow.add_node("get_email", handle_request_email)
# ===========================
class ShortCode(TypedDict):
short_code: int
code_parse_ptompt = ChatPromptTemplate.from_messages(
[
(
"system",
"""Parse out the short integer code from the prompt""",
),
("placeholder", "{messages}"),
]
)
short_code_parser = code_parse_ptompt | ChatOpenAI(
model="gpt-4o", temperature=0
).with_structured_output(ShortCode)
def email_verify(state):
state['incrementor'] += 1
system_prompt = '''
Inform the user that a short code has been sent to their email. Ask them
to confirm their email with that code.
'''
state['conversation'].append(('system', system_prompt))
chat = ChatOpenAI(model="gpt-4o", temperature=0)
ai_request_to_user = chat.invoke(state['conversation']).content
user_reponse = input(ai_request_to_user +'\n')
state['conversation'].append(('user', user_reponse))
short_code = short_code_parser.invoke({"messages": state['conversation']})
state['verification_code'] = short_code['short_code']
return state
workflow.add_node("email_verify", email_verify)
# ===========================
def check_auth(state):
state['incrementor'] += 1
if state['email'] == 'hire@danielwarfield.dev' and state['verification_code'] == 1111:
print('Email verified. Done!')
return '__end__'
else:
system_prompt = '''
Either the user name or short code was incorrect. Ask for the email again.
'''
state['conversation'].append(('system', system_prompt))
chat = ChatOpenAI(model="gpt-4o", temperature=0)
ai_request_to_user = chat.invoke(state['conversation']).content
user_reponse = input(ai_request_to_user +'\n')
state['conversation'].append(('user', user_reponse))
return 'get_email'
# ===========================
# Set entry point and edges
workflow.set_entry_point('name_request')
workflow.add_conditional_edges(
'name_request',
check_full_name,
["name_request", "has_account_node"]
)
workflow.add_conditional_edges(
'has_account_node',
check_has_account,
["get_email"]
)
workflow.add_edge("get_email", "email_verify")
workflow.add_conditional_edges(
'email_verify',
check_auth,
["get_email", '__end__']
)
# Compile and run the workflow
app = workflow.compile()
inputs = {"incrementor": 0, "conversation":None} # Provide the initial state
result = app.invoke(inputs)
print('output state:')
print(result)At this point the code becomes a bit ungainly, and could probably benefit from some factory-esque functions or multiple files. In reality this is essentially exactly the same as the previous examples, just with more nodes.
Here’s the printout
display(Image(app.get_graph(xray=True).draw_mermaid_png()))
And here’s an example of me interacting with this bot:
Hi there! I'm Rachael, and I'm excited to help you get set up with a new home. Could you please provide me with your full name so we can get started?
dan w
Hi Dan, it looks like your name might be incomplete. Could you please provide your full name or confirm if "Dan W" is indeed your full name? This will help me get started on finding the perfect home for you.
yeah beleive it or not that's actually my full name. Weird parents.
Nice to meet you, Dan W! Do you already have an account set up with us?
yep
Great, Dan! Could you please provide the email address associated with your account?
yeah it's hire@danielwarfield.dev
Great, Dan! A short code has been sent to your email. Could you please check your inbox and provide me with that code to confirm your email?
just got it. 1111
Email verified. Done!
output state:
{'first_name': 'Dan', 'last_name': 'W', 'incrementor': 5, 'conversation':...}Conclusion
Graph based agents are cool. Like, really cool.
I’ve had a lot of conversations with some heavy hitters in the industry over the last few months, and I’m seeing a regular theme: If AI can’t transcend the twitter demo and become actual useful products, then the industry is in a world of hurt. Luckily, I think graph based agents are the right balance of abstract and specific to solve a lot of conversational use cases. I expect we’ll see them grow as a fundamental component of modern LLM powered applications.
In this article we covered the idea of an agent, and how graph based agents fit within that greater picture. We explored some of the ideas of state graphs, a particular flavor of a graph based agent, and implemented a few examples of state graphs ourselves. I hope you enjoyed!
Join Intuitively and Exhaustively Explained
At IAEE you can find:
Long form content, like the article you just read
Thought pieces, based on my experience as a data scientist, engineering director, and entrepreneur
A discord community focused on learning AI
Regular Lectures and office hours
