
AI Generated In-Text Citations — Intuitively and Exhaustively Explained
Knowing where information comes from in LLM-powered applications


You’ve probably played around with tools like ChatGPT, Anthropic, and Perplexity. When you ask these systems a question, they generate a response with a bunch of useful information.
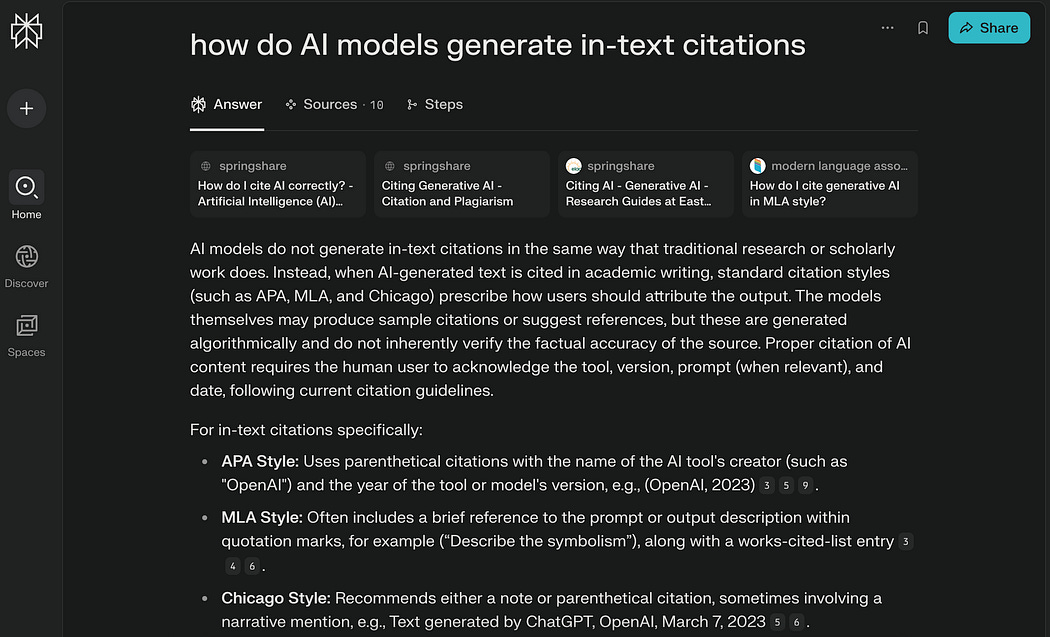
Along with text, these systems also provide in-text citations, allowing users to view the source of data that is relevant to a particular statement.
In-text citations are an incredibly powerful tool that allows for more robust, more useful, more trustworthy, and more testable LLM applications. In this article, we’ll break down the subject in-depth and build a system to generate in-text citations ourselves.

Who is this useful for? Anyone interested in building cutting-edge AI applications.
How advanced is this post? This article contains simple explanations of fundamental approaches in AI-powered application development. Thus, this article is relevant to readers of all levels.
Prerequisites: None, though some Python experience may be useful in understanding the implementation sections later in the article.
Why In-Text Citations Matter
To be completely honest, I rarely use in-text citations when interfacing with chat bots like ChatGPT. Personally, I use LLMs as resources for high-level descriptions and quick code revisions, and rarely use them as the beginning point for deeper research. I think that’s part of the reason more experienced developers don’t often discuss in-text citations; we treat AI like a junior assistant, not a source of knowledge. It’s often faster for us to look at the response itself and judge it as right or wrong, rather than comb through a bunch of sources.
As LLM-powered applications reach new domains, ones that require domain expertise, deep research, and complex logic, I think this paradigm will change. LLM applications will start telling us things we didn’t already know, and users will need to quickly confirm that information to be accurate.
I’ve been obsessed with in-text citations for the last three months, chiefly for this reason. I’ve been working on a fraud detection platform that’s designed to find new evidence of fraud within large sets of legal documents called FraudX. It does a pretty good job at detecting fraud; our slogan is “detect fraud 40x faster”, but I think that’s a bit of an understatement. Months of work can be summarized in minutes. That’s great, but issues arise when evidence of fraud leaves the auditor's desk and ends up in the courtroom; it’s not enough to throw up your hands and say “AI told me so”. Our customers need to be able to back up claims with evidence. Thus, detecting fraud is only half the battle; you also need to expose the correct sources to the user so they can build a well-supported case. In-text citations are critical because they provide the link between what the AI said and the supporting evidence.
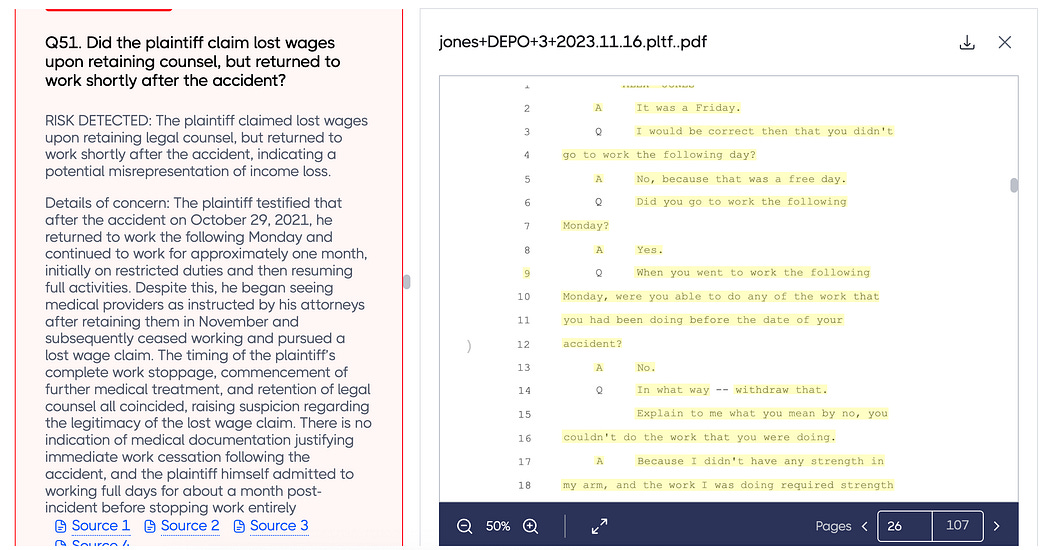
Robust in-text citations are also critical for developers. Compared to our customers, I know next to nothing about law, legal procedure, and fraud. Despite this, I need to quickly be able to understand if our system is performant. In-text citations allow me to judge output from the LLM on a statement-by-statement basis.
The LLM said that Joe got surgery for a broken femur in early July. Check the source, yep that’s true.
The LLM said that there’s a picture of Joe in a salsa class, without a cast, in late July. Check the source, yep that’s true.
The LLM said this is likely a case of insurance fraud because it’s impossible for Joe to have recovered that quickly. Makes sense to me!
As developers integrate AI into increasingly sophisticated domains, testing is becoming more difficult. Robust and well-developed in-text citations are a critical tool that allows developers to better understand LLM responses. This makes testing significantly easier for developers.
Before we get into generating in-text citations, I want to cover some of the foundational techniques we’ll be building on top of.
RAG — The Foundation of In-Text Citation
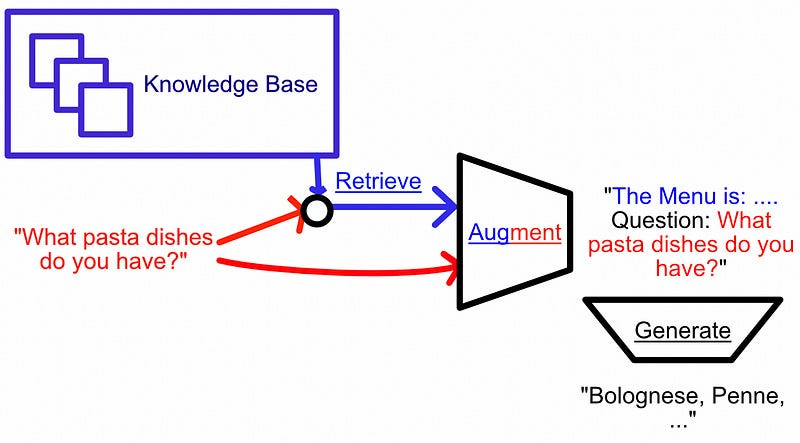
As you probably know (I’ve covered RAG about a billion times at this point) “RAG” stands for “Retrieval Augmented Generation”, and is a general workflow for injecting context into a language model. It consists of the following steps:
Get a query from the user.
Use that query to retrieve relevant information that might be used as context in answering that query.
Construct a prompt consisting of the query and context.
Pass that prompt to an LLM for generation.
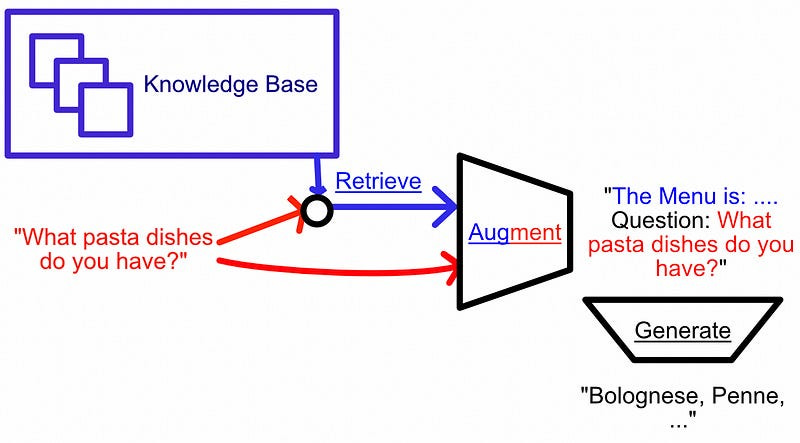
The core workflow, from my article on RAG. This works because language models are in-context learners, yadah yadah yadah. I don’t want to harp too much on RAG in this article; I have plenty of articles on the subject if you want to explore the technology more in depth:
For the purposes of this article, we only have to understand RAG from the highest level. Basically, with RAG, we look stuff up, feed the model a bunch of information, then ask it a question.

A simple example of a prompt we might pass to a language model in a RAG context. We look up a bunch of information that might be relevent to a question, then pass that as context, allong with the question, to the language model. The whole idea of in-text citation is pretty simple. Instead of passing references as a big block of text, you inject unique identifiers to each retrieved source.

The first step of creating in-text citations is to add unique identifiers to each piece of information. Then, you adjust the system prompt of the model and tell the LLM to print out one of those unique identifiers whenever the LLM uses the information from a particular source.

The second step of implementing in-text citations is to add a system prompt, describing how the LLM should reference a particular source. Once a response has been generated, the LLM response can be post-processed. We can look through the text and replace all of the referenced IDs with buttons, hyperlinks, or whatever else your application demands.
hyperlinks, or whatever else your application demands.

The company I work for, EyeLevel.ai, maintains a RAG system called GroundX (which has an open source version designed for enterprise clients called GroundX on-prem and a hosted offering called the GroundX Platform). To make GroundX easier to use, we’re releasing a set of open source tools called GroundX community, which is designed to accelerate certain workflows. The first feature GroundX community supports is in-text citations, which we’ll be using in this article.
Creating In-Text Citations with GroundX Community
If you install GroundX community via
pip install git+https://github.com/EyeLevel-ai/groundx_community.gityou can import a function called
generate_cited_responsefrom groundx_community.chat_utils.citing import generate_cited_responseThis function expects the following input:
generate_cited_response(chunks, system_prompt, query)chunks: A list of contextual information that’s relevant to the query, with some important metadata attached to each chunk for the purposes of generating in-text citations.
system_prompt: A prompt to the model describing how it should act
query: The question or command from the user
It also has the optional parameter llm that accepts any LangChain LLM that inherits from
langchain_core.language_models.chat_models.BaseChatModel. Thegenerate_cited_responsefunction does all the work necessary to format a prompt to the LLM, then the LLM is used to generate the final response with in-text citations. By default,gpt-4ois used, and is authenticated via an API key in theOPENAI_API_KEYenvironment variable.The chunks variable itself is a list of chunks. This consists of the references passed to the LLM, with some key metadata so that in-text citations can be generated properly.
chunks = [ { "text": "reference text retreived from some source" "uuid": "unique_identifier-cccc-dddd-eeee-000000000001", "render_name": "source1.txt", "source_data": { "arbitrary_key": "example value", "url": "https://example.com/source1.txt", "filename": "source1.txt", "file_type": "txt", "document_uuid": "doc-001" } }, { "text": "reference text retreived from some source" "uuid": "unique_identifier-cccc-dddd-eeee-000000000002", "render_name": "source2.txt", "source_data": { "arbitrary_key": "example value", "url": "https://example.com/source2.txt", "filename": "source2.txt", "file_type": "txt", "document_uuid": "doc-002" } }, ... ]There are three necessary fields for each chunk:
The text, which contains the information passed to the LLM which will be referenced. This might be information from a website, PDF, word document, or whatever.
The UUID, this will be used by the in-text citation system to reference a particular chunk. One may choose to generate a random UUID for each document, or you might have one lying around which is convenient to use.
The render_name, is used for actually generating the in-text citation. This is the text which will pop up. This could be something like source1, source2, source3, the actual filenames, an abbreviation of the filenames, whatever.
There is an additional field called source_data. This allows one to attach arbitrary key-value pairs, which can be used in the application. For instance, a
urlmight be attached, which can allow the application to open a document when a source is clicked on.Note that chunks could be generated from virtually any RAG retreival; If you’re using GroundX, LangChain, LlamaIndex, or some bespoke RAG pipeline, the results of virtually any RAG pipeline could be used to construct chunks, and thus can be fed into
generate_cited_responseto create a response with in-text citations.We also need a
system_prompt. On the tin this is pretty simple, it’s just a system prompt to describe to the model the types of responses it should generate. Here are some examples:system_prompt_1=( "You are a helpful assistant. Use the provided excerpts to fully analyze and answer the user's question. " )system_prompt_2=( "You are a helpful assistant. Use the provided excerpts to fully analyze and answer the user's question. " "If any information is irrelevant, do not cite it or mention it. Think carefully and show clear reasoning." "provide your answer as a \"rationale: \" which includes in-text citations, and \"final answer: \" which is a concise answer to the question. " "the final answer should be separated by the rationale by a paragraph break. The rationale should not include newlines." ),system_prompt_3=( "You are a helpful assistant. Use the provided excerpts to fully analyze and answer the user's question. " "You must rely only on information from the excerpts, and cite every excerpt you used using the $REF: ID$ format. " "If any information is irrelevant, do not cite it or mention it. Think carefully and show clear reasoning." "provide your answer as a \"rationale: \" which includes in-text citations, and \"final answer: \" which is a concise answer to the question. " "the final answer should be separated by the rationale by a paragraph break. The rationale should not include newlines." ),As a general rule, it’s recommended not to include information about generating in-text citations within the system prompt, as is done in the third example. Under the hood, the
generate_cited_responsefunction contains the following prompt which is also passed to the model.I am going to ask a question in my next message. Here are some excerpts uniquely identified by an ID that may or may not be relevant. You need to perform 2 tasks: 1) Generate a response to answer the question. If these excerpts relate to my question, use them in your response. If not, ignore them, and rely on our conversation context. 2) If any excerpt is used, generate in-text citation using the excerpt ID as follows - $REF: ID$. The formatting must be strictly followed. For example, if excerpt corresponding to ID 03b994bc-2fae-4e1e-a4cd-f0f3e6db2d90 is used in generating the response, source attribution must be - $REF: 03b994bc-2fae-4e1e-a4cd-f0f3e6db2d90$ Strictly follow the instructions of the above tasks. Do not mention whether the content or previous context was used or not; respond seamlessly. Avoid phrases like "the provided content" or similar. Take into account everything we've discussed so far, without assuming everything is relevant unless it clearly supports your answer. -----If the system prompt passed to the
generate_cited_responseconflicts with this instruction, it will damage in-text citation creation. Thus, it’s recommended that thesystem_promptonly contains application level instructions and not prompts about how in-text citations should be structured.Once chunks and a system prompt have been specified, one simply needs to define a query and we’re off to the races. In a traditional RAG context the chunks would be retrieved based on the query, but we can implement a simple example which forgoes this step and uses a static context.
from groundx_community.chat_utils.citing import generate_cited_response # ------------------------------- # Defining Variables # ------------------------------- CHUNKS = [ { "text": ( "George currently possesses a variety of fruits in his market stall, including three bunches of grapes and a crate of strawberries. " "The grapes are organic, grown locally, and usually sold by the bunch. He typically sells the grapes in quantities of one or more, depending on customer demand. " "The strawberries, on the other hand, are imported and priced differently based on weight rather than quantity." ), "uuid": "11111111-aaaa-bbbb-cccc-000000000001", "render_name": "market_inventory.txt", "source_data": { "url": "https://example.com/market_inventory", "filename": "market_inventory.txt", "file_type": "txt", "document_uuid": "doc-001" } }, { "text": ( "Natalie recently exchanged €5.00 into U.S. dollars and received exactly $5.45 USD. " "She has expressed interest in buying grapes and strawberries from George. " "However, she also mentioned she wants to keep $1.00 in reserve to buy bread from a nearby bakery later in the day." ), "uuid": "22222222-bbbb-cccc-dddd-000000000002", "render_name": "wallet_and_intentions.txt", "source_data": { "url": "https://example.com/wallet", "filename": "wallet_and_intentions.txt", "file_type": "txt", "document_uuid": "doc-002" } }, { "text": ( "George stated that he is willing to sell grapes for fifty cents per bunch, but added that if someone buys three bunches, he will offer them for a flat $1.25. " "Strawberries are sold for $3.00 per crate, and George is unwilling to negotiate on that price unless multiple crates are bought. " "All prices are quoted in USD and must be paid in cash." ), "uuid": "33333333-cccc-dddd-eeee-000000000003", "render_name": "pricing_policy.txt", "source_data": { "url": "https://example.com/pricing", "filename": "pricing_policy.txt", "file_type": "txt", "document_uuid": "doc-003" } }, { "text": ( "A bystander once noted that George used to raise llamas on a small patch of land adjacent to his current fruit farm. " "While this fact has no bearing on his current business dealings, it is often brought up in conversation due to the llama’s quirky behavior." ), "uuid": "44444444-dddd-eeee-ffff-000000000004", "render_name": "llama_memoirs.txt", "source_data": { "url": "https://example.com/llamas", "filename": "llama_memoirs.txt", "file_type": "txt", "document_uuid": "doc-004" } } ] SYSTEM_PROMPT = ( "You are a helpful assistant. Use the provided excerpts to fully analyze and answer the user's question. " "If any information is irrelevant, do not cite it or mention it. Think carefully and show clear reasoning." ) QUERY = "Can Natalie afford to buy all of George's grapes and also buy strawberries?" # ------------------------------- # Call function # ------------------------------- result = await generate_cited_response( chunks=CHUNKS, system_prompt=SYSTEM_PROMPT, query=QUERY, )And, after running, this is the result we get.
Natalie has $5.45 in total but wants to keep $1.00 for bread, leaving her with $4.45 to spend on George’s fruits <InTextCitation chunkId="22222222-bbbb-cccc-dddd-000000000002" renderName="wallet_and_intentions.txt" url="https%3A//example.com/wallet" filename="wallet_and_intentions.txt" file_type="txt" document_uuid="doc-002"></InTextCitation>. George has three bunches of grapes, which he sells for $0.50 apiece or $1.25 for all three <InTextCitation chunkId="33333333-cccc-dddd-eeee-000000000003" renderName="pricing_policy.txt" url="https%3A//example.com/pricing" filename="pricing_policy.txt" file_type="txt" document_uuid="doc-003"></InTextCitation>. Buying all three bunches would cost Natalie $1.25. George also has a crate of strawberries priced at $3.00 <InTextCitation chunkId="33333333-cccc-dddd-eeee-000000000003" renderName="pricing_policy.txt" url="https%3A//example.com/pricing" filename="pricing_policy.txt" file_type="txt" document_uuid="doc-003"></InTextCitation>. To buy both all the grapes and the strawberries, Natalie would need $1.25 (for grapes) + $3.00 (for strawberries) = $4.25. Since $4.25 is less than the $4.45 she has available to spend, Natalie can indeed afford to buy all of George's grapes and the strawberries and still have money left over for her bread <InTextCitation chunkId="22222222-bbbb-cccc-dddd-000000000002" renderName="wallet_and_intentions.txt" url="https%3A//example.com/wallet" filename="wallet_and_intentions.txt" file_type="txt" document_uuid="doc-002"></InTextCitation>.You might notice that, in the response, in-text citations are populated as custom HTML tags of type
InTextCitation. ThechunkIdandrenderNameare both added as attributes, along with any of the other fields specified in thesource_dataprovided with each chunk. Under the hood, the LLM generates citations based on the chunk_ids associated with each chunk, then thegenerate_cited_responsefunction uses regex expressions to find and replace those ids with richer HTML tags.This simple script processes the result from
generate_cited_responseand rendersInTextCitationas clickable buttons.from IPython.display import display, HTML def render_citations_as_buttons(html: str) -> str: styled_html = f""" <style> intextcitation {{ display: inline-block; background-color: #f0f0f0; color: #222; border: 1px solid #aaa; border-radius: 5px; padding: 2px 6px; margin: 0 3px; font-size: 0.85em; cursor: pointer; }} intextcitation::before {{ content: attr(renderName); }} intextcitation:hover {{ background-color: #ddd; }} </style> <div style="font-family:Arial; line-height:1.6;"> {html} </div> <script> setTimeout(() => {{ document.querySelectorAll("intextcitation").forEach(el => {{ el.addEventListener("click", () => {{ const encodedUrl = el.getAttribute("url"); if (encodedUrl) {{ window.open(decodeURIComponent(encodedUrl), "_blank"); }} }}); }}); }}, 0); </script> """ return styled_html display(HTML(render_citations_as_buttons(result)))
The result of generating in-text citations. Clicking these buttons will open the url associated with each button.
There’s some application-level magic that makes FraudX render PDFs in a window, and produces highlighted sections that are relevent to the particular question being asked, but this system is the essence of how FraudX connects LLM inferences with source material.
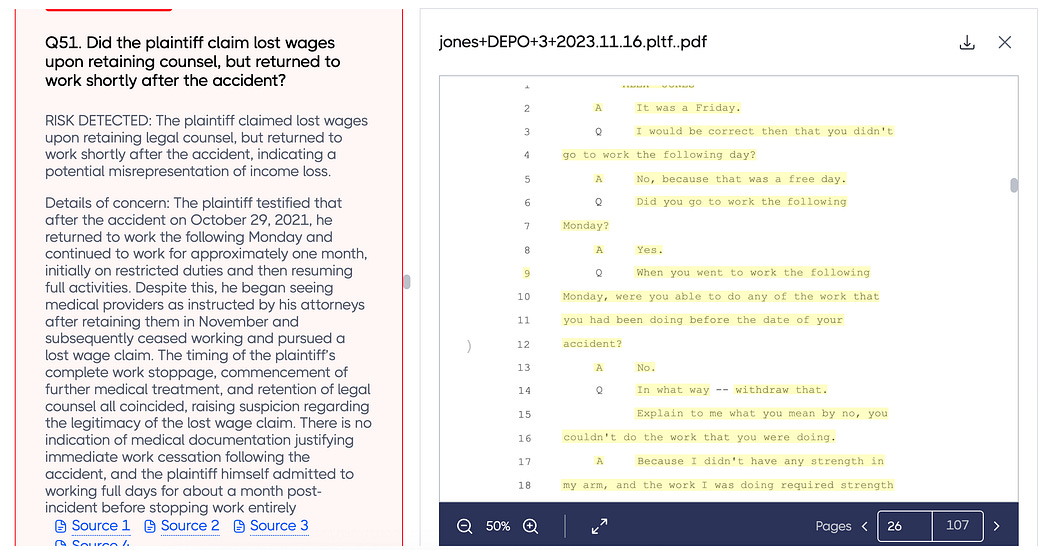
Recall the FraudX Platform. We built a PDF viewer with the ability to highlight key information that is relevent to a particular source. There’s a lot of application specific design decisions one can make when creating an in-text citation system. Now that we have a solid idea of how to create in-text citations, let’s set it up using an actual RAG system.
Creating In-Text Citations With GroundX
In this tutorial, we’ll be using GroundX as our RAG engine, but keep in mind that this general approach will work with virtually any RAG system. The only criterion is that you can generate the list of chunks correctly.
Full code for this example can be found here.
First, we need some documents to play around with. For this example, I’ll be downloading a few research papers from Arxiv.
import arxiv import os # Define target download directory output_dir = os.path.join("temp", "arxiv_papers") os.makedirs(output_dir, exist_ok=True) # List of arXiv IDs and desired filenames papers = { "1706.03762": "attention_is_all_you_need.pdf", # Attention is All You Need "1901.02860": "transformer_xl.pdf", # Transformer-XL "2104.09864": "rope_roformer.pdf", # RoPE (RoFormer) } # Download each paper for arxiv_id, filename in papers.items(): print(f"Downloading {filename} (arXiv:{arxiv_id})...") paper = next(arxiv.Search(id_list=[arxiv_id]).results()) paper.download_pdf(dirpath=output_dir, filename=filename) print("✅ All downloads complete.")To follow this tutorial you’ll need a GroundX account, which has more than enough free tokens to follow along. You can sign up for one here.
Once you have an account and have set up an API key, you can upload documents to GroundX.
"""Creating a bucket and uploading content to it or hard coding an existing bucket ID """ from groundx import GroundX client = GroundX( api_key=os.getenv("GROUNDX_API_KEY"), ) # Creating a bucket response = client.buckets.create( name="test_bucket", ) bucket_id = response.bucket.bucket_id print(f"Created bucket with ID: {bucket_id}") """Uploading downloaded files to the bucket """ client.ingest_directory( bucket_id=bucket_id, path="temp/arxiv_papers", )In GroundX, you can query a bucket of information and get back a list of relevant chunks from all the documents that have been uploaded to that bucket. In the previous code block we uploaded all our documents to a bucket specified by
bucket_id. Now, we can submit a query to thatbucket_id.query = "Describe the main differences between the original transformer, the RoFormer, and the Transformer-XL architectures." context = client.search.content( id=bucket_id, query=query, )Then we get back a bunch of information which we can use for various RAG approaches. One of the elements of the response is
context.search.results, which is a list of all chunks that are relevent to the question. Each chunk has a field calledsuggested_text, which contains a textual description of each chunk. GroundX does a lot of work to turn tables, graphs, figures, and other things into LLM ready data.suggested_textcontains what GroundX thinks each chunk should be textually described as.for result in context.search.results: print('-----------') print(result.suggested_text)The code block above prints all the
suggested_textfor all of the chunks retreived that were relevant to the query. Here’s an example of an individual chunkssuggested_text.{"figure_title":"RoFormer Position Encoding","figure_number":"Figure 1","keywords":"transformer, position encoding, attention mechanism, relative position embedding, absolute position embedding, mathematical equations","summary":"This figure presents equations related to position encoding in transformer models, focusing on both absolute and relative position embeddings. It illustrates how attention scores are computed and how these scores influence the output of the model. The equations provide a mathematical foundation for understanding the RoFormer architecture and its enhancements over traditional methods.","components":["a_{m,n}", "o_m", "q_m", "k_n", "v_n", "P_i", "p_{i,z}", "p_{i,z+1}"],"relationships":[{"source":"query vector q_m","target":"key vector k_n","type":"attention computation"},{"source":"attention scores a_{m,n}","target":"output o_m","type":"weighted sum"}]} {"equation":"a_{m,n} = exp(q_m^T k_n / √d) / Σ_{j=1}^{N} exp(q_m^T k_j / √d)","relationships":[{"source":"q_m","target":"k_n","type":"dot product"},{"source":"a_{m,n}","target":"o_m","type":"output computation"}]} {"equation":"o_m = Σ_{n=1}^{N} a_{m,n} v_n","relationships":[{"source":"a_{m,n}","target":"v_n","type":"weighted sum"},{"source":"o_m","target":"output","type":"final computation"}]} {"equation":"f_t:t∈{q,k,v}(x_i, i) := W_t:t∈{q,k,v}(x_i + P_i)","relationships":[{"source":"x_i","target":"P_i","type":"addition"},{"source":"W_t","target":"context representation","type":"transformation"}]} {"equation":"P_{i,2t} = sin(k / 10000^{2t / d}), P_{i,2t+1} = cos(k / 10000^{2t / d})","relationships":[{"source":"k","target":"P_{i,2t}","type":"sinusoidal encoding"},{"source":"k","target":"P_{i,2t+1}","type":"sinusoidal encoding"}]} {"equation":"f_q(x_m) := W_q x_m, f_k(x_n, n) := W_k(x_n + p_r), f_v(x_n, n) := W_v(x_n + p_r)","relationships":[{"source":"x_m","target":"W_q","type":"query transformation"},{"source":"x_n","target":"p_r","type":"relative position addition"},{"source":"W_k","target":"key transformation"},{"source":"W_v","target":"value transformation"}]} {"equation":"q_m k_n = x_m^T W_q^T W_k x_n + x_m^T W_q^T W_k p_{m-n} + p_m^T W_q^T W_k x_n + p_m^T W_q^T W_k p_{m-n}","relationships":[{"source":"x_m","target":"W_q^T W_k x_n","type":"content-based computation"},{"source":"x_m","target":"W_q^T W_k p_{m-n}","type":"relative position computation"},{"source":"p_m","target":"W_q^T W_k x_n","type":"absolute position computation"},{"source":"p_m","target":"W_q^T W_k p_{m-n}","type":"relative position computation"}]} {"equation":"q_m k_n = x_m^T W_q^T W_k x_n + x_m^T W_q^T W_k p_{m-n} + u^T W_q^T W_k x_n + v^T W_q^T W_k p_{m-n}","relationships":[{"source":"x_m","target":"W_q^T W_k x_n","type":"content-based computation"},{"source":"x_m","target":"W_q^T W_k p_{m-n}","type":"relative position computation"},{"source":"u","target":"W_q^T W_k x_n","type":"trainable vector computation"},{"source":"v","target":"W_q^T W_k p_{m-n}","type":"trainable vector computation"}]} {"equation":"q_m k_n = x_m^T W_q^T W_k x_n + b_{i,j}","relationships":[{"source":"x_m","target":"W_q^T W_k x_n","type":"content-based computation"},{"source":"b_{i,j}","target":"attention weights","type":"bias addition"}]} {"equation":"q_m k_n = x_m^T W_q^T W_k x_n + P_m^T U^T U_k P_n + b_{i,j}","relationships":[{"source":"x_m","target":"W_q^T W_k x_n","type":"content-based computation"},{"source":"P_m","target":"U^T U_k P_n","type":"projection matrix computation"},{"source":"b_{i,j}","target":"attention weights","type":"bias addition"}]} The image contains mathematical equations related to position encoding in transformer models. The first equation computes attention scores \(a_{m,n}\) as the normalized exponential of the dot product between query vector \(q_m\) and key vector \(k_n\), divided by the square root of the dimension \(d\). The second equation calculates the output \(o_m\) as the weighted sum of values \(v_n\) based on the attention scores \(a_{m,n}\). Subsequent equations explore absolute and relative position embeddings. Absolute position embedding adds position vectors \(P_i\) to token representations, with sinusoidal functions used to generate these vectors. Relative position embedding incorporates relative distances between tokens, represented by \(p_r\), into the attention mechanism. Advanced equations decompose the attention computation into content-based and position-based components, introducing trainable vectors \(u\) and \(v\) for greater flexibility. Later refinements include bias terms \(b_{i,j}\) and projection matrices to model relationships between positions and tokens. These equations collectively describe the mathematical foundation of the RoFormer architecture, emphasizing enhancements over traditional position encoding methods.This is a textual block that contains a figures title, and a variety of equations. It also contains a narrative breakdown about what the equations represent, and where they fit in the greater context of the document.
Allong with
suggested_text, GroundX provides a url of the source material, and a page number where the particular reference can be found. Using this data, we can iterate over all chunks provided by GroundX and construct the chunks that we’ll be passing to thegenerate_cited_responsefunction. We’re calling thatcitable_sourcesin this particular code block.import uuid citable_sources = [] for result in context.search.results: #getting the suggested text from each chunk text = result.suggested_text.strip() if not text: continue # Skip empty chunks #getting the page number and url from each chunk page_num = result.bounding_boxes[0].page_number page_url = f"{result.source_url}#page={page_num}" #adding to the citable sources. citable_sources.append({ "text": text, "uuid": str(uuid.uuid4()), "render_name": result.file_name, "source_data": { "url": page_url, "page_number": page_num } })The documents uploaded are pdfs. Most modern browsers can open up pdf files. Furthermore, if you add
#page=<page number>to the url, most browsers will open the PDF at the specified page; allowing our in-text citations to snap directly to the page of the PDF that the LLM is referencing.GroundX also returns more sophisticated data, like bounding boxes, which can be used to annotate the PDF and highlight the specific information that the LLM is referencing. Feel free to check out our RAG visualization tool XRay if you’re curious. For now, though, we’ll keep it simple and just use page numbers.
So, with that, we constructed citable references based on GroundX retrievals, which were retrieved based on the query from the user. Now we can pass those results into
generate_cited_responseand create our LLM response with in-text citations.result = await generate_cited_response( chunks=citable_sources, system_prompt=( "You are a helpful assistant. Use the provided excerpts to fully analyze and answer the user's question. " "You must rely only on information from the excerpts, and cite every excerpt you used using the $REF: ID$ format. " "If any information is irrelevant, do not cite it or mention it. Think carefully and show clear reasoning." "the final answer should be separated by the rationale by a paragraph break. The rationale should not include newlines." ), query=query ) display(HTML(render_citations_as_buttons(result)))
Those in-text citations are clickable links that will open the relevant page of a PDF. Before we conclude, let’s peek behind the curtain and explore how
generate_cited_responseworks.A Peek Behind The Curtain
Before we wrap up, let’s explore how the
generate_cited_responseworks. It’s pretty straightforward, the entire implementation can be found here.import os import re from urllib import parse from typing import List, TypedDict, Dict, Any, Optional from langchain_openai import ChatOpenAI from langchain_core.language_models.chat_models import BaseChatModel from langchain_core.messages import SystemMessage, HumanMessage class Chunk(TypedDict): text: str uuid: str render_name: str source_data: Dict[str, Any] def get_openai_api_key() -> str: key = os.getenv("OPENAI_API_KEY", "").strip() if not key or not key.startswith("sk-"): raise ValueError( "Invalid or missing OPENAI_API_KEY environment variable. " "Ensure it exists and starts with 'sk-'." ) return key async def generate_cited_response( chunks: List[Chunk], system_prompt: str, query: str, llm: Optional[BaseChatModel] = None, ) -> str: if llm is None: llm = ChatOpenAI( model="gpt-4o", api_key=get_openai_api_key(), ) ref_mapping = {} chunk_texts = [] for ref in chunks: full_uuid = ref["uuid"] chunk = ref["text"] chunk_texts.append(f"**ID:** {full_uuid}\n**Text:** {chunk}\n") ref_mapping[full_uuid] = ref.copy() context = "\n---\n\n".join(chunk_texts) if chunk_texts else "" human_prompt = f""" I am going to ask a question in my next message. Here are some excerpts uniquely identified by an ID that may or may not be relevant. You need to perform 2 tasks: 1) Generate a response to answer the question. If these excerpts relate to my question, use them in your response. If not, ignore them, and rely on our conversation context. 2) If any excerpt is used, generate in-text citation using the excerpt ID as follows - $REF: ID$. The formatting must be strictly followed. For example, if excerpt corresponding to ID 03b994bc-2fae-4e1e-a4cd-f0f3e6db2d90 is used in generating the response, source attribution must be - $REF: 03b994bc-2fae-4e1e-a4cd-f0f3e6db2d90$ Strictly follow the instructions of the above tasks. Do not mention whether the content or previous context was used or not; respond seamlessly. Avoid phrases like "the provided content" or similar. Take into account everything we've discussed so far, without assuming everything is relevant unless it clearly supports your answer. ----- {context} """ answer = await llm.ainvoke( input=[ SystemMessage(content=system_prompt), HumanMessage(content=human_prompt), HumanMessage(content=query), ] ) answer = answer.content pattern = r"\$REF: ([a-f0-9\-]+)\$" for match in re.finditer(pattern=pattern, string=answer): to_replace = match.group() ref_id = match.groups()[0] if ref_id in ref_mapping: ref = ref_mapping[ref_id] props = { "chunkId": ref["uuid"], "renderName": ref["render_name"], **ref.get("source_data", {}), } prop_str = " ".join( f'{key}="{parse.quote(str(value))}"' for key, value in props.items() ) citation = f'\n<InTextCitation {prop_str}></InTextCitation>' answer = answer.replace(to_replace, citation) else: answer = answer.replace(to_replace, "") return answerFirst, this function takes our chunks, along with their corresponding UUID, and constructs a textual context that ties each chunk with a corresponding id.
ref_mapping = {} chunk_texts = [] for ref in chunks: full_uuid = ref["uuid"] chunk = ref["text"] chunk_texts.append(f"**ID:** {full_uuid}\n**Text:** {chunk}\n") ref_mapping[full_uuid] = ref.copy() context = "\n---\n\n".join(chunk_texts) if chunk_texts else ""This function also constructs a map between the UUID and the original chunk,
ref_mapping, allowing us to more easily inject HTML tags in post-processing.This context is added to the end of another prompt, which describes how the LLM should format in-text citations.
human_prompt = f""" I am going to ask a question in my next message. Here are some excerpts uniquely identified by an ID that may or may not be relevant. You need to perform 2 tasks: 1) Generate a response to answer the question. If these excerpts relate to my question, use them in your response. If not, ignore them, and rely on our conversation context. 2) If any excerpt is used, generate in-text citation using the excerpt ID as follows - $REF: ID$. The formatting must be strictly followed. For example, if excerpt corresponding to ID 03b994bc-2fae-4e1e-a4cd-f0f3e6db2d90 is used in generating the response, source attribution must be - $REF: 03b994bc-2fae-4e1e-a4cd-f0f3e6db2d90$ Strictly follow the instructions of the above tasks. Do not mention whether the content or previous context was used or not; respond seamlessly. Avoid phrases like "the provided content" or similar. Take into account everything we've discussed so far, without assuming everything is relevant unless it clearly supports your answer. ----- {context} """Then, the user-defined system prompt, context with referencing instructions, and user query are passed to the LLM.
answer = await llm.ainvoke( input=[ SystemMessage(content=system_prompt), HumanMessage(content=human_prompt), HumanMessage(content=query), ] ) answer = answer.contentFinally, we iterate through all of the references within the response generated from the LLM. If we find a reference in the text, we replace the reference with an HTML tag that includes the attributes tagged to that particular reference.
pattern = r"\$REF: ([a-f0-9\-]+)\$" for match in re.finditer(pattern=pattern, string=answer): to_replace = match.group() ref_id = match.groups()[0] if ref_id in ref_mapping: ref = ref_mapping[ref_id] props = { "chunkId": ref["uuid"], "renderName": ref["render_name"], **ref.get("source_data", {}), } prop_str = " ".join( f'{key}="{parse.quote(str(value))}"' for key, value in props.items() ) citation = f'\n<InTextCitation {prop_str}></InTextCitation>' answer = answer.replace(to_replace, citation) else: answer = answer.replace(to_replace, "")et voila, in-text citations.
Conclusion
Don’t let the conceptual simplicity of in-text citations fool you. They are incredibly powerful and have a ton of creative use cases. One of the biggest problems with LLM-powered products is hallucination; we simply don’t know when we can trust AI. In-text citations are one of the best approaches to address this problem, making them a critical tool in modern AI application development.









This is a wonderful piece. An interesting solution to a fairly common problem.