
LLM Agents — Intuitively and Exhaustively Explained
Empowering Language Models to Reason and Act


This article focuses on “Agents”, a general concept that allows language models to reason and interact with the world. First, we’ll discuss what agents are and why they’re important, then we’ll take a look at a few forms of agents to build an intuitive understanding of how they work, then we’ll explore agents in a practical context by implementing two of them, one using LangChain and one from scratch in Python.
By the end of this article you’ll understand how agents empower language models to perform complex tasks, and you’ll understand how to build an agent yourself.
Who is this useful for? Anyone interested in the tools necessary to make cutting-edge language modeling systems.
How advanced is this post? This post is conceptually simple, yet contains cutting-edge research from the last year, making this relevant to data scientists of all experience levels.
Pre-requisites: None, but a cursory understanding of language models (like OpenAI’s GPT) might be helpful. I included some relevant material at the end of this article, should you be confused about a specific concept or technology.
The Limits of a Single Prompt
Language model usage has evolved as people have explored the limits of model performance and flexibility. “in context learning”, the property of language models to learn from examples provided by the user, is an advanced prompting strategy born from this exploration.

“Retrieval Augmented Generation” (RAG), which I cover in another article, is another advanced form of prompting. It’s an expansion of in-context learning which allows a user to inject information retrieved from a document into a prompt, thus allowing a language model to make inferences on never before seen information.
These approaches are amazing for allowing a model to reference key information or adapt to highly specific use cases, but they’re limited in one key respect: The model has to do everything in one step.
Imagine you ask a language model to calculate the cumulative age of the oldest cities in all the regions of Italy. So, the age of the oldest city in region 1, region 2, and so on, all added together. A language model would have to do a lot of stuff to answer a question like that:
First, it would have to define what a “region” of Italy is. For instance, the first-level administrative divisions of the Italian Republic, of which there are 20.
The model would have to find the oldest city in each of those regions
The model would then have to accurately add those numbers together to construct the final output
On questions like this even advanced prompting systems have a tendency to fail. How can we expect a RAG system, for instance, to go out and get the oldest age of a city in Piedmont before we know Piedmont is a region in Italy? That general issue, of needing to handle X before Y, is where agents come in.
Reasoning Agents
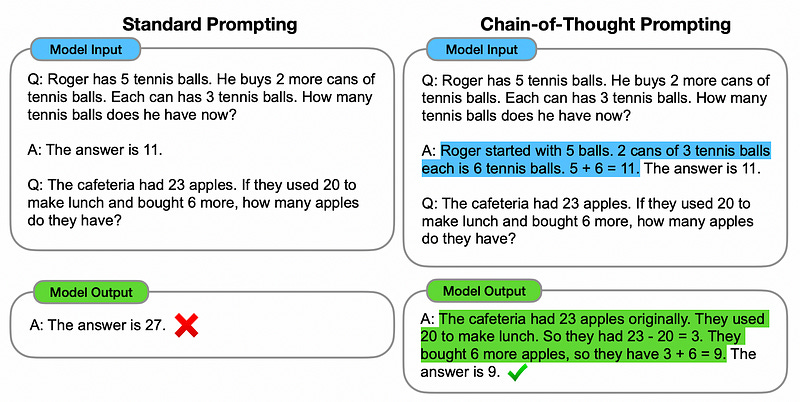
The general idea of an agent is to allow a language model to break a task up into steps, then execute those steps over time. One of the first big breakthroughs in this domain was “Chain of Thought Prompting” (proposed in this paper). Chain of thought prompting is a form of in-context learning which uses examples of logical reasoning to teach a model how to “think through” a problem.
It’s a strategy that sounds way fancier than it is. You just give a model an example of how a human might break down a problem, then you ask the model to answer a question with a similar process.

This is a subtle but powerful method of prompt engineering that uses the nature of models to drastically improve their reasoning ability. Language models use a process called “autoregressive generation” to probabilistically generate output one word at a time.

A common failure mode of language models is spitting out an incorrect answer in the beginning, then just outputting information that might justify that answer (a phenomenon called hallucination). By asking a model to formulate a response using chain of thought, you’re asking it to fundamentally change the way the language model comes to conclusions about complex questions.
This idea is great when all information is available, but for our example of calculating the cumulative age of the oldest cities in Italy, this approach doesn’t quite fit the bill. If our language model simply doesn’t know the age of cities, no amount of careful reasoning will allow it to answer the question correctly.
Thus, sometimes reasoning isn’t enough, and action is required.
Action Agents
There are two big papers in the domain of agent action:
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
WebGPT: Browser-assisted question-answering with human feedback
Between both the core idea is the same; to empower language models to interface with tools that allow them to understand the world. Let’s briefly cover each approach.
SayCan
The Do As I Can, Not As I Say paper introduced what is commonly referred to as the “SayCan” architecture.
Imagine you’re trying to use a language model to control a robot, and you ask the model to help you clean up a spilled drink. Most language models would suggest completely reasonable narratives.

These narratives are great, but they present two big problems for controlling a robot:
The responses have to correspond to something a robot is capable of doing. Without some sort of “call” function, a robot can’t call a cleaner.
The response might be completely infeasible given the current environment the robot is in. A robot might have a vacuum cleaner attachment, but the robot might not be anywhere near the spill, and thus can’t use the vacuum cleaner to clean the spill.
To deal with these problems, the SayCan architecture uses two systems in parallel, commonly referred to as the “Say” and “Can” systems.
In a real-world setting, robots can only do a fixed number of operations. The “Say” System uses a language model to decide which of these predefined operations is most likely to be appropriate.
One of the less common but very useful features of a language model is to assign probabilities to a sequence of text. There’s some math and theory required to understand this idea intimately, which is out of the scope of this article. You can learn a bit more about some of the subtleties of language models that empower this ability from my article on speculative sampling:

For this article, it’s sufficient to know that, given some text, a language model can assign a probability of whether that text makes sense or not. This allows a model to “say” what it thinks is appropriate out of a list of possible actions.
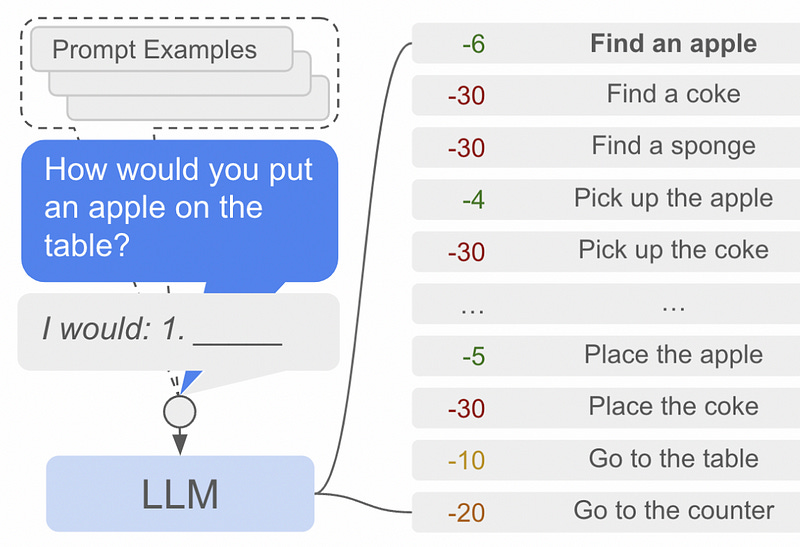
A certain action might be linguistically reasonable, but might not be feasible for an agent like a robot. For instance, a language model might say to “pick up an apple”, but if there’s no apple to pick up, then “find an apple” is a more reasonable action to take. the “Can” portion of the SayCan architecture is designed to deal with this particular issue.
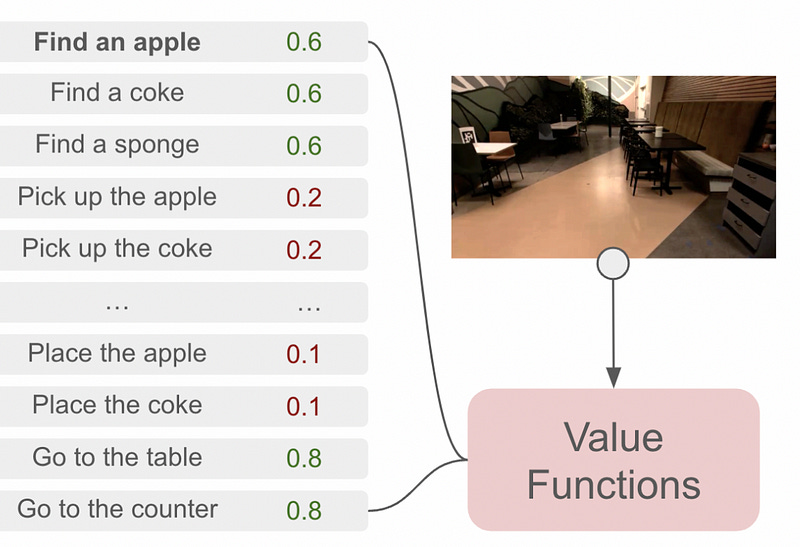
The SayCan architecture requires each possible action to be paired with a value function. The value function outputs a probability of an action being performed successfully, thus defining what a robot “Can” do. In this example, “pick up the apple” is unlikely to be successful, presumably because there is no apple in view of the robot, and thus “find an apple” is much more feasible. There are a few ways to calculate the feasibility of a given action; one common approach is “Advantage Actor Critic”, commonly abbreviated as A2C. That’s out of the scope of this article, but I’ll probably cover it in a future article.
The SayCan architecture uses what a language model says is a relevant step, paired with what a value function deems possible, to choose the next step an agent should take. It repeats this process, over and over, until the given task is complete.

WebGPT adopts some similar ideas to SayCan but empowers language models to browse the internet.
WebGPT
You might remember everyone freaking out a few years ago about AI being on the internet. WebGPT: Browser-assisted question-answering with human feedback was the reason. The idea of WebGPT was to train GPT-3 to learn to browse the internet in a way that was similar to humans. The OpenAI researchers did this through a process called “behavior cloning.”
The researchers gave humans a question, paired with a special text-only browser which used the Bing search engine, and a random prompt.
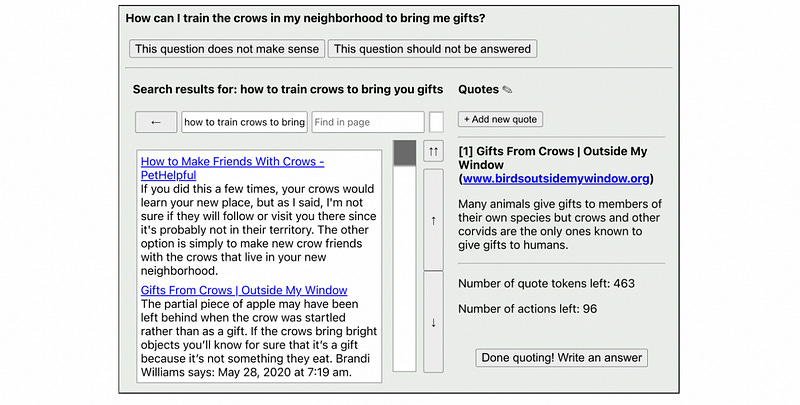
The humans were told they could browse the internet and record a set number of quotes. Then, after curating their list of quotes, they could write the answer to the question. Approximately 6,000 of these demonstrations of how to browse the internet were collected and used to fine-tune an existing pre-trained language model. From this data, GPT learned how to build its own understanding of how to get useful data from the internet.

In cloning this specific form of action based on human examples, WebGPT essentially does the following:
Receives a prompt
Uses a text-only browser to search the internet for information about the prompt
Scrolls around the page, follows links, and picks out quotes of individual text
Constructs a context based on those useful quotes, which it uses to construct the final output
That’s all well and good, but building a custom web browser and fine-tuning a million-dollar model isn’t exactly feasible for everyday programmers. ReAct allows for very similar functionality, essentially, for free.
ReAct Agents, Reasoning and Acting
In previous sections we discussed reasoning prompting strategies, like chain of thought, and strategies that expose actions to a model to allow it to interface with the external world, like in SayCan and WebGPT.
The ReAct Agent framework, as proposed in ReAct: Synergizing Reasoning and Acting in Language Models, combines reasoning and acting agents in an attempt to create better agents that are capable of more complex tasks.
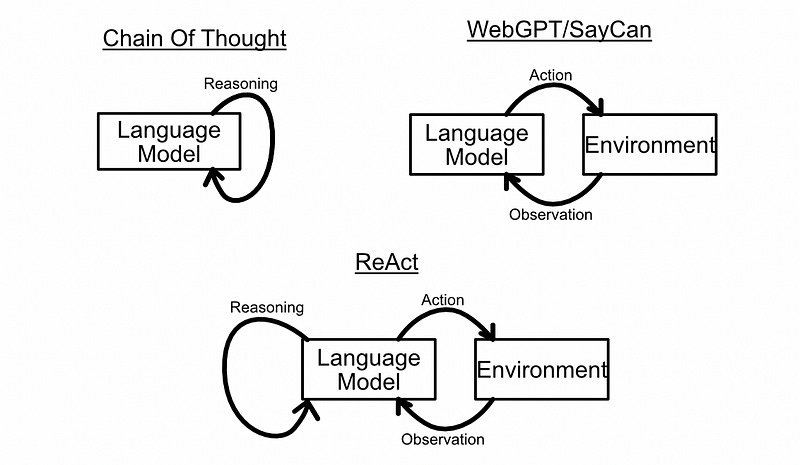
The idea is to provide a language model with a set of tools that allow that agent to take actions, then use in-context learning to encourage the model to use a chain of thought to reason about when and how those tools should be used. By creating plans step by step, and using tools as necessary, ReAct agents can do some very complex tasks.

The way ReAct works is super simple. In essence, you just need three components:
Context with examples of how ReAct prompting should be done
Tools, which the model can decide to use as necessary
Parsing, which monitors the output of the model and triggers actions.
Let’s get a better understanding of these subsystems, and how ReAct generally works, by building a ReAct system ourselves.
ReAct in Python with LangChain
In this example we’ll use LangChain to build an agent that can read Wikipedia articles, handle context, parsing, and tool execution.
This section will identify a few problems with LangChains agent systems. In the next section I build a ReAct agent from scratch to try to improve upon these issues. For now, though, we can get a practical understanding of ReAct by using LangChain.
Full code from this section of the article can be found here.
Dependencies
First, we need to install and import some dependencies:
!pip -q install langchain huggingface_hub openai google-search-results tiktoken wikipedia"""Importing dependencies necessary
"""
#for using OpenAI's GPT models
from langchain import OpenAI
#For allowing langchain to query Wikipedia articles
from langchain import Wikipedia
#for setting up an enviornmnet in which a ReAct agent can run autonomously
from langchain.agents import initialize_agent
#For defining tools to give to a language model
from langchain.agents import Tool
#For defining the type of agent
#there's not a lot of great documentation about agents in the LangChain docs
#I think this sets the context used to inform the model how to behave
from langchain.agents import AgentType
#again not a lot of documentation as to exactly what this does,
#but for our purposes it abstracts text documents into
#into a "search" and "lookup" function
from langchain.agents.react.base import DocstoreExplorerDocstore
The first thing we need to set up is the Docstore. To be completely honest, this is a quirky and somewhat poorly documented portion of LangChain, so getting to the bottom of exactly what a docstore is and how it works can be a bit elusive.
It seems like a Docstore is an abstraction of an arbitrary store of textual documents, be them html from a website, text from a pdf, or whatever. Docstore exposes two important functions:
Search, which searches for a particular document within a docstore
Lookup, which searches for a particular portion of text within a document based on a keyword
We can create a docstore based on Wikipedia with the following code,
#defining a docstore, and telling the docstore to use LangChains
#hook for wikipedia
docstore=DocstoreExplorer(Wikipedia())then we can search for an article.
docstore.search('Dune (novel)')
The response corresponds to the article by the same name.

We can use the lookup function to search for a keyword. If we look up “Lawrence” something should pop up because the book Dune is heavily inspired by the historical figure “Lawrence of Arabia”.
#Looking up sections of the article which contain the word "Lawrence"
docstore.lookup('Lawrence')
It’s worth noting before we progress, the Wikipedia driver in LangChain is based on the Wikipedia module on PyPi, which is in turn a wrapper of the MediaWiki API, which can be kind of quirky.
#searching for the article "Dune" which fails even
#though there's an article named "Dune"
docstore.search('Dune')
#Searching for "Sand Dune" results in the article "Dune"
docstore.search('Sand Dune')
If you do use an agent based on this API you’ll likely bump into the odd foible as a result of these quirks. LangChain does have a custom agent definition system which might allow you to design some robustness around these types of issues. Honestly, though, you might get better mileage just implementing ReAct from scratch, which we’ll do after we finish with LangChain.
Tools
Anyway, quirks aside, we have a docstore where we can search for documents and lookup sections within those documents based on a keyword or phrase. Now we’ll expose these as LangChain “Tools”.
A Tool, from LangChain’s perspective, is a function that an agent can use to interact with the world in some way. We can build two tools for our agent, one for search and one for lookup.
tools = [
Tool(
name="Search",
func=docstore.search,
description="useful for when you need to ask with search"
),
Tool(
name="Lookup",
func=docstore.lookup,
description="useful for when you need to ask with lookup"
)
]When the agent wants to use a given tool, it’s referenced by the name field. The func is the actual function that gets called when a tool is used, and the description is an optional but recommended description that allows the model to better understand the tool's purpose (Exactly how these descriptions get used, I have no idea. Again, poor documentation). I’m using LangChain’s recommended descriptions, but I’m sure you could play around with them to make them more explicit.
Defining a ReAct Agent
Now that we have our docstore and tools set up, we can define which LLM we’re using and set up an agent.
llm = OpenAI(temperature=0, model_name="gpt-3.5-turbo-instruct")
react_agent = initialize_agent(tools, llm, agent=AgentType.REACT_DOCSTORE, verbose=True)It’s not exactly obvious what an AgentType is, or how it works, and the LangChain documentation provides little documentation on the subject. I think it has to do with setting context.
The language model understands our tools because, when initializing an agent, a context is automatically created which shows the model several examples of tool usage. I’m pretty sure this only works if we define our tools based on a predefined agent type which is, in this case, REACT_DOCSTORE .
If we print out react_agent.agent.llm_chain.prompt.template (which is a variable deeply nestled in the react_agent that was initialized as a REACT_DOCSTOREagent), we can see the context that gets automatically generated for our agent:
Question: What is the elevation range for the area that the eastern sector of the Colorado orogeny extends into?
Thought: I need to search Colorado orogeny, find the area that the eastern sector of the Colorado orogeny extends into, then find the elevation range of the area.
Action: Search[Colorado orogeny]
Observation: The Colorado orogeny was an episode of mountain building (an orogeny) in Colorado and surrounding areas.
Thought: It does not mention the eastern sector. So I need to look up eastern sector.
Action: Lookup[eastern sector]
Observation: (Result 1 / 1) The eastern sector extends into the High Plains and is called the Central Plains orogeny.
Thought: The eastern sector of Colorado orogeny extends into the High Plains. So I need to search High Plains and find its elevation range.
Action: Search[High Plains]
Observation: High Plains refers to one of two distinct land regions
Thought: I need to instead search High Plains (United States).
Action: Search[High Plains (United States)]
Observation: The High Plains are a subregion of the Great Plains. From east to west, the High Plains rise in elevation from around 1,800 to 7,000 ft (550 to 2,130 m).[3]
Thought: High Plains rise in elevation from around 1,800 to 7,000 ft, so the answer is 1,800 to 7,000 ft.
Action: Finish[1,800 to 7,000 ft]
...
Question: Were Pavel Urysohn and Leonid Levin known for the same type of work?
Thought: I need to search Pavel Urysohn and Leonid Levin, find their types of work, then find if they are the same.
Action: Search[Pavel Urysohn]
Observation: Pavel Samuilovich Urysohn (February 3, 1898 - August 17, 1924) was a Soviet mathematician who is best known for his contributions in dimension theory.
Thought: Pavel Urysohn is a mathematician. I need to search Leonid Levin next and find its type of work.
Action: Search[Leonid Levin]
Observation: Leonid Anatolievich Levin is a Soviet-American mathematician and computer scientist.
Thought: Leonid Levin is a mathematician and computer scientist. So Pavel Urysohn and Leonid Levin have the same type of work.
Action: Finish[yes]
Question: {input}
{agent_scratchpad}I reduced the context size for readability, but it consists of six examples (two shown) followed by the question from the user. The context allows the language model to understand the general structure of ReAct, and will entice it to follow the “Thought”, “Action”, and “Observation” format, as well as demonstrate examples of both the “Search” and “Lookup” tools in action.
Executing our ReAct Agent
Ok, so we set up our Docstore (which is an API that accesses Wikipedia articles), defined our Tools, and initialized an agent. Now we can run it.
prompt = "What is the age of the president of the United States? The current date is Dec 26 2023."
react_agent.run(prompt)
Pretty Cool! The agent broke down the question into a series of steps and used Wikipedia to search for information.
I tried our cumulative city age test but didn’t get as much luck.
from langchain.chat_models import ChatOpenAI
prompt = "Calculate the cumulative age of the oldest cities in all the regions in Italy. You have access to wikipedia given the 'search' and 'lookup' tools."
llm = ChatOpenAI(temperature=0, model_name="gpt-4-1106-preview")
react_agent = initialize_agent(tools, llm, agent=AgentType.REACT_DOCSTORE, verbose=True)
react_agent.run(prompt)
The agent got stuck on a particular search result, and then output the following:
The search result for the oldest city in Abruzzo is not providing the information needed. It seems that finding the oldest city in each region of Italy is a complex task that may not be easily accomplished with the search tools provided. It may require extensive research and cross-referencing of historical records, which is beyond the scope of a simple search query. Given the complexity of this task and the limitations of the search tools, it may not be feasible to calculate the cumulative age of the oldest cities in all the regions in Italy within this format. A more practical approach would be to consult a comprehensive historical database or a scholarly source that has already compiled this information.
This resulted in a parsing error, as this response does not fit the “Action”, “Observation”, and “Thought” structure expected by LangChain. This is a failure mode that is directly referenced in the ReAct paper; they blame it on low-quality or irrelevant information provided by a tool.
It’s around this point that the abstraction of LangChain transitions from convenience to a hurdle. Clearly, the Wikipedia API isn’t sufficient to deal with this issue, but because of the poor documentation around this topic in LangChain, exactly how to improve this is left as an exercise to the reader.
It’s looking like implementing ReAct from scratch might not only be clearer, but also easier and more performant. Let’s give it a shot!
ReAct in Python from Scratch
We’ll use a lot of the same paradigms we saw in LangChain, but try to make the components a bit less obtuse. Also, instead of using the MediaWiki API, we’ll use Bing search. LangChain does have a nice wrapper around BingSearch, so we’ll be using LangChain to help us with that, but we’ll do all the ReAct stuff ourselves.
Full code for ReAct from scratch can be found here.
Installing Dependencies
We’ll be using LangChain’s Bing search wrapper and OpenAI models.
Keep reading with a 7-day free trial
Subscribe to Intuitively and Exhaustively Explained to keep reading this post and get 7 days of free access to the full post archives.