


CRAG — Intuitively and Exhaustively Explained
Defining the limits of retrieval augmented generation


In this article we’ll discuss Meta’s “Comprehensive RAG Benchmark” (CRAG), a new benchmark which seems postured to revolutionize the state of Retrieval Augmented Generation (RAG).
First, we’ll briefly cover RAG, why it’s important, and some of its limitations. We’ll then discuss CRAG, the reason it exists, and why CRAG signifies a fundamental shift in not only RAG, but AI as a whole.
Who is this useful for? Anyone who wants to understand the current trajectory of AI, and how it will evolve.
How advanced is this post? This article is conceptually simple, but concerns some of the most cutting-edge trends in AI.
Pre-requisites: None.
Attribution: I talk about this topic in the following YouTube video:
A Brief Introduction to Retrieval Augmented Generation
Before we discuss CRAG, we should first discuss “Retrieval Augmented Generation” (RAG). I have a dedicated article on this subject, but we’ll explore the high-level concept briefly.

The idea of Retrieval Augmented Generation is to supplement a language model with some information so it can provide better answers. In RAG, this supplemental information is provided to the language model by combining a user’s query with supplemental information into a single prompt, which is sometimes referred to as “Prompt Augmentation”
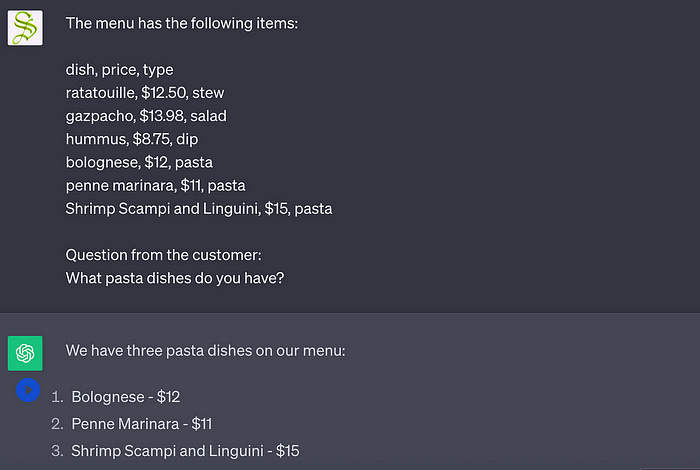
In “Retrieval Augmented Generation” A system called a “retriever” is used to automatically extract relevant information from a store of knowledge based on the user's query. You give the retriever a question, and it attempts to find all the relevant information in a knowledge base that answers your question. Then, whatever the retriever retrieves is used, along with the user's query, to construct the augmented prompt.
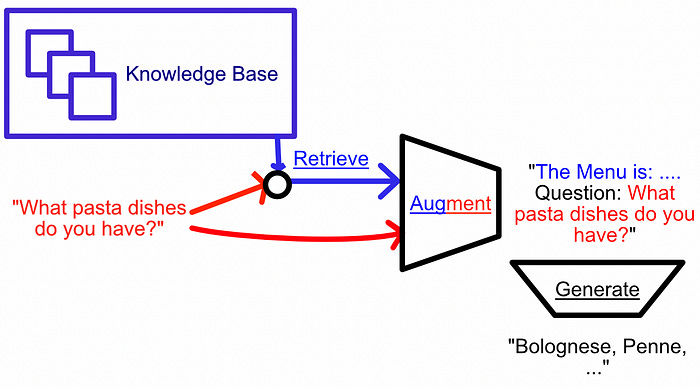
There are many ways to actually do retrieval, but the most common approach is through distance calculations. Basically, you first use something called an encoder to convert all the bits of knowledge in the knowledge base into vectors.

I talk a lot more about embeddings in this article, if you’re curious about digging a bit deeper:

Once the user’s query and information in the knowledge base are embedded into vectors, the distance between the vector derived from the query and the vector derived from a particular piece of information can be calculated.

This general process is how most RAG systems retrieve relevant information to a user's query.
The Point of RAG
The functionality of RAG which enables a language model to answer queries based on information in a document store has garnered a lot of attention from business circles. Language models are expensive to train, and it’s difficult to make a tailored language model for your company's needs, so RAGs promise of being able to feed information into a language model, after that language model has been trained, makes it a compelling technology for business use cases. Interestingly, though, this use case isn’t actually the reason RAG was invented.
The original RAG paper, Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, holds the ability to update a model’s information as a secondary objective, while, first and foremost, it focuses on improving the performance of the model:
(a language model’s) ability to access and precisely manipulate knowledge is still limited, and hence on knowledge-intensive tasks, their performance lags behind task-specific architectures. Additionally, providing provenance for their decisions and updating their world knowledge remain open research problems. — from the RAG paper
A core idea of the RAG paper is that language models are good at plausibly stating information, but they’re actually bad at recalling specific facts they’ve been trained on. The authors of the RAG paper cited a paper called The Next Decade in AI: Four Steps Towards Robust Artificial Intelligence as a key inspiration, which claims that “robust artificial intelligence” is the next major milestone in AI.
Let us call that new level robust artificial intelligence: intelligence that, while not necessarily superhuman or self-improving, can be counted on to apply what it knows to a wide range of problems in a systematic and reliable way, synthesizing knowledge from a variety of sources such that it can reason flexibly and dynamically about the world, transferring what it learns in one context to another, in the way that we would expect of an ordinary adult. — From The Next Decade in AI
This is a big and bold objective, and is the main focus of the original RAG paper. While businesses have jumped on the functionality of knowledge portability, that’s really just a happy accident from a research prospective. The main point of RAG is to improve the performance, reliability, and robustness of AI systems.
One must also contrast robust intelligence with what I will call pointillistic intelligence, intelligence that works in many cases but in fails in many other cases, ostensibly quite similar, in somewhat unpredictable fashion. — From The Next Decade in AI
Anybody who closely follows the AI literature will realize that robustness has eluded the field since the very beginning. Deep learning has not thus far solved that problem, either, despite the immense resources that have been invested into it. — From The Next Decade in AI
In the words of a team of Facebook AI researchers (Nie et al., 2019) “A growing body of evidence shows that state-of-the-art models learn to exploit spurious statistical patterns in datasets… instead of learning meaning in the flexible and generalizable way that humans do.” — From The Next Decade in AI
In a webinar with Patrick Lewis, one of the co-authors of the RAG paper, he was asked if industry or academia was a better source of state of the art models in terms of performance (around the 1:13:00 mark). He said what I’ve heard many researchers say; the objective of research isn’t to create state of the art models, it’s to discover better ways of modeling.
It’s very easy just to throw a ton of GPUs at a problem and brute force your solution out, and you’ll get great numbers, and I’m like hurray for you. Not to specifically attack open AI but I, for one, am not that interested in GPT 3 for that reason. It was obvious that would happen (you would get good performance with a massive model). — From a webinar with Patrick Lewis, a co-author of RAG
I think this general understanding, that RAG is chiefly for improving performance, reliability, and robustness from a research perspective, is critical in understanding what CRAG is and why it exists.
A Brief Introduction to Knowledge Graphs
Both the CRAG and RAG papers reference knowledge graphs heavily. Basically, on the internet, there are a lot of things that have complex relationships to other things. A knowledge graph is a way of storing those entities and relationships.

{kind=link}
Knowledge graphs have been the go-to mechanism for storing complex relationships for a long time. While language models kind of learn these relationships, one of the big ideas of RAG is to, perhaps, use these explicit high quality knowledge graphs to supplement the abilities of a language model.
The CRAG Benchmark
The CRAG benchmark is a diverse set of 4,409 questions, with corresponding human annotated answers, along with supporting references. The idea is to be a “Comprehensive RAG Benchmark”, hence the name.
The CRAG Benchmark focuses in on two key problems:
Problem 1) LLMs are bad at answering questions about facts that change over time, even if they’ve been trained on the correct answer. This is because LLMs are statistical models, and might be confused when confronted with questions which have multiple seemingly plausible answers.
Studies have shown that GPT-4’s accuracy in answering questions referring to slow-changing or fast-changing facts is below 15% — The CRAG paper
Problem 2) LLMs are bad at answering questions about less popular topics, presumably because those topics don’t show up very much in the dataset. In making this claim they chiefly reference the paper Head-to-Tail: How Knowledgeable are Large Language Models (LLMs)? A.K.A. Will LLMs Replace Knowledge Graphs?, in which they asked a variety of questions to GPT-4, with varying degrees of popularity and specificity. They found that language models are not knowledgeable enough to replace traditional databases like Knowledge graphs.

The CRAG benchmark consists of questions which LLMs have likely seen answers to in their training set, but none the less can’t accurately answer, because the reality is that LLMs are not a replacement for things like knowledge graphs.

Each of the questions in the CRAG benchmark is paired with information that can answer those questions. The CRAG benchmark provides that information in three ways:
Up to five web pages for each question, where the web page is likely, but not guaranteed, to be relevant to the question.
Keep reading with a 7-day free trial
Subscribe to Intuitively and Exhaustively Explained to keep reading this post and get 7 days of free access to the full post archives.