
Sora — Intuitively and Exhaustively Explained
A new era of cutting-edge video generation


In this post we’ll discuss Sora, OpenAI’s new cutting edge video generation model. We’ll start by describing the fundamental machine learning technologies Sora builds off of, then we’ll discuss information available on Sora itself, including OpenAI’s technical report and speculation around it. By the end of this article you’ll have a solid understanding of how Sora (probably) works.

Who is this useful for? Anyone interested in generative AI.
How advanced is this post? This is not a complex post, but there are a lot of concepts, so this article might be daunting to less experienced data scientists.
Pre-requisites: Nothing, but some machine learning experience might be helpful. Feel free to refer to linked articles throughout, or the recommended reading at the end of the article, if you find yourself confused.
Defining Sora
Before we dig into the theory, let’s define Sora from a high level.
Sora is a generative text to video model. Basically, it’s a machine learning model that takes in text and spits out video.
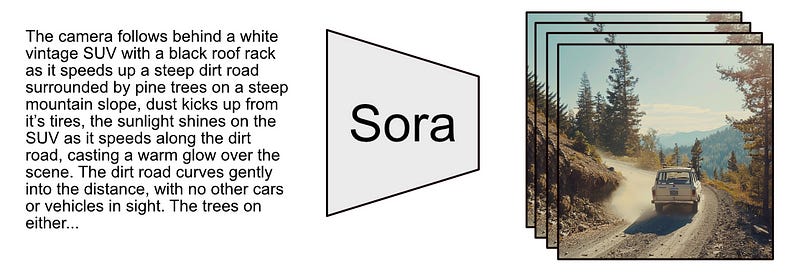
The first big concept we have to tackle to understand Sora is the “Diffusion Model”, so let’s start with that.
Diffusion Models
To create a diffusion model, AI researchers take a bunch of images and create multiple versions of them, each with progressively more and more noise.

Researchers then use those noisy images as a training set, and attempt to build models that can remove the noise the researchers added.

Once the model learns to get really good at turning noise into images, it can be used to generate new images based on random noise.
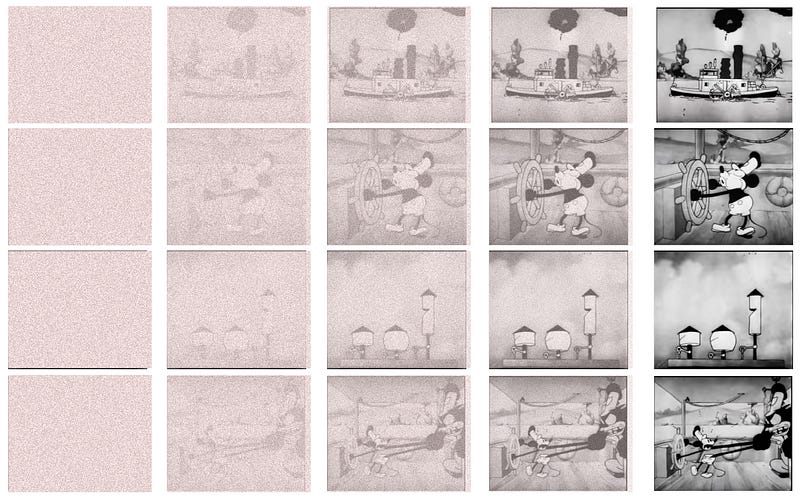
Instead of working on just images, diffusion models are trained on captioned images. We make the images progressively noisy, tell the model the caption, and train the model to generate the original image based on the caption.

This trains diffusion models to generate new images based on text, allowing users to enter in their own text to generate custom images.

So that’s the idea of a diffusion model in a nutshell; they take in text, and use that text to turn noise into images. Sora uses a variation of the diffusion model called a “Diffusion Transformer”, we’ll break that down in the next section.
Diffusion Transformers
Diffusion transformers are a type of diffusion model that uses a specific architecture to actually turn noise into images. As their name implies, they use the “transformer” architecture.
The transformer was originally introduced as a language model for English to French translation, and has since exploded into virtually every machine learning discipline out there.
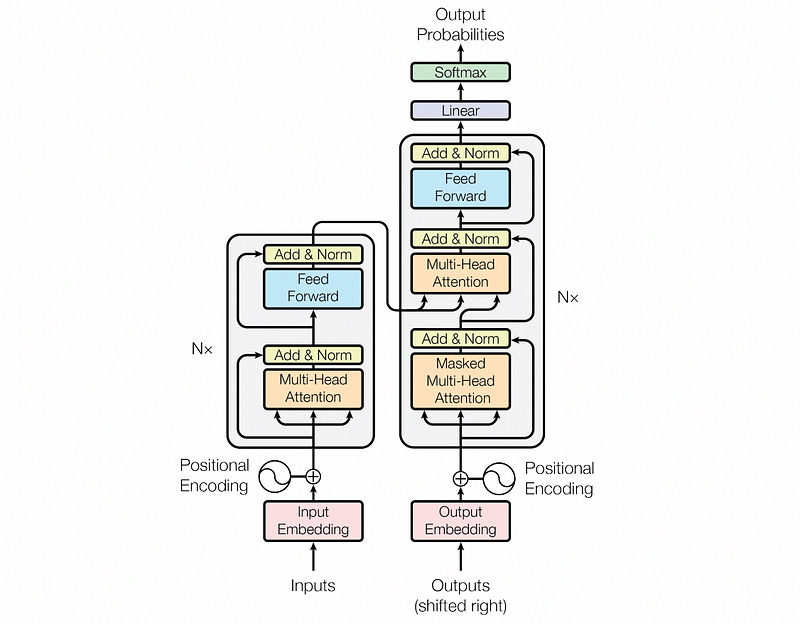
GPT (as in ChatGPT) pioneered the “decoder only transformer”, which is a modification of the original transformer that kind of acts like a filter. You put stuff in, and you get stuff out. It does this by using a subcomponent of the original transformer stacked on top of eachother a bunch of times.

After the success of GPT, people started wondering what else decoder only transformers are good at. It turns out, the answer is a lot. Transformers are really good at a lot of different things. Naturally, with the success of transformers, people wanted to see what happened if you tried to use them for diffusion.
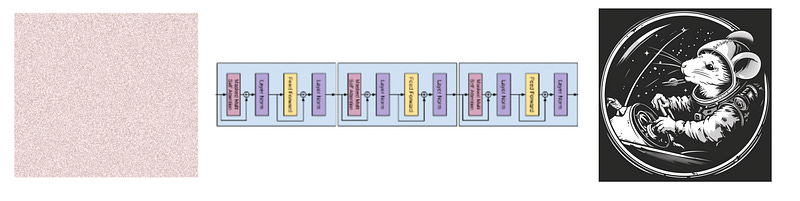
The results were shockingly good, entering us into the era of large scale and performant image generation tools like Stable Diffusion and MidJourney.

To understand diffusion transformers, one has to understand decoder only transformers like GPT. Knowing that will give us a glimpse as to how Sora works. Let’s dig into it.
Decoder Only Transformers (GPT)
Decoder only transformers are one of the key predecessors of the diffusion transformer.
If we really wanted to understand everything about transformers we’d go back to the Attention Is All You Need paper. I cover that paper in a separate article:

I think we can skip ahead a little bit, for the purposes of this article, and look at the immediate successor of the transformer: the “Generative Pre-Trained Transformer”, which was introduced in the paper Improving Language Understanding by Generative Pre-Training. I cover the generative pre-trained transformer in this article:

The basic idea of the GPT model is to use a piece of a transformer to do only next word prediction. Just, really, really well.

Let’s take a high level look at the architecture of GPT to get an idea of how it works under the hood.
First the input words are “embedded” and “encoded”. Basically:
Embedding: Words are hard to do math on, but vectors of numbers are easy to do math on. So, each word is converted to some vector that represents that word.
Encoding: Transformers have a tendency to mix up inputs, so it’s common to add some additional information to the vectors so the transformer can keep track of what order the words had. This is called “positional encoding”
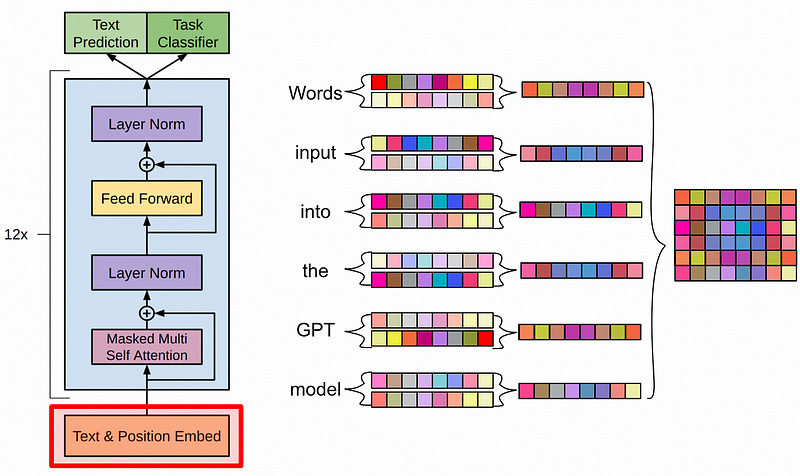
After the inputs are set up, the real magic happens; self attention. Self attention is a mechanism where words in the input are co-related with other words in the input, allowing the model to build a highly contextualized and abstract representation of the entire input.
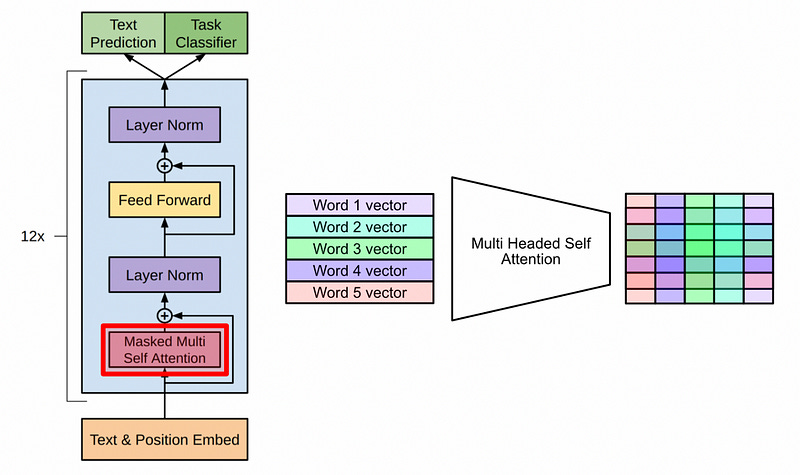
Some other stuff happens to keep things coacher (we’ll cover layer norm later), and then this process happens over and over again.

Essentially, the GPT model (which is a decoder-only transformer) gets really good at creating very sophisticated representations of the input by comparing the input with itself, over and over again, in a super big model.
In GPT that was to do next word prediction, but of course in Sora we care about images. Let’s take a look at vision transformers to get an idea of how this process was adopted to work with images.
Vision Transformers (ViT)
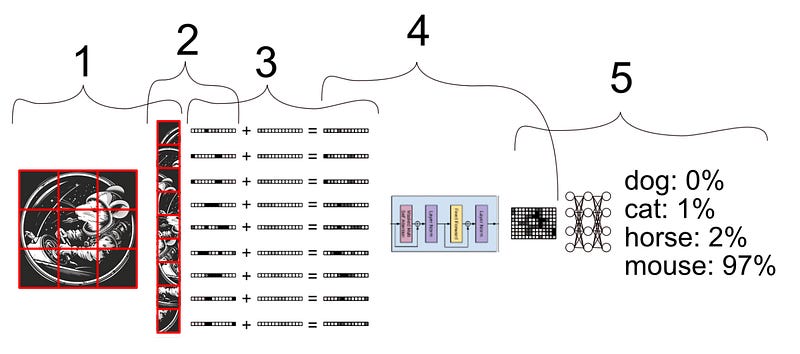
The core idea of vision transformers is actually super simple once you understand GPT. Basically, instead of providing words as the input, you provide chunks of an image as the input. Instead of asking the model to predict the next word, you ask it to predict something based on the image.
This idea comes from the landmark paper An Image is Worth 16x16 Words, which introduced the general concept of the image transformer. In that paper they used a transformer to look at images and predict if they’re of a dog or a chair or whatever.
In that paper, they basically just did the following:
Broke images into patches
Flattened those patches into vectors
Added some information about where in the image the chunks came from (positional encoding)
Passed those vectors through a transformer
Took the output, put it into a dense neural network, and predicted what was in the image.
Of course, there’s a bunch of details I’m glossing over, I’m excited to cover vision transformers in isolation at some point, but for now let’s take a look at how vision transformers were co-opted from classifying images to working within a diffusion context to generate images.
The Architecture Behind Diffusion Transformers
Now that we have an idea of what a transformer is, and how images get applied to transformers via the vision transformer, we can start digging into the nuts and bolts of diffusion transformers.
The paper Scalable Diffusion Models with Transformers was the landmark paper which popularized transformers in diffusion models. From it’s highest level, the paper takes the pre-existing vision transformer, and the pre-existing idea of diffusion models, and combines them together to make a diffusion model which leverages transformers.
In thinking about this from a high level, two key questions arise:
How do we get a prompt into the transformer, so we can tell the transformer what image we want it to generate?
How do we get the model to output a less noisy image?
I’m planning on covering diffusion transformers in isolation in a future article. For now, Let’s cover each of these questions from a high level so we can build the intuition necessary to understand Sora.
How do we get a prompt into the transformer, so we can tell the transformer what image we want it to generate?
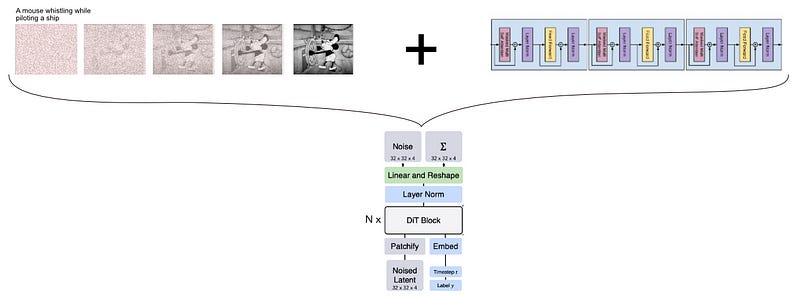
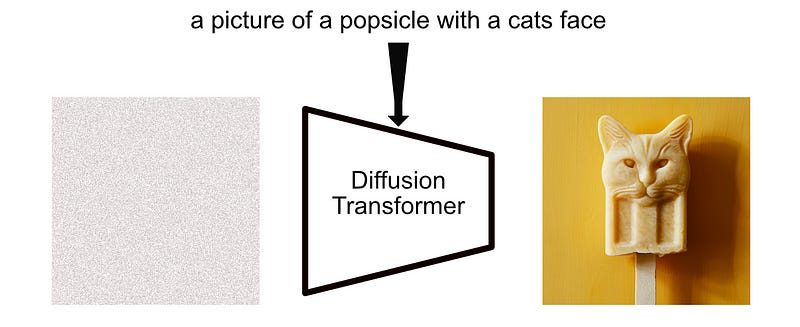
In terms of injecting a prompt into the transformer, there are a variety of possible approaches, all with the same goal; to somehow inject some text, like “a picture of a popsicle with a cats face” into a model so that we get a corresponding image.
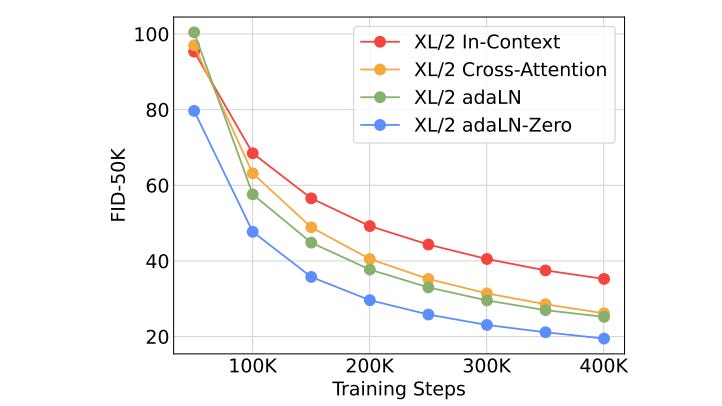
The Scalable Diffusion Models with Transformers paper covers three approaches to injecting text into the diffusion process:
Trivially, we could just take the image data and the text data and represent them all as a bunch of vectors. We could pass all that as an input, and try to get the model to output a less noisy image.
This is the simplest approach, but also the least performant. In various domains it’s been shown that mixing important information at various levels of a model is better than just sticking everything into the beginning and hoping the model sorts it out.
Another approach, which is inspired by other multimodal problems, is to use cross attention to incrementally inject the textual conditioning into the vision transformer throughout various steps.
We won't cover how cross attention works in depth (I cover cross attention in depth in my article on Flamingo, which also deals with aligning images and text). Basically, instead of an input being related to itself like in self attention, cross attention does the same thing but with two different inputs, allowing the model to create a highly contextualized and abstract representation based on both inputs.
This is a perfectly acceptable strategy, allowing text and image information to interact intimately throughout various points within the model. It’s also expensive; attention mechanisms ain’t cheap, and while this is a highly performant strategy, it comes at a steep price tag.
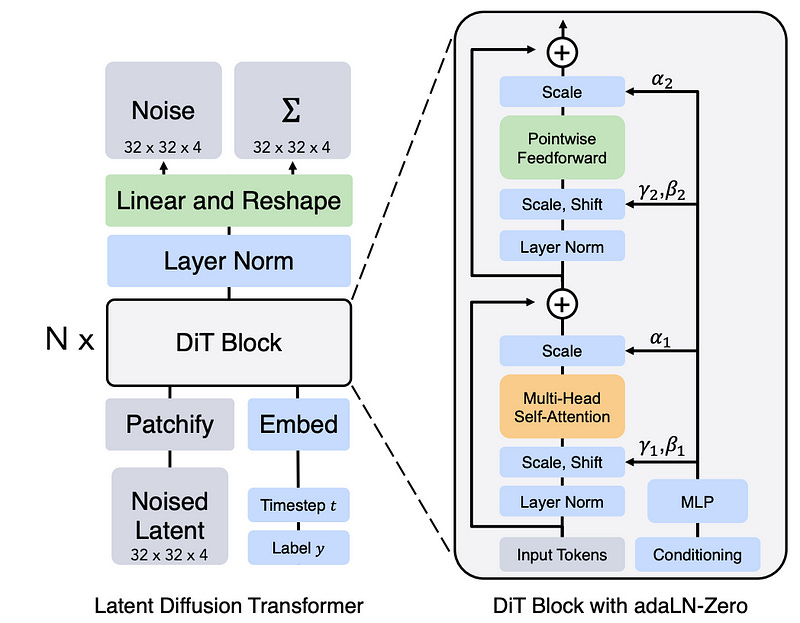
A third option, which the Scalable Diffusion Models with Transformers paper used, was adaLN-Zero.
adaLN-Zero allows a text to interact with image information in a very cost-efficient way, only utilizing a handful of parameters to control the interaction between image and textual data.
Within the transformer there are these things called “layer norm” blocks. I talk all about them in my transformer article. For our purposes we can simply think of them as occasionally taking the magnitude of values within the transformer and bringing them back down to reasonable levels.
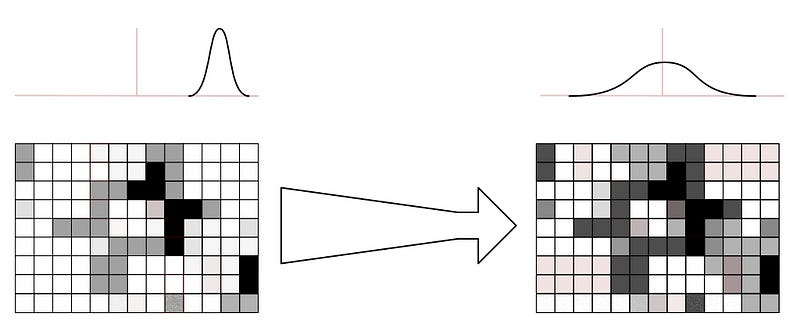
Having super big and super small values with crazy distributions can be problematic in machine learning, I talk about that in my article on gradients. Layer norm helps bring things back to a reasonable threshold by doing two things: Bringing the average back to zero, and bringing the standard deviation to 1.
The idea of adaLN is, what if some distributions don’t go back to a mean of zero or a standard deviation of one? What if the model can somehow control how wide or how narrow a c distribution is? That’s precisely what adaLN does; it allows the model to learn to control the distribution of values within the model based on the textual input. AdaLN also has a scaling factor as well, allowing adaLN to control how impactful certain blocks are.
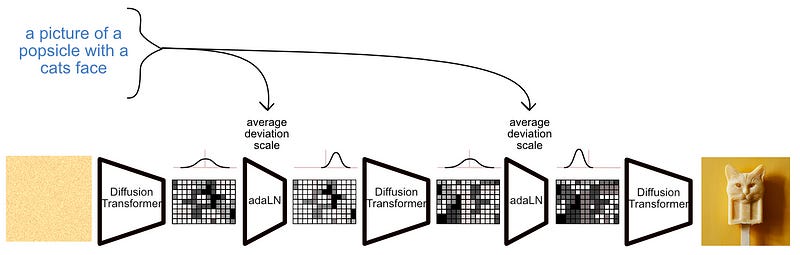
So, instead of the hefty amount of parameters in cross attention, adLN employs three: mean, standard deviation, and scale (as well as the parameters in the text encoder, naturally).
Transformers employ skip connections which allow old data to be combined with new data; a strategy that’s been shown to improve the performance of large models. By allowing the text to scale the importance of information before the addition of the skip connection, adaLN effectively lets the text decide how much a certain operation should contribute to the data.

The Scalable Diffusion Models with Transformers paper doesn’t recommend adaLN, but “adaLN-Zero”. The only real difference here is in initialization. Some research has suggested that setting certain key values to zero at the beginning of training can improve performance.
In this example scaling values for all parameters were initialized to zero, meaning, at the beginning of training, the model doesn’t do anything. The only thing that allows data through is the skip connections.
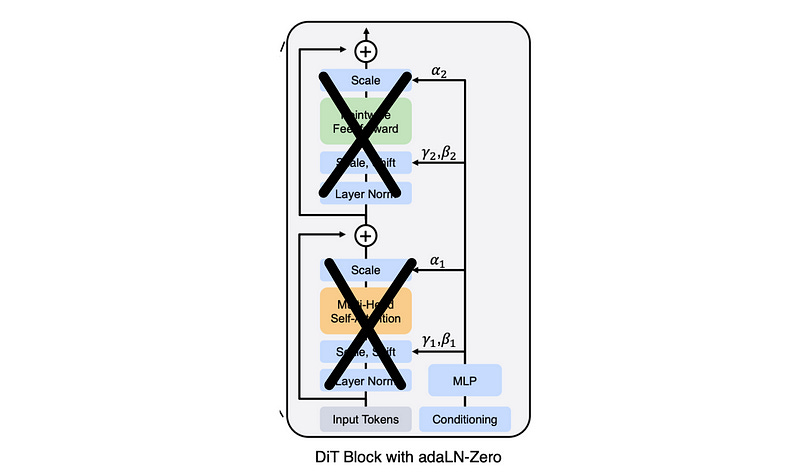
This effectively blocks anything from doing anything, meaning the model has to learn that activating certain blocks improves performance. This is a gentle way to allow the model to slowly learn subtle relationships, rather than being bombarded by a bunch of noise immediately. My article on flamingo, which defined the state of the art in visual language modeling, discusses a similar concept in aligning text with images.
Taking this back to Sora, the topic of this article; OpenAI has become progressively more secretive about the details of their models. It’s impossible to say which of these three approaches they employ, if they use some new approach, or a mixture of approaches. Based on the knowledge available in academia, they probably use something like adaLN-Zero with maybe some cross-attention peppered in.
How do we get the model to output a less noisy image?
Ok, so now we understand how vision transformers allow text to influence the model. But how does a vision transformer actually reduce the noise in an image?
Naively, if you were building something like a diffusion transformer, you might ask it to remove a little bit of noise each time.
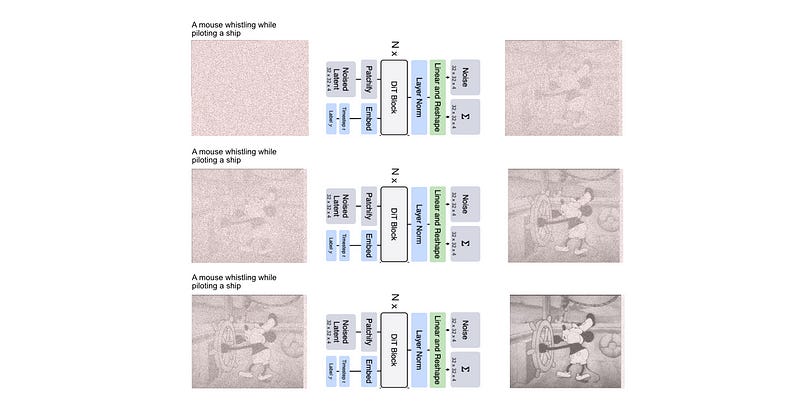
Then, you could just pass the image in over and over to make a less noisy image.

In essence this is exactly what the diffusion transformer does, but there are some subtle shifts in this approach which are employed in actual cutting-edge diffusion transformers.
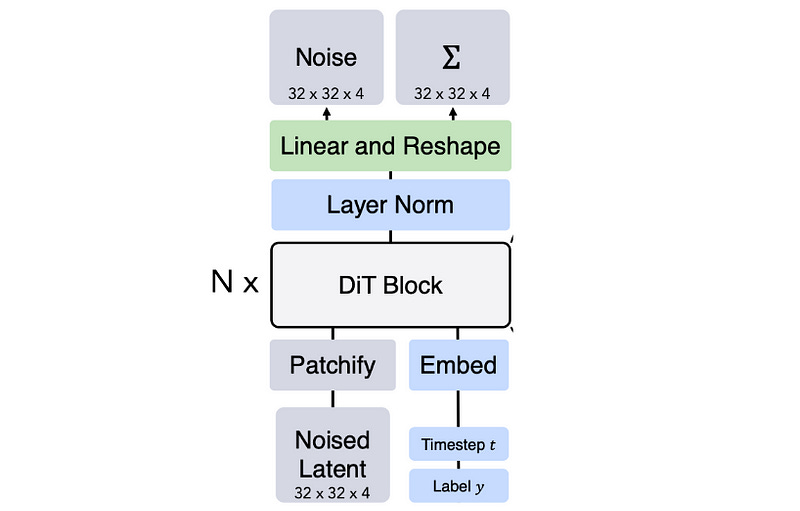
First of all, diffusion transformers don’t work in images, but in “latent image embeddings”. Basically, if you were to try to do diffusion on straight up pixels it would be very expensive.
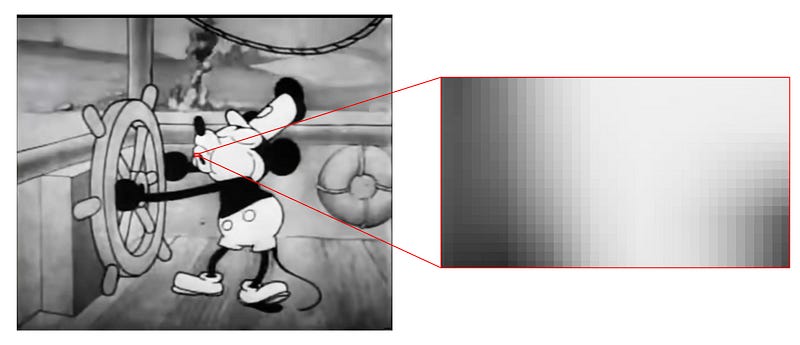
What if we could get rid of redundant information in an image by compressing the image down into some representation that contains all the important stuff? Then maybe we can somehow do diffusion on that compression, then decompress to generate the final model.
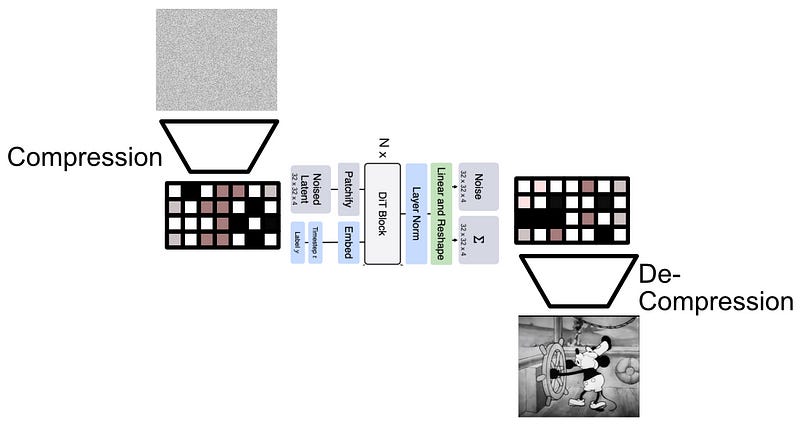
That’s exactly what happens in a “latent diffusion model”, which Sora almost certainly is. Latent diffusion models use a type of model called an autoencoder, which are networks that have been trained to compress and then reconstruct an image after passing it through a bottleneck of information. Basically, autoencoders are forced to fit an input into a tiny space, then re-construct that tiny thing back into the original. The thing that turns the input into a compression is called an “encoder” and the thing that turns the compression into the output is called a “decoder”.
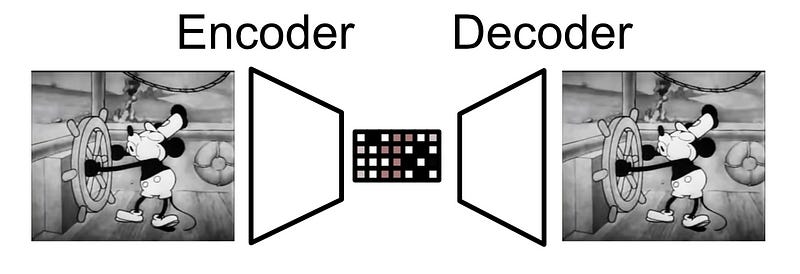
Instead of doing diffusion on the image itself, a diffusion model actually works on a compressed representation of the image. Once it’s done de-noising, it just decompresses the image. This compressed version of an image is often called a “latent”, hence why the diagram of the diffusion transformer includes the word “latent” instead of “image” as the input and output.
There are a lot more details to diffusion transformers. What is the output “Σ” of the diffusion transformer? Why does the output in the diagram say “noise” instead of “image”? etc. I’ll cover diffusion transformers in a dedicated article, but for now we understand enough to, finally, explore Sora.
The Sora Architecture (Probably)
Keep reading with a 7-day free trial
Subscribe to Intuitively and Exhaustively Explained to keep reading this post and get 7 days of free access to the full post archives.