
Flamingo — Intuitively and Exhaustively Explained
The Architecture Behind Modern Visual Language Modeling


In this article we’ll discuss Flamingo, a landmark paper in “multimodal modeling”.
First we’ll define “multimodal models” as a class of machine learning models capable of understanding numerous types of data. We’ll then briefly explore landmark papers in image classification and text generation, then describe how Flamingo combined these technologies to achieve state of the art performance in use cases containing both images and text.
By the end of this article you’ll have a thorough understanding of how Flamingo achieved state-of-the-art performance, paving the way for today’s advanced A.I. systems like GPT-4 and Google Gemini.

Who is this useful for? Anyone interested in natural language processing, computer vision, or multimodal modeling.
How advanced is this post? This is an intermediate post that assumes some basic knowledge of machine learning.
Pre-requisites: None, but I included some relevant reference material throughout the article should you be confused about a specific topic.
There is also a curated list of resources at the end of the article for related reading.
Multimodal Modeling Before Flamingo
“Vision-Language modeling” is what most people think of when they think of “multimodal modeling”. Before we get into the nuts and bolts, let’s define these two ideas:
Multimodal modeling is an umbrella term for any machine learning model that deals with multiple “modalities”. You can think of a modality as a type of data; things like text, images, tables, and audio are all considered by data scientists as different “modalities”. Multimodal models are models that can somehow work with multiple modalities.
Vision-language modeling is probably the most popular form of multimodality. machine learning models that can, in some way, do tasks that require the simultaneous understanding of both images and text.
In reality, vision-language modeling is a catchall term for a broad class of problems:
Visual Question Answering: Given an image and a textual question about that image, generate a response
Captioning: Given an image, describe the content of the image textually
Visual Dialogue: Hold a coherent and organic conversation that contains both images and text
Image Classification: Given an image, categorize that image into one of a fixed set of predefined textual classes.
Before Flamingo, highly specific models were state-of-the-art on highly specific multimodal tasks:
KAT was state of the art on the OKVQA dataset, a visual question answering dataset
a Good Embedding Is All You Need? was state of the art on VQAv2, a different visual question answering dataset
SimVLM was state of the art on COCO, an image captioning dataset
VIOLET was state of the art on MSVDQA, a visual question answering dataset focused on video
One of the big claims from the CLIP paper (a landmark paper we’ll cover in the next section) was that this highly specialized performance doesn’t scale well to real-world situations. If you have a model that’s good at one dataset, but can’t do a similar task in a similar dataset, is it really a good model?
CLIP tackled this problem before flamingo, but CLIP style models only work in classifying images. The idea behind Flamingo was to bridge the gap between CLIP style models, which have a robust understanding of the content of images, and the textual understanding and generative ability of language models, creating a system that could be used to converse about both text and images robustly and flexibly.
The Precursors to Flamingo
Before we talk about Flamingo itself, it’s critical to understand the two key modeling strategies it inherits; CLIP and Decoder Transformers:
CLIP
The whole idea of CLIP was to create a general-purpose image classifier that could be used in a variety of cases without any further training. To achieve this, the authors of the CLIP paper used a strategy called “contrastive learning”.

Contrastive learning is a subtle re-framing of the problem of image classification. Instead of learning “This label goes with this image, and this label goes with that image”, contrastive learning says “This label is closer in similarity to this image, and this label is closer in similarity to that image”. This subtle change in thinking opened up a whole new approach to representing images that have been widely used ever since.
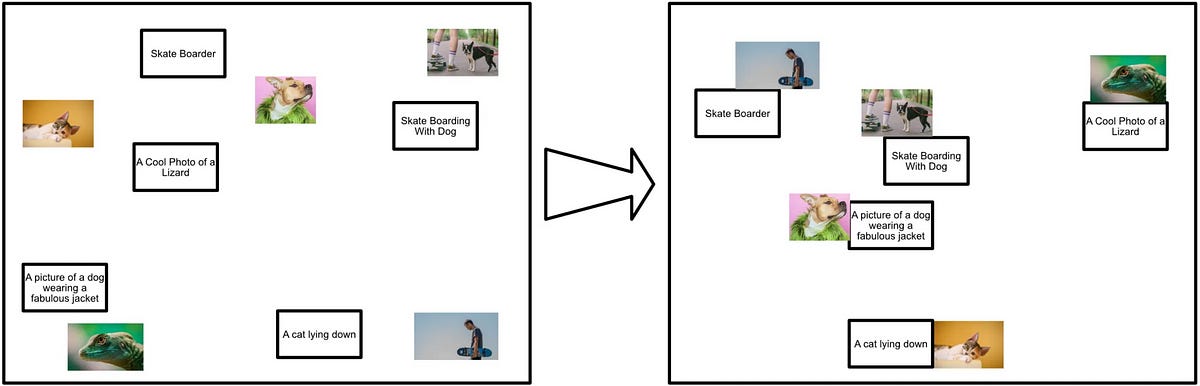
CLIP employs two components to build this idea of “closeness”, an image encoder and a text encoder. These both learn, in unison through the training process, to jointly align pairs of images and text in a high-dimensional space. By putting similar images and text in similar spots, and different images and text in different spots, CLIP style models learn to make decisions about which text belongs with which image.

The important part for us is the image encoder. For CLIP to be successful, it has to train the image encoder to understand things like dogs, clothes, and skateboards within an image so that those images can be placed in the right spot with the right text. In other words, CLIP Image encoders are really good at distilling an image down into its general meaning, a quality Flamingo employs to achieve visual-language modeling.
That was a super quick run-through, feel free to refer to my article on CLIP for more information:

Decoder-Only Transformers
So that was CLIP, the technology Flamingo uses to understand images. Decoder-only transformers are what Flamingo uses to understand text.
From a super high level, you can think of language models as a big stack of blocks. The purpose of each of these blocks is to refine a representation of the input text, block by block, and then use that representation to predict what text should follow the input.

The thing that makes each of these blocks within the transformer special is their use of “attention”. Attention is a form of modeling where the representation of multiple words in the input are combined together to create an abstract and highly contextualized representation.

This is done by feeding the attention mechanism three inputs: A “Query”, “Key” and “Value”. Don’t get hung up on the names, we’ll build a more intuitive understanding of all this later, I just want to share with you the high level workings of the attention mechanism.
The query and key, which are derived from the input to the attention mechanism, get multiplied together to create what I like to call the “attention matrix”

Then, the attention matrix is used as a filter to transform the value matrix into the final output.

So, in essence, the attention mechanism uses some inputs to filter other inputs. We’ll cover attention more thoroughly later in this article, for now, just understanding the vibe from a high level is sufficient. If you do want to dig in deeper, check out my article on transformers, or my article on GPT a popular decoder-only transformer:


The end goal of a decoder-only transformer is to use the attention mechanisms, within the numerous blocks of the model, to understand the input, and figure out what the next output should be. By being able to guess the next output well, language models can construct an output by guessing one word at a time.

Flamingo in a Nutshell
Now that we understand the essence of CLIP style image encoding (which turns an image into a vector that conveys the image's general meaning) and transformer style language models (which use attention to iteratively output words), we can start digging into Flamingo.
At its highest level, flamingo consists of four key components:
A Vision Encoder, which re-represents images into their general meaning
A Perceiver Resampler, A system that combines the information from a variable number of images into a fixed number of features (allowing the model to understand things like video or a series of images)
A Language Model, a pre-trained decoder style transformer like GPT3 or llama. The flamingo paper used chinchilla.
Gated Cross Attention, allowing flamingo to slowly learn to inject image information into the language model throughout the training process.

Flamingo uses these systems to understand an arbitrary input sequence of images and text to generate textual output. Let’s break down each of these components, one by one, to build a complete understanding of how Flamingo functions.
The Vision Encoder
Flamingo uses a CLIP style image encoder (the one we previously discussed) to encode images. This is a common strategy used in numerous multimodal architectures that have to do with images.
The idea is, instead of Flamingo needing to learn about images from scratch, it can employ the high quality summarizations from a pre-trained CLIP image encoder. Thus, Flamingo offloads a lot of the work of understanding images, and instead only has to reason about image distillations.

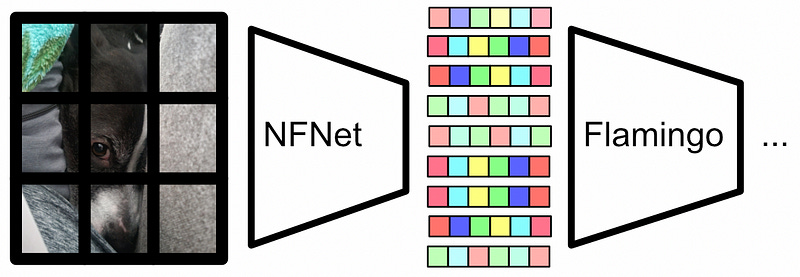
Flamingo doesn’t actually use CLIP, but the NFNet F6 model. For our purposes, the only conceptual difference is that NFNet produces summarizations about sub-regions of an image rather than the whole image. This makes it easier for Flamingo to understand subtleties within the image. NFNet also does a lot of other cool stuff, I might cover it in a future article, but for our purposes, this is more of a line item. Conceptually, NFNet is like a fancy version of CLIP.
The Preceiver Resampler
In wanting to create a flexible and robust multimodal model, the authors of Flamingo created a system that was good at handling both images and video. Video data is a difficult type of data to do machine learning on; there’s a lot of information in even small video files, and extracting the right information efficiently can be computationally expensive and difficult.

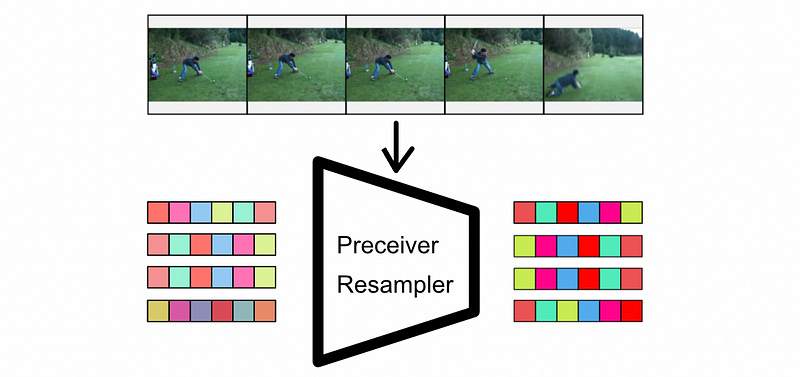
Flamingo addresses the problems of video with the “Perceiver Resampler”. The perceiver resampler can be thought of as a summarization system that compresses an arbitrarily long video down into a fixed set of descriptive tokens. It’s not conceptually difficult, but there’s a lot of moving parts. Let’s look at it from a high level, then a more nuts-and-bolts lower level
The Preceiver Resampler — High Level
Conceptually, you can think of the perceiver resampler as a filter; it takes in a fixed length of predefined tokens and uses input images extracted from video to filter those tokens. Regardless of the number of images in an input, the same fixed number of tokens come out of the output.
From a high level, the perceiver resampler fits into the greater Flamingo architecture in the following way:
The images are extracted from the prompt. In their place, an
<image>token is placed in the text so that the model knows where the image came from.The output from the perceiver resampler is used to incrementally filter the internal state of the LLM throughout various layers, ultimately allowing the LLM to converse about the images.
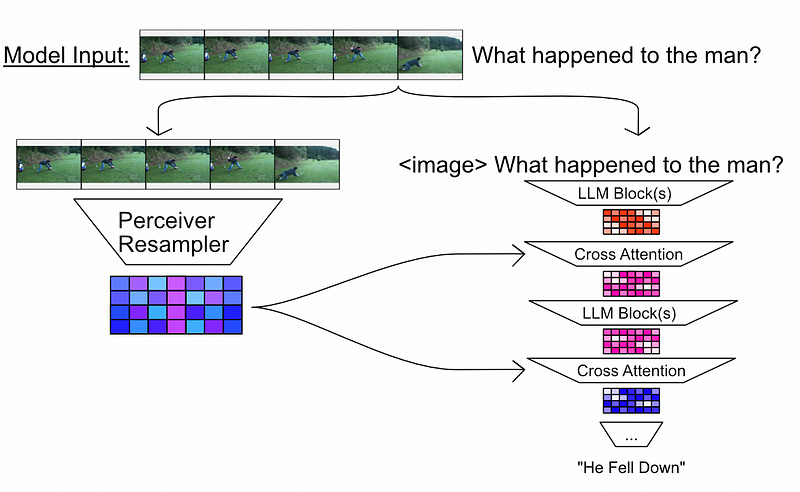
We’ll cover how cross-attention interweaves the image representation into the LLM in later sections. For now, let’s zoom into the perceiver resampler and see how it works.
The Perceiver Resampler — Nuts and Bolts
To understand the perceiver resampler in more detail, let’s work through its components step-by-step.
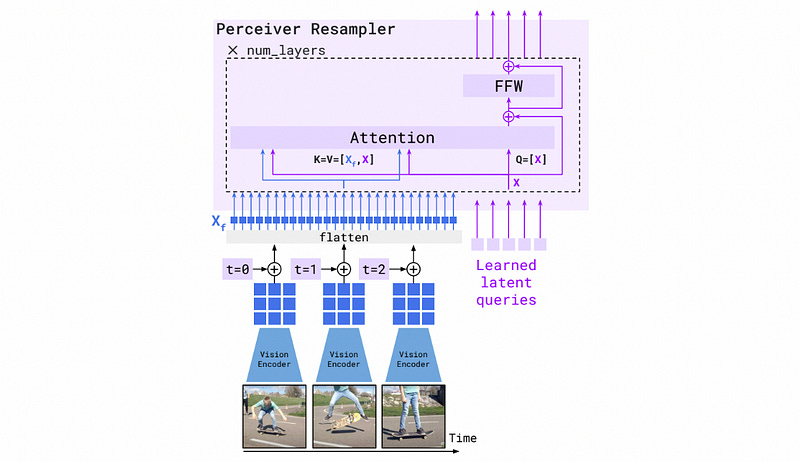
First, the input image, or sequence of images, is passed through a vision encoder. This summarizes the content of the image in a way that’s easy to interpret for ML systems. This is our NFNet image encoder we discussed in a previous section.

The attention mechanism (which the image encodings are ultimately fed into), tends to shuffle inputs around and thus lose track of where a particular piece of information was in an input sequence. As a result, it’s customary to add a time encoding, which embeds the time of an input into the value of the input itself.
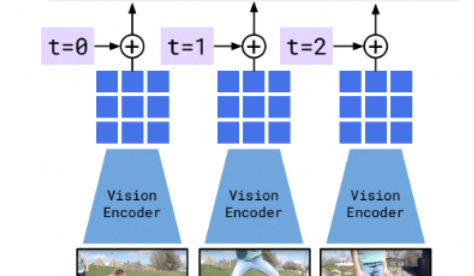
Flamingo uses a learned time vector for each frame in the input. During training, Flamingo has spots for 8 input frames total. These are added to the features extracted from the vision encoder.

I was a bit surprised by this. I thought the whole point of Flamingo was to be generalizable; limiting video input to eight frames seemed like kind of a silly design choice. Apparently, though, the model is robust to interpolating between time embeddings to fit in more frames as necessary. So, if you want to add more frames, just make new time tokens by interpolating between the eight trained ones.
Although our model was trained with a fixed number of 8 frames, at inference time, we input 30 frames at 3 FPS. This is achieved by linearly interpolating the learnt temporal position embedding of the Perceiver Resampler at inference time. — The Flamingo Paper.
Another quick note, you might think “Hey, if we need to add information about time, then why not location? If attention mixes up our input, wouldn’t it be useful to say something like ‘this information came from the top right of an image’?” The answer to that is absolutely, but we don’t have to add positional information because our vision encoder does already:
Note that we only use temporal encodings and no explicit spatial grid position encodings; we did not observe improvements from the latter. This rationale behind is likely that CNNs, such as our NFNet encoder, are known to implicitly include spatial information — The Flamingo Paper.
Now that we have extracted features from each image, and we’ve added all necessary information about time, we can use attention to filter out the right information from the image via the learned tokens.
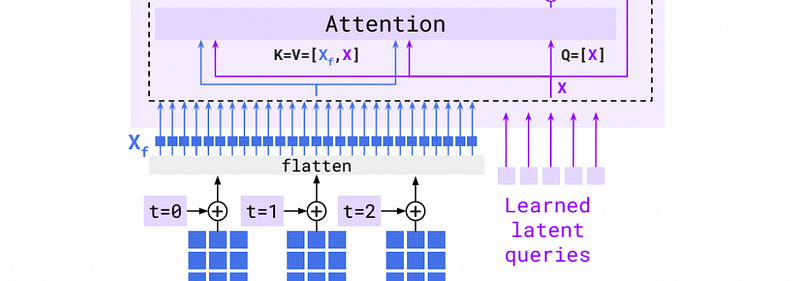
Let’s follow some data through the attention mechanism to get a thorough idea of how it functions.
Step 1) Flattening
The features extracted from the images are of shape [T, S, d] where T is the number of images, S is the number of spatial grids, and d is the length of the feature vectors. In most machine learning contexts, “tokens” are vectors of some length. d is sometimes referred to as the “internal dimension”, as it’s the size of the token vectors within the model (note: in this article d is depicted as length 6, but in reality, the internal dimension of modern models is very large. on the order of hundreds or thousands. So, usually, these vectors are much, much longer than is depicted).
Before passing through attention, these tokens get flattened along the space and time dimensions; so T and S become a dimension of length T * S , resulting in a two-dimensional matrix of shape [T * S, d] .

Keep in mind, while this might appear like we’re shuffling the image data around:
This operation is done consistently across successive runs, so while flattening mixes up the order of space and time, it does so in the same way for any given input.
We don’t really need the order to be preserved. Recall that spatial information is automatically encoded by the image encoder, and time information was added to encode time information in each token. As long as things are done consistently, the order of the inputs doesn’t really matter.
Step 2) Creating the Key and Value
Now that the information from our images is properly processed, it’s time to pass them into the attention mechanism. Recall that, from a high level, the whole idea of the perceived resampler is to use images to filter a fixed number of tokens.

This “filtering” idea gets done with matrix multiplication within the attention mechanism, which is essentially just matrix multiplication.

The whole idea of this attention mechanism is that a fixed number of tokens are extracted from a variable sequence of images, so it makes sense that some clever matrix manipulation would be required to get everything working right. That’s why there are a bunch of arrows before the attention mechanism in the perceiver resampler.

For Flamingo, the flattened features from the image, labeled Xf , are concatenated with a set of learned tokens, Xof shape [R,d] to construct the “key” and “value” inputs. In this case, R represents an arbitrary fixed number of tokens. The “query” is simply the learned tokens X .
Recall that d is the internal dimension of the model.

One question you might be wondering is “Why are the learned tokens appended to the image information?”, I think this is so the perceiver resampler can more intimately control the information that comes out of the attention mechanism. Keep that in mind as we go through the next section.
Step 3) Running Through the Attention Mechanism
Now that we have our Query, Key, and Value defined we can run them through attention. Attention is just two matrix multiplication operations. First, the Query and Key are multiplied together to construct the attention matrix

Then the attention matrix is multiplied by the value to construct the final output.

et voilà, the attention mechanism in the perceiver resampler has now extracted information from all images into a fixed number of output tokens, which are of size [R, D] , where r is the arbitrary number of fixed learned tokens and d is the, also arbitrary, internal model dimension.

Step 4) Constructing the Final Output
After the attention mechanism a “skip” connection is applied. Basically, the attention mechanism is great at extracting subtle features, but it mixes everything around like crazy. It’s useful to allow some of the older, simpler structure from before the attention mechanism to be present. Thus, the learned tokens from before the attention mechanism are added to the output of the attention mechanism, allowing some older and simpler information to be present.

The output of the skip connection is passed through a feed forward network, which is your classic prototypical neural network. Another skip connection is applied for the same reason as before.
Generally, with machine learning systems, it helps to do the same thing in a few passes so that complex operations can be done incrementally over numerous layers. In the perceiver resampler, this information extraction using attention, skip, and feedforward is done a few times. The output tokens from one iteration are fed right back into the input of another; hence the X num_layers in the diagram above.
Alright, so that’s the perceived resampler. Using a set of learned tokens (which are just vectors of numbers that can change throughout the training process), multiple stacks of attention allow the perceiver resampler to extract information from a sequence of input images. In the next section we’ll discuss how that information is fed into a language model so that the language model can converse about images.
Combining Visual and Textual Information With Gated Cross Attention
Cudos for hanging in there, hopefully you’re finding this as fascinating as I am. It’s been about six months since you started reading this article; recall that the whole point is to get a pre-trained language model to be able to understand and converse about images.

Now that we’ve used the perceiver resampler to extract a fixed amount of information from our images (or image sequences), we need to feed that information into the language model. To do that, we’ll use gated cross attention.
The idea of gated cross attention is to incrementally inject visual information throughout our pre-trained language model. At every level (or every few levels), gated cross attention tries to introduce the right visual information so that the model can perform best.

The visual data from the perceiver resampler is used to construct the “key” and “value”, and tokens from within the language model are used to generate the “query”. By feeding both image and language data into cross attention, both language information and image information are used to create an abstract representation of both modalities (We’ll zoom into the specifics of cross attention in the next section).
The language model, if it were a person, would be freaking out at this point. The language model has learned to carefully represent language throughout successive highly abstract and subtle representations. Now we’re throwing a big old wrench in that careful equation.
To mitigate this issue, Flamingo employs “tanh gating”. at every point Flamingo injects cross attention, it employs a tanh gate with a learnable value alpha. This alpha value, which is used as the input to the tanh function, is initially set to 0. the result of tanh(alpha=0) is 0 .
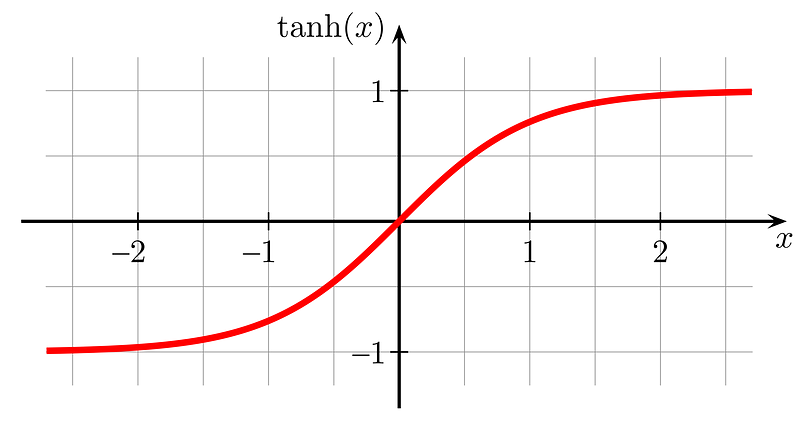
The result of the gating function is multiplied by the cross attention output, effectively acting like a knob that dials in how much visual information is introduced to the model. The model learns through training that changing alpha changes the value of the tanh function, thus it learns to slowly dial in more or less visual information from the cross attention mechanism.
After the tanh gate, there’s a skip connection denoted as “+”. Recall that skip connections just take data from before some operation, and add it to the result of an operation.

So, between tanh gating and the skip connection, the cross attention mechanism that introduces visual information looks something like this:
result = (tanh(alpha) * cross_attention(vis_info, lang_info)) + lang_infobecause alpha is initialized to 0 at the beginning of training, the value of the tanh gate is also 0. Thus, the cross attention mechanism has no info at the beginning of training, and the final output is the same as if we just used the language model without flamingo at all.
result = (0 * cross_attention(vis_info, lang_info)) + lang_info = just lang_infoIf we didn’t do this, we would be injecting image information straight up at the beginning of training, and would heavily confuse the language model with a bunch of bad information, as a brand new preceiver resampler has no idea how to best represent image data in a way that’s best for the language model. Thus, tanh gating allows Flamingo to gently introduce image information into the model.
After the gated cross attention there’s a gated feed forward layer, which is gated for the same reason. You can think of this as a neural network that transforms the combined language and image data to be copacetic with future layers of the language model.
So, from an information flow perspective, that’s it! You now understand how flamingo models are able to converse about images by:
extracting images from the input prompt
using the perceiver resampler to reformat images or image sequences into a fixed number of tokens
using cross attention to inject image information into the language model, so the language model can converse about both the input text and images.
There are a few other details that Flamingo employs to make the flow of information actually work. Now that we have a complete picture of Flamingo from a high level, we can zoom into some specific details.
An Intro To Masking
One of the things that makes Flamingo unique is the way it handles masking. For those unfamiliar with the general topic, masking is an important component of attention that allows researchers to hide certain information in certain parts of a machine learning model.
You might be wondering why it would be useful to hide information from a model. Wouldn’t a machine learning model generally be better if it had access to all information? Generally that’s the case, but masking is a frequent exception to that general rule.
Language models, for instance, use a “causal mask”. The idea of language models is that they predict the next word in an input sequence, but when they’re trained, language models like GPT actually predict every next word in a sequence.

If a language model could just look at what the next word in a sequence should be, this form of training would be trivial; the model would just copy the next word at a given output. By using causal masking, however, the model is unable to see future words when predicting a given word.
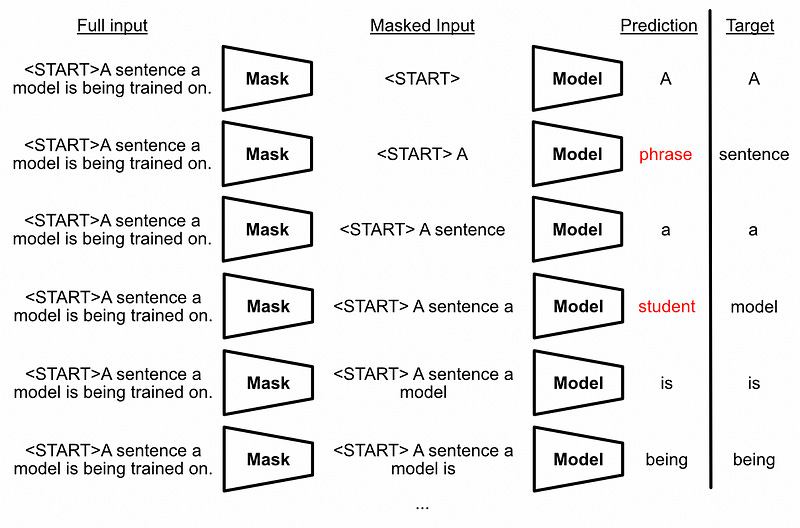
The causal mask itself exists within the self attention mechanism of the language model. Recall that modern language models are, essentially, a big stack of blocks of self attention. The causal mask gets applied to the attention mechanism via the actual attention matrix. Recall that the “query” and “key” inputs get multiplied together to construct the “attention matrix”, and the “attention matrix” is multiplied by the “value” to create the final output.
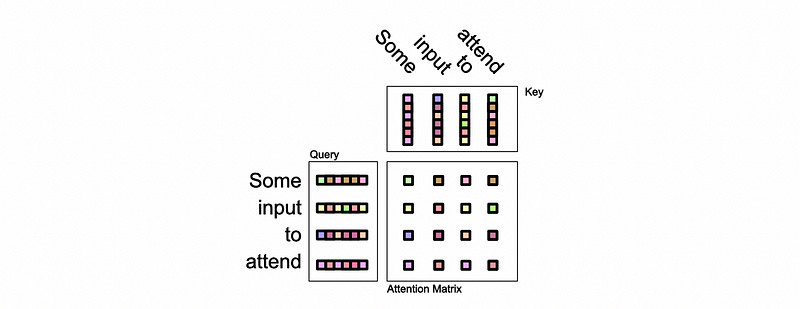
This attention matrix, in being a matrix multiplication, is a complex combination of every input in the “query” with every input in the “key”. The idea of causal masking is, when a “query” interacts with a “key” that corresponds to a word in the future, the causal mask sets the value of the attention matrix at that location to zero; thus hiding from the model any information about future words from the given word.

Keep in mind, this is to facilitate making the training objective of predicting every next word non-trivial. If every attention block in a language model uses a causal mask, information from future words can never bleed into the information of previous words.
Causal masking is relevant to Flamingo, in that the language model which Flamingo uses was trained using a causal mask. However, flamingo itself employs a slightly different masking strategy in masking media.
Arbitrary Cross Attention of Media Via Masking
The idea of flamingo is that you can arbitrarily converse with the model about images and text. You might have a lot of images, you might have very few images, and different conversations with the model might feature a variety of locations those images might exist in a conversation. Machine learning models like to learn patterns, and they get confused when they encounter examples that don’t respect patterns they’ve learned. How can we get Flamingo to be good at understanding the diversity of conversations it might have about images?

The Flamingo paper addresses this problem by using a different masking system. Recall from the previous section that Flamingo employs cross attention to inject image data from the perceiver resampler into the language model.
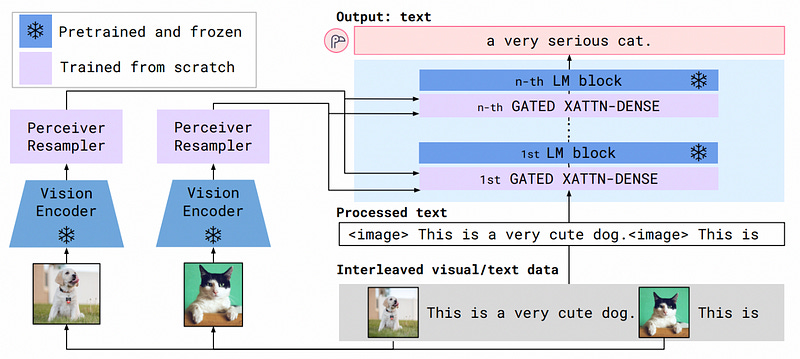
Within the cross attention mechanism, only the immediately preceding image (or image sequence) is allowed to attend to a particular word in the input sequence.
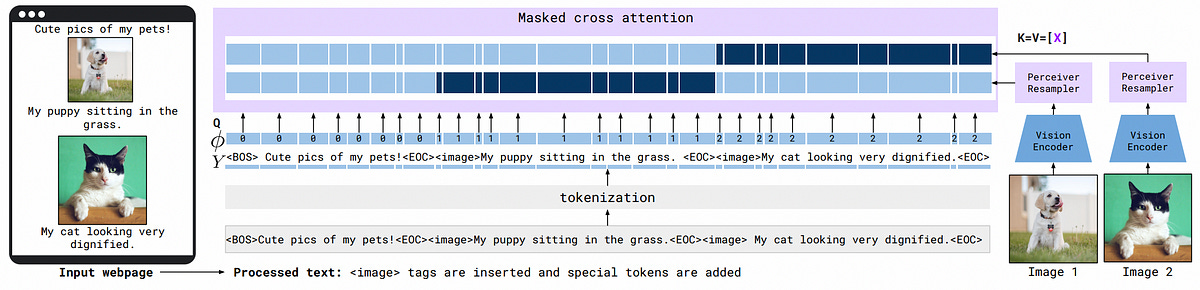
Figure 7: Interleaved visual data and text support. Given text interleaved with images/videos, e.g. coming from a webpage, we first process the text by inserting tags at the locations of the visual data in the text as well as special tokens ( for “beginning of sequence” or for “end of chunk”). Images are processed independently by the Vision Encoder and Perceiver Resampler to extract visual tokens. At a given text token, the model only cross-attends to the visual tokens corresponding to the last preceding image/video. 𝜑 indicates which image/video a text token can attend or 0 when no image/video is preceding. In practice, this selective cross-attention is achieved through masking — illustrated here with the dark blue entries (unmasked/visible) and light blue entries (masked).
Exactly how this is done is left as a bit of a mystery; the Flamingo paper inherits an unfortunate trend of ML research; transitioning from public academia to private corporate incentives.
The code and the data are proprietary. — The Flamingo Paper.
Flamingo was written by a bunch of PhD Googlers at DeepMind; it can’t be too hard to guess what they did. Jokes aside, we know a lot about how Flamingo handles attention, so we probably actually can approximate what was done behind the scenes.
Recall that, with out causal self attention mask in the language model, we mask in this way that only exposes a word to itself and previous words:

We can apply the same general logic to imagine what our media mask might look like in Flamingo. Based on how they define the query and the key, the actual attention calculation would look something like this:
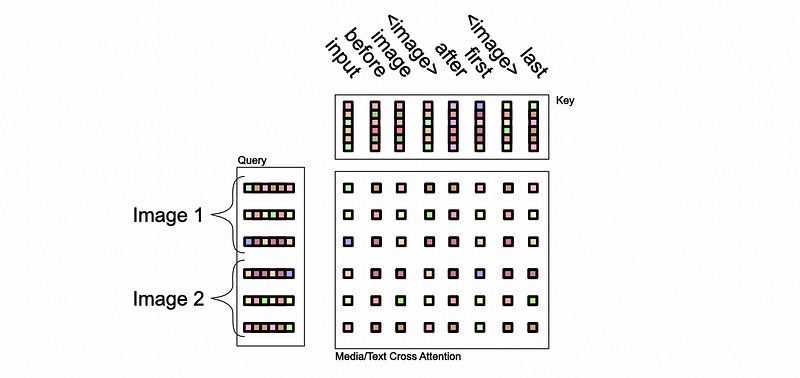
Then, presumably, the mask that Flamingo employs would simply mask out any relationships that didn’t obey the “immediately preceding image” rule.

The Flamingo paper talks a lot about “Φ” (phi). All phi is, in flamingo, is a function that programmatically keeps track of which text should belong with which image so that this mask can be correctly defined for a given input. Naturally, with different input sequences, Flamingo’s cross attention mask would change.
The whole reason Flamingo does this is to improve Flamingo's ability to generally understand interleaved text and images. There’s a few theoretical ideas behind this:
By restricting the text to attend only to the immediately preceding image, the model ensures that the textual analysis is directly relevant to the most recent visual context. This helps maintain a tight coupling between what is seen in the image and what is being described or asked in the text.
Allowing text to attend to all previous images would significantly increase the computational complexity and memory requirements of the model.
Focusing on the immediate image-text pair helps the model better learn the relationships between visual content and textual information. This can improve the model’s ability to generalize from seen examples to unseen examples.
By narrowing the scope of attention, the model simplifies the learning task, which can help in reducing the risk of overfitting to irrelevant details or patterns. This focus can lead to a model that is better at understanding and responding to the specific nuances of the image-text interaction.
Conclusion
And that’s it. Sorry I didn’t include more, I know this was a short one.
In this article we defined Multimodal modeling, and focused in on visual question answering. We defined the previous state of the art, where a bunch of disparate models were good at a bunch of disparate tasks. We then discussed how flamingo joined two existing technologies; CLIP models and transformer decoder models, combining two highly performant and generalized modeling strategies.
We covered how Flamingo is, essentially, a set of tools designed to bridge CLIP and decoder models. First, we covered how the perceiver resampler takes CLIP embeddings for image sequences and compresses them down to a fixed-sized representation. Then, we discussed how Flamingo employs tanh gated cross attention to inject that information into the language model. Finally, we went over some specifics, like Flamingo’s masking strategy, to get an idea of some of the important subtleties Flamingo employs to maintain cutting-edge performance.
Attribution: You can use any resource in this post for your own non-commercial purposes, so long as you reference this article, https://danielwarfield.dev, or both. An explicit commercial license may be granted upon request.
Further Reading
Sorted based on relevance and importance to the content of this article.
In this post you’ll learn about “contrastive language-image pre-training” (CLIP), A strategy for creating vision and language representations so good they can be used to make highly specific and performant classifiers without any training data. We’ll go over the theory, how CLIP differs from more conventional methods, then we’ll walk through the architecture step by step.
In this post you will learn about the transformer architecture, which is at the core of the architecture of nearly all cutting-edge large language models. We’ll start with a brief chronology of some relevant natural language processing concepts, then we’ll go through the transformer step by step and uncover how it works.

In this article we’ll use a Q-Former, a technique for bridging computer vision and natural language models, to create a visual question answering system. We’ll go over the necessary theory, following the BLIP-2 paper, then implement a system which can be used to talk with a large language model about an image.
In this article we’ll be exploring the evolution of OpenAI’s GPT models. We’ll briefly cover the transformer, describe variations of the transformer which lead to the first GPT model, then we’ll go through GPT1, GPT2, GPT3, and GPT4 to build a complete conceptual understanding of the state of the art

In this article we’ll discuss “Speculative Sampling”, a strategy that makes text generation faster and more affordable without compromising on performance. In doing so, we’ll take a thorough look at some of the more subtle aspects of language models.

{kind=link}
Convolutional neural networks are a mainstay in computer vision, signal processing, and a massive number of other machine learning tasks. They’re fairly straightforward and, as a result, many people take them for granted without really understanding them. In this article we’ll go over the theory of convolutional networks, intuitively and exhaustively, and we’ll explore their application within a few use cases.
I would be thrilled to answer any questions or thoughts you might have about the article. An article is one thing, but an article combined with thoughts, ideas, and considerations holds much more educational power!