


YOLO — Intuitively and Exhaustively Explained
The genesis of the most widely used object detection models.


In this post we’ll discuss YOLO, the landmark paper that laid the groundwork for modern real-time computer vision. We’ll start with a brief chronology of some relevant concepts, then go through YOLO step by step to build a thorough understanding of how it works.
Who is this useful for? Anyone interested in computer vision or cutting-edge AI advancements.
How advanced is this post? This article should be accessible to technology enthusiasts, and interesting to even the most skilled data scientists.
Pre-requisites: A good working understanding of a standard neural network. Some cursory experience with convolutional networks may also be useful.
A Brief Chronology of Computer Vision Before YOLO
The following sections contain useful concepts and technologies to know before getting into YOLO. Feel free to skip ahead if you feel confident.
Types of Computer Vision Problems
Computer vision is a class of several problem types, all of which relate to somehow enabling computers to “see” things. Typically, computer vision is broken up into the following:
Image Classification: the task of trying to classify an entire image. For instance, one might classify an entire image as containing a cat or a dog.
Object Detection: the task of finding instances of an object within an image, and where those instances are.
Image Segmentation: the task of identifying the individual pixels within an image that correspond to a specific object. So, for instance, identify all the pixels within an image that correspond to dogs.

Convolutional Neural Networks
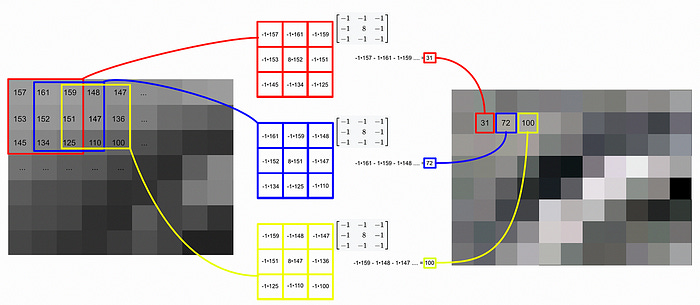
YOLO employs a form of model called a “Convolutional Neural Network”. A convolutional neural network (CNN for short) is a style of neural network that applies a filter, called a “Kernel” over an image.

These “kernels” are simply a block of numbers. If the numbers in the kernel change, the result of the filtering process changes.

The actual filtering process consists of the kernel being swept through various parts of an image. At a given location, the kernels values are multiplied to the values in the image, and then added together to result in a new output. This process of “sweeping” is how CNNs get their name. In math, sweeping in this way is called “convolving”.
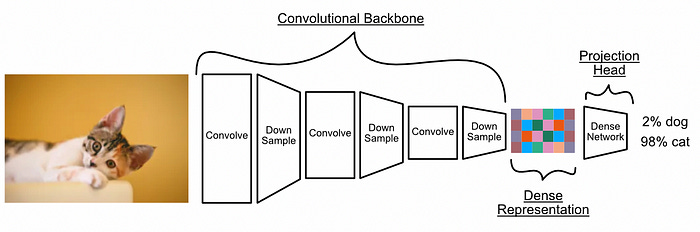
For computer vision tasks, CNNs typically apply convolution and information compression over successive steps to break down an image into some dense and meaningful representation. This representation is then used by a classic neural network to achieve some final task.
The most common way a CNN compresses an image down into a meaningful representation is by employing “max pooling”. Basically, you break an image up into N by N squares, then out of those squares you only preserve the highest value.

After a model has filtered (convolved) and down sampled (max pool) an image over numerous iterations, the result is a compressed representation that contains key information about the image. This is often passed through a dense network (a classic neural network) to produce the final output.
If you want to learn more about convolutional networks, I wrote a whole article on the topic:

If you’re interested in the structure of CNNs, and how backbones and heads can be used in advanced training processes, you might be interested in this article:

Early Object Detection with Sliding Window
Before approaches like YOLO, “sliding window” was the go-to strategy in object detection. Recall that the goal of object detection is to detect instances of some object within an image.
In sliding window, the idea is to sweep a window across an image and classify the content of the window with a classification model.

Once classifications have been calculated, a final bounding box can be defined by simply combining all the classified windows.

There are a few tricks one can use to get this process working better. However, the sliding window strategy of object detection still suffers from two key problems:
It’s very computationally intensive (you may have to run a model tens, hundreds, or even thousands of times per image)
The bounding boxes are inaccurate
Selective Search and R-CNN
Instead of arbitrarily sweeping some window through an image, the idea of selective search is to find better windows based on the content of the image itself. In selective search, first small regions within an image that contain a lot of similar pixels are found, then similar neighboring regions are merged together over successive iterations to build larger regions. These large regions can be used to recommend bounding boxes.

With selective search, instead of finding random windows based on sweeping, bounding boxes are suggested by the image itself. Several approaches have used selective search to drastically improve object detection.
One of the most famous models to use this trick is R-CNN, which trained a tailored convolutional network based on proposed regions in order to enable high quality object detection.
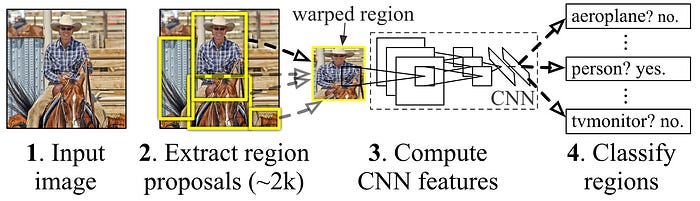
R-CNN was a mainstay in computer vision for a while, and spawned many derivative ideas. However, it’s still very computationally intensive.
YOLO blew the paradigm of R-CNN out of the water, and inspired a fundamentally new way of thinking about image processing that remains relevant to this day. Let’s get into it.
YOLO: You Only Look Once
The idea of YOLO is to do everything in one pass of a CNN, hence why it’s called “You Only Look Once”. That means a single CNN, in a single pass, has to somehow find numerous different instances of objects, correctly classify them, and draw bounding boxes around them.

To achieve this, the authors of YOLO broke down the task of object detection into two sub-tasks, and built a model to do those sub-tasks simultaneously.
Subtask 1) Regionalized Classification
YOLO breaks images up into some arbitrary number of regions, and then classifies all those regions at the same time. It does this by modifying the output structure of a traditional CNN.
Normally a CNN compresses an image into a dense 2D representation, then a process called flattening is applied to that representation to turn it into a single vector, which can in turn be fed into a dense network to generate a classification.

Unlike this traditional approach, YOLO predicts classes for sub-regions of the image rather than the entire image.
In YOLO, the convolution output is flattened like normal, but then the output is converted back into a 2D representation of shape S x S x C where S represents how finely the image is subdivided into regions and C represents the number of classes being predicted. Both S and C are configurable parameters which can be used to apply YOLO to different tasks.

Provided this model is trained correctly (we’ll cover that later), a model with this structure could classify numerous regions within an image in a single pass.

Not only is this more efficient than R-CNN (due to only one inference generating classes for an entire image), it’s also more performant. When R-CNN makes a prediction it only has access to the region proposed by selective search, which can make R-CNN bad at discerning irrelevant background objects.

CNNs have something called a “perceptive field”, which means that CNNs by themselves suffer a similar issue. A particular spot within a CNN can only see a small subset of the image. In theory this might cause YOLO to also make poor choices about predictions.

However, YOLO passes the dense 2D representation through a fully connected neural network; allowing information with each perceptive field to interact with one another before making the final prediction.

This allows YOLO to reason about the entire image before making the final prediction, a key difference that makes YOLO more robust than R-CNN in terms of contextual awareness.
Subtask 2) Bounding Box Prediction
In theory we could use the predicted regions from the previous step to draw bounding boxes, but the results wouldn’t be very good. Also, what if there were two dogs next to each other? It would be impossible to distinguish two dogs from one wide dog, because both would just look like a bunch of squares labeled dog.
To alleviate these issues YOLO predicts bounding boxes as well as class predictions.
YOLO assigns a “responsibility” to each square in the S x S grid. Basically, if a square contains the center of an object, then that square is responsible for creating the bounding box for that object.

The responsible square for a given object is in charge of drawing the bounding box for that object.
On top of the S x S x C tensor for class prediction (which we covered in the previous section), YOLO also predicts an S x S x B x 5 tensor for bounding box prediction. In this tensor S represents the divisions of the image (as before), and B represents the number of bounding boxes each S x S square can create. The 5 represents:
Bounding box width
Bounding box height
Bounding box horizontal offset
Bounding box vertical offset
Bounding box confidence
So, in essence, YOLO creates a bunch of bounding boxes for each square in the S x S grid. Specifically, YOLO creates B bounding boxes per square.

If we only look at bounding boxes with high confidence scores, and the classes of the grid square those bounding boxes correspond to, we get the final output of YOLO.
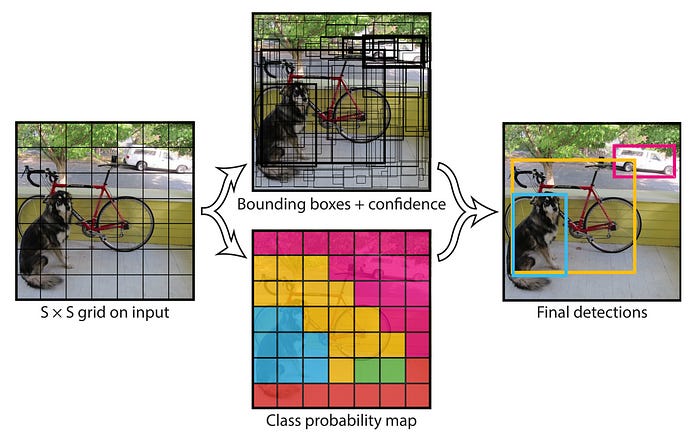
We’ll re-visit the idea of “confidence” when we explore how YOLO is trained. For now, let's take a step back and look at YOLO from a higher level.
The Architecture of YOLO
The cool thing about YOLO is that it does object detection in “one look”. In one pass of the model both subtasks of class prediction and bounding box prediction are done simultaneously.
We unify the separate components of object detection into a single neural network. — The YOLO paper
Essentially, this is done by YOLO outputting the S x S x C class predictions and the S x S x B x 5 bounding box predictions all in one shot, meaning YOLO outputs S x S x (B x 5 + C) things.

Now that we understand the subtasks YOLO solves, and how it formats an output to solve those problems, we can start making sense of the actual architecture of YOLO.
As we’ve discussed, YOLO is a convolutional network that distills an image into a dense representation, then uses a fully connected network to construct the output.

In reality, the diagram above is somewhat of a simplification of the actual architecture, which is written out below the diagram. Let’s go through a few layers of YOLO to build a more thorough understanding.
First of all, the input image is an RGB image, meaning it has some width and height and three color channels. It looks like YOLO is designed to receive a square RGB image of width 448 and height 448. If you want to do YOLO on a smaller or larger image, you can just resize the image into 448 x 448.

The first layer of YOLO is listed as 7x7x64-s-2 , which means we have a convolutional layer with 64 kernels of size 7x7 that have a stride of 2.
When a convolutional model has multiple kernels, each of those kernels consists of different learned parameters, and they work together to make the final output.

In this particular layer, the kernels have a width and a height of 7, and instead of moving by one space at a time, it moves by two.

So, the first convolutional layer consists of 64 kernels of size 7x7 and a stride of 2.
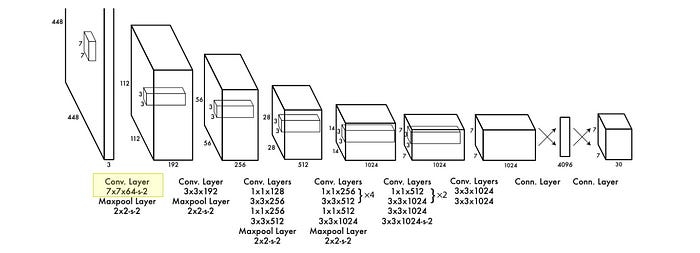
After the first convolutional layer, the data is passed through a max pool of size 2x2 with a stride of 2.
The kernel of stride 2 reduces the dimension of the input by 1/2, the max pool of stride 2 reduces the dimension of the input by another 1/2, and the 64 kernels converts our 3 color channels to 64 kernel channels. This results in a tensor of shape 112 x 112 x 64 .

The YOLO architecture has many layers, many of which behave fundamentally similarly. I won’t bore you with an exploration of every single layer, but there are a few design details which are worth highlighting.
The idea of a 1 x 1 convolution is interesting, and kind of flies in the face of a normal intuition around convolution. If a kernel is only looking at one pixel, what’s the point?
Recall that a convolution applies a kernel not only to some n x n region of the image, but also all input channels.
So a 1 x 1 convolution is essentially a filter that operates over only the channel dimension, and not the spatial dimension.
You may also wonder “why did the researchers who made YOLO settle on all of these numbers? Why 192 filters vs 200 here? Why a stride of 2 here and a stride of 1 there?”
The honest truth is that researchers usually use a combination of what others have done combined with concepts that seem cool to them. YOLO could probably have some of its network details changed without a major impact on performance. If you choose to build a model like this yourself, you often start with a baseline model and play around with different parameters to see if you can get something better.
One design constraint that YOLO does inherit from many CNNs is the concept of an information bottleneck. Throughout successive layers, the total amount of information is reduced. This is a pervasive concept in machine learning; that by passing data through a bottleneck you force a model to trim away irrelevant information and distill an input into its essence.
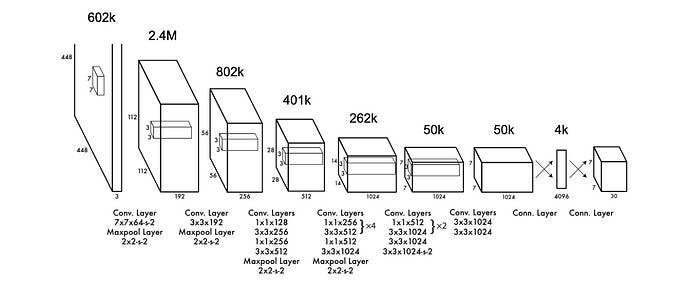
YOLO very heavily reduces the spatial dimension, while expanding the channel dimension, essentially implying that YOLO heavily breaks down a given region of an image, but increases the number of representations for that region.
If you’re finding this post valuable, feel free to share it with friends and colleagues. All content before this point is free and publicly accessible to all readers.
Also, don’t forget to join the IAEE discord. If you’re an IAEE member you have access to weekly lectures by the author of this article. If you’re a free reader, there are plenty of exciting opportunities, conversations, and free resources.
Training YOLO
We’ve covered the nature of the output, as well as the structure of the model. Now let’s explore how the model is trained.
Keep reading with a 7-day free trial
Subscribe to Intuitively and Exhaustively Explained to keep reading this post and get 7 days of free access to the full post archives.