
Cache Augmented Generation — Intuitively and Exhaustively Explained
A new way to inject context into LLMs


In this article we’ll discuss “Context Augmented Generation”, a new approach that allows data scientists to efficiently inject large amounts of contextual information into LLMs.
I’ve heard KV Caching referred to as a “RAG killer,” but I don’t think that’s the case. In this article, we’ll explore what CAG is and exactly what it’s good for.
Who is this useful for? Anyone who’s currently developing applications that interface AI with large amounts of contextual information.
How advanced is this post? This article is geared towards intermediate to experienced data scientists/engineers.
Prerequisites: To get the most out of this article, I recommend having a strong understanding of transformers and LLMs in general. If you find yourself lost, these will both be good resources for understanding LLMs and transformers to a greater depth:


If you’re more of a beginner and know very little about the transformer architecture, I recommend the following articles:


I also recommend having a solid understanding of RAG.


Note: The code in this article is derivative from this excellent article. I’ll be breaking it down further and adding some modifications for explanation sake, but I highly recommend this article if you’re looking for a quick rundown of CAG.
A Brief Review of Retrieval Augmented Generation
Depending on who you are and what your application is, “Retrieval Augmented Generation” RAG can take on many different forms. The fundamental idea of RAG is to stick contextually relevant information into a language models prompt, and then in the same prompt ask some question.

Originally, RAG was created to make relatively weak LLMs better at questions that require specific information. The idea was that language models have a decent ability to reason, but they don’t have enough room to know all the information that might be relevant to every question. If we inject relevant information into an LLM, then it can supplement its internal knowledge with this externally sourced information to come up with better answers to questions.
As AI has progressed, the emphasis on making models better at knowledge-intensive tasks has waned in the RAG space. Massive multi-trillion parameter models are more and more able to remember a lot of information, making RAG over general questions less relevant.

Lately, the emphasis on RAG has shifted to task-specific and private information. It doesn’t matter how much public information a language model might know, if you ask a language model to help you prepare your taxes, it can’t do that without seeing relevant information about your business. Thus, enterprise customers with large internal information (medical, legal, construction, logistics) are still very much in the purview of RAG.
And RAG has been evolving to meet the challenges of those domains. I just released a big article on how to make robust RAG systems for enterprise environments:

RAG is great, I personally work for a company that’s been using RAG with great effect in environments with large amounts of proprietary data. But, like any technology, RAG has some drawbacks.
Problems with RAG
Like any technology, RAG has its costs and benefits. The authors of the paper we’ll be discussing mention a few potential drawbacks to the approach:
The need for real-time retrieval introduces latency, while errors in selecting or ranking relevant documents can degrade the quality of the generated responses. Additionally, integrating retrieval and generation components increases system complexity, necessitating careful tuning and adding to the maintenance over- head. — From the CAG paper, on the drawbacks of RAG.
While latency and complexity are certainly valid considerations, the main thrust of the paper is that RAG can cause errors due to poor retrieval quality. This boils down to the essential way RAG functions.
In the vast majority of RAG implementations, the overall system consists of the following elements:
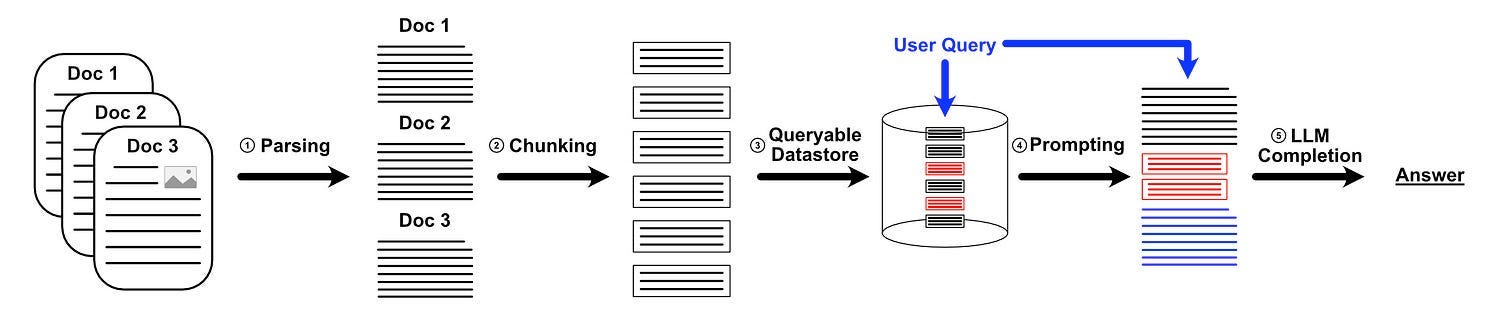
Parsing: re-represents complex documents like PDFs and HTML files into content an LLM can readily understand.
Chunking: divides that parsed content into small chunks. The idea is that these chunks contain manageable bites of information which are neither too big nor too small and can be mixed together to provide context to an LLM from a variety of documents.
Embedding in a Queryable Manner: all the chunks get passed to a special embedding model which represents each chunk as a vector. The user's query is passed through the same model, resulting in a vector. Retreival is ultimately done by comparing the similarity of the vectors of the chunks with the vector of the query
Augmented Prompting: A query is constructed consisting of the system prompt, the retrieved chunks, and the users query.
LLM Completion: The augmented prompt, with retrieved context and user query, is passed to an LLM for a generation.
“Cache Augmented Generation” (CAG) still requires parsing (step 1), some flavor of augmentation (step 4), and an LLM to do completion (step 5), but replaces chunking and embedding with a different approach. The authors of the CAG paper claim that the retrieval step is a major drawback of RAG, and that incorrect retrievals are a major source of performance degradation in many RAG systems.

The Fundamental Idea of CAG
In its most naive sense, CAG says “Why bother retrieving information? Just stick all of the context into the LLM”. They justify this by citing the recent advent of large context models.
Recent advances in long-context LLMs have extended their ability to process and reason over substantial textual inputs. For example, Llama 3.1 [1] was trained with a 128K context length, and its effective context length is 32K in Llama 3.1 8B and 64K in Llama 3.1 70B [3]. This 32K to 64K context window is sufficient for storing knowledge sources such as internal company documentation, FAQs, customer support logs, and domain-specific databases, making it practical for many real-world applications. — From the CAG paper
Have any questions about this article? Join the IAEE Discord.
If you have a knowledge base that can fit into the context window of your model, then this is a very compelling option. Why risk building some RAG pipeline with a retrieval system that might miss some critical information when you can just pass all of the data into the LLM?
There are a few reasons, but the main ones are cost and computational time.
Every time you pass a query through your language model, regardless of how small that query is, you’ll need to pass your whole knowledge base through the LLM. This can cost an expensive amount of time and money, especially for large context sizes and models.

One of the fundamental ideas of CAG is to employ a “key-value cache” to get around this problem. Basically, we can pass just the context through our model, and then store all of the keys and values throughout our LLM. Essentially, this allows us to store how an LLM thinks about our knowledge base.
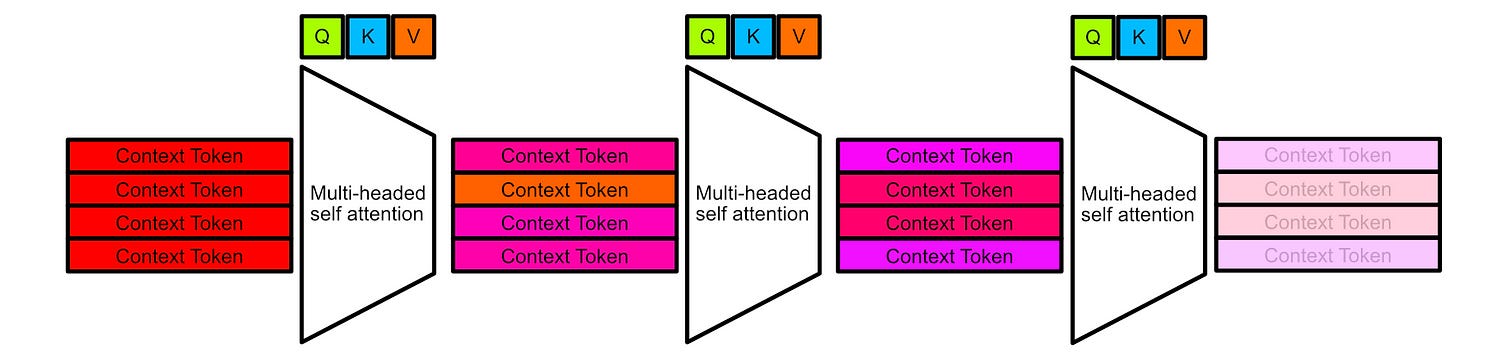
We can then save these values for later. When we get a query, we can load up the calculations from our context and then just compute those that are relevant to the new query.

This works because modern LLMs generate output “causally”, meaning throughout an LLM, a given token is only influenced by previous tokens.
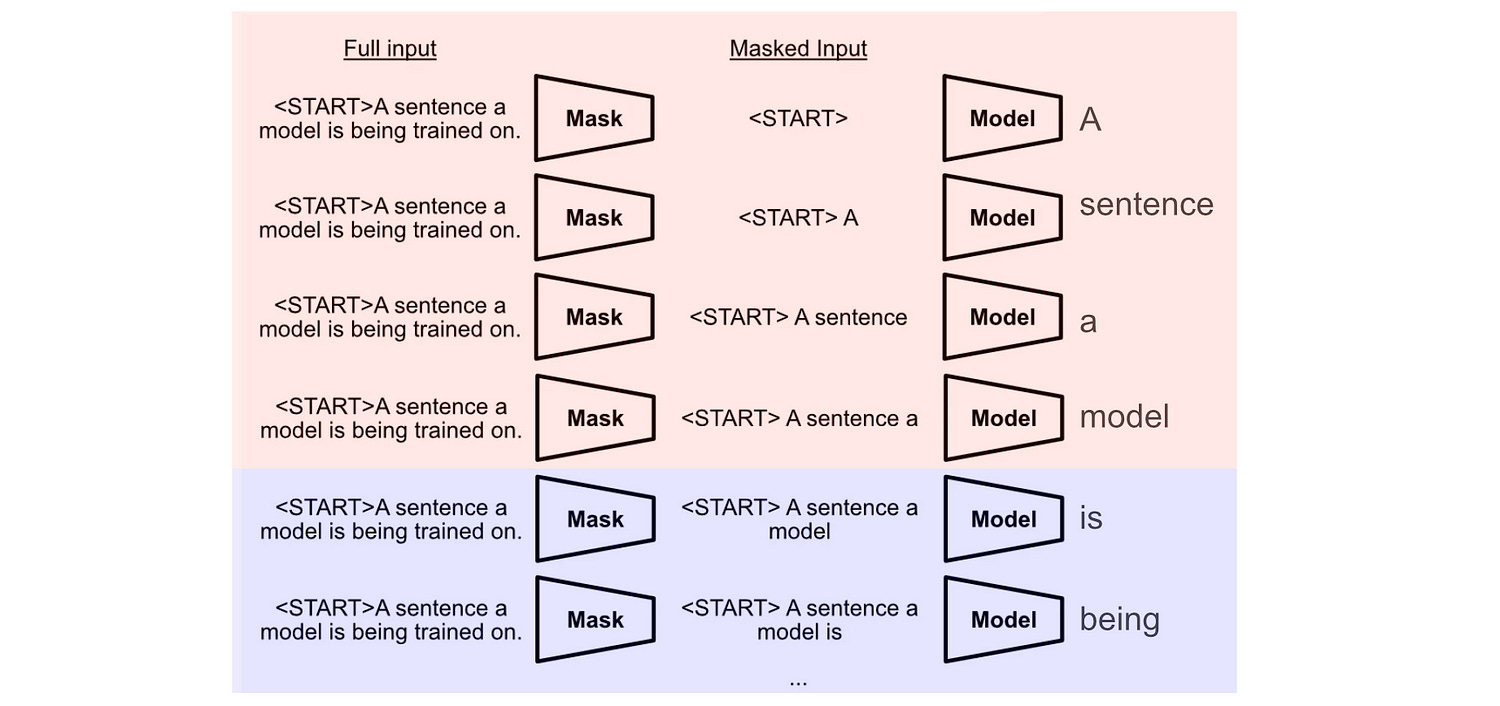
So, if we put the context at the beginning of the input to our model, the contextual calculations will be the same regardless of what query we append to the end of the context.
The mechanism used to store this information is called a “key value” cache, which is a cornerstone implementation detail of how modern LLMs are served. In a key-value cache, the keys and values throughout various attention layers are saved, effectively saving the intermediary representation throughout the model so that they can be used in further autoregressive generation passes. I’ll make a “By Hand” article on key value caching soon, but for now, you can think through my by-hand article on self-attention if you want to work through why caching only the key and value is required.

Let’s explore how CAG can be implemented in practice.
Implementing CAG
Full code can be found here, and is based on this article.
Downloading the Model
First of all, we’re going to need to install bitsandbytes
!pip install -U bitsandbytesWe’re going to be using bitsandbytes to load an LLM via a process called “quantization”. I’m planning on covering bitsandbytes in a future article but, basically, if all the parameters in an LLM look like this:
1.1214
-1.0001
0.9328
0.0000
-0.2312
1.8273
-2.0134
0.5789
-0.0001
0.4444we’re going to load them at a reduced precision which is expressable with a smaller memory footprint:
1.1250
-1.0000
0.9375
0.0000
-0.2500
1.8125
-2.0000
0.5625
0.0000
0.4375This means our model still has the same fundamental parameters, just rounded to fit within a less precise representation. This will result in our model being slightly less performant but with a massively reduced memory footprint.
to do that, we can set up authentication with HuggingFace
from google.colab import userdata
import os
# Retrieve the Hugging Face token from Colab secrets
hf_token = userdata.get('HuggingFace')
# Set the environment variable so that Hugging Face Transformers uses it
os.environ['HF_TOKEN'] = hf_tokenConfigure how we want bitsandbytes to quantize our data, then download our model with quantization.
#importing libraries for downloading model
import torch
from transformers import (
AutoTokenizer,
BitsAndBytesConfig,
AutoModelForCausalLM)
import bitsandbytes as bnb
from transformers.cache_utils import DynamicCache
#configuring quantization
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16)
#downloading model with quantization
model_id = "meta-llama/Meta-Llama-3.1-8B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=bnb_config,
device_map='auto')Here, BitsAndBytesConfig is saying that we’ll be quantizing all model parameters into a four-bit representation. We’re also doing some fancy recommended stuff to encourage our quantization to be more accurate to the original LLM parameters, I’ll be covering stuff like this in more detail when I cover bitsandbytes.
After we set quantization, we’ll download our tokenizer and model. The tokenizer allows us to convert text into numbers that a language model can understand, and then convert numerical output from our model back into words.
Then, when we download the LLM we’ll be using, we pass in the quantization_config , which loads the model in a 4-bit representation. None of this is relevant to context-augmented generation, but hey, this is an exhaustive article.
Defining the Context
The whole point of CAG is to be able to inject some context into a language model. For this toy example, I copied the Franz Ferdinand (band) Wikipedia article and pasted the content into a text block. We’ll use that as our context in this example.
This context is truncated. Full context can be found here.
.knowledge = """
Franz Ferdinand are a Scottish rock band formed in Glasgow in 2002. Their original line-up was composed of Alex Kapranos (lead vocals, guitar, keyboards), Nick McCarthy (guitar, keyboards, vocals), Bob Hardy (bass, percussion) and Paul Thomson (drums, percussion, backing vocals). Julian Corrie (keyboards, guitar, backing vocals) and Dino Bardot (guitar, backing vocals) joined the band in 2017 after McCarthy left during the previous year, and Audrey Tait (drums, percussion) joined the band after Thomson left in 2021. The band were categorised as a post-punk revival band and garnered multiple UK top 20 hits.[1] They have been nominated for several Grammy Awards and have received two Brit Awards—winning one for Best British Group—as well as one NME Award.
The band's first single, "Darts of Pleasure", just missed out on the Top 40 of the UK Singles Chart, peaking at number 44. Their second single, "Take Me Out", proved their big commercial breakthrough, peaking at number three. "Take Me Out" charted in several other countries and earned a Grammy nomination for Best Rock Performance by a Duo or Group with Vocal; it became the band's signature song. Their debut album Franz Ferdinand won the 2004 Mercury Prize and earned a Grammy nomination for Best Alternative Album.
In 2005, the band released their second studio album, You Could Have It So Much Better, produced by Rich Costey. It peaked within the top-ten in multiple countries and earned Grammy-nominations for Best Alternative Album and for one of the singles, "Do You Want To". The band's third studio album, Tonight: Franz Ferdinand, was released in January 2009; by then the band had shifted from a post-punk-focused sound to a more dance-oriented sound. A remix album of Tonight, titled Blood, was released in July 2009.
Four years after the release of Tonight, the band released their fourth studio album, Right Thoughts, Right Words, Right Action, in August 2013. In 2015, Franz Ferdinand and American rock band Sparks formed the supergroup FFS and released a one-off album, FFS, in June 2015. The band underwent multiple line-up changes following FFS, beginning with McCarthy's departure in 2016. After acquiring Corrie and Bardot, the band released their fifth studio album Always Ascending in February 2018. Thomson departed in 2021 and was replaced by Tait. The band's sixth studio album, The Human Fear, was released in January 2025 to commercial success.
History
Formation (2001–2003)
The Archduke Franz Ferdinand of Austria inspired the band's name.
The band's members played in various bands during the 1990s, including The Karelia, Yummy Fur, 10p Invaders, and Embryo. Alex Kapranos and Paul Thomson met at a party and began a close friendship and played together in Yummy Fur, and subsequently teamed up to write songs. Around the same time, Kapranos taught his friend Bob Hardy how to play bass after being given a bass by Mick Cooke of Belle & Sebastian. Kapranos met guitarist Nick McCarthy, who had returned to Scotland after studying jazz bass in Germany, in 2001.[2]
Once the members came together, they settled on the name Franz Ferdinand for their band. The name was originally inspired by a racehorse called Archduke Ferdinand.[3] After seeing the horse win the Northumberland Plate in 2001, the band began to discuss Archduke Franz Ferdinand and thought it would be a good band name because of the alliteration of the name and the implications of the Archduke's death: his assassination was a significant factor in the lead-up to World War I.[4] In an interview, Hardy recollected that "mainly we just liked the way it sounded. We liked the alliteration." Kapranos continued, saying "he was an incredible figure as well. His life, or at least the ending of it, was the catalyst for the complete transformation of the world and that is what we want our music to be. But I don't want to over-intellectualise the name thing. Basically a name should just sound good ... like music." Thomson concluded, saying “I like the idea that, if we become popular, maybe the words Franz Ferdinand will make people think of the band instead of the historical figure.”[5]
Franz Ferdinand and international breakthrough (2003–2005)
Main article: Franz Ferdinand (album)
The band performing in 2004
In May 2003 the band signed to Laurence Bell's independent record label, Domino Recording Company.[6] The band moved to Gula Studios in Malmö, Sweden, with Cardigans producer Tore Johansson to record their debut album. In the latter part of 2003, the band released their debut single, "Darts of Pleasure". In January 2004, the single "Take Me Out" reached No. 3 in the UK charts. The album, Franz Ferdinand, was released in early 2004, debuting at No. 3 in the UK Albums Chart in February 2004, and at No. 12 in the Australian album charts in April 2004. The album only reached the lowest levels of the Billboard 200 album charts in the US as of early 2004, but reached the top 5 of the indie rock chart and the Heatseeker chart for debut artists. After a couple of North American tours and heavy rotation of the "Take Me Out" video on MTV, the album eventually reached No. 32 on the Billboard 200 later in 2004, and sold over a million copies in the United States.[2] Franz Ferdinand received a generally strong positive response from critics. NME rated it 9 out of 10, and said that the band was the latest in the line of art school rock bands featuring the Beatles, The Rolling Stones, The Who, Roxy Music, the Sex Pistols, Wire, Travis and Blur.
...
"""Creating the KV Cache
HuggingFace has a variety of “KV Caching” strategies, the explanation of which warrants an article within itself. Basically, though, if you have some transformer-style model generating text via causal autoregression (which is basically all modern generative LLMs), KV Caching makes it so you don’t have to re-compute previous tokens over and over again for each newly generated output. Typically it’s used for keeping track of values within the model as it’s generating an output, but we can also manually define the previous values that need to be saved in the cache. Here’s a high-level example of that from the HuggingFace docs:
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, DynamicCache
tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-chat-hf", torch_dtype=torch.float16).to("cuda:0")
inputs = tokenizer("I like rock music because", return_tensors="pt").to(model.device)
# here the past_key_values are initialized as empty, but they could have
# some content. We'll be using this functionality to implement CAG
past_key_values = DynamicCache()
out = model.generate(**inputs, do_sample=False, max_new_tokens=20, past_key_values=past_key_values)Recall that the fundamental idea of CAG is to pre-compute passing the context through the model so that we can save on computational costs. We do that by constructing a KV cache of the keys and values generated throughout the LLM based on a particular contextual input.
def preprocess_knowledge(
model,
tokenizer,
prompt: str) -> DynamicCache:
"""
Prepare knowledge kv cache for CAG.
Args:
model: HuggingFace model with automatic device mapping
tokenizer: HuggingFace tokenizer
prompt: The knowledge to preprocess, which is basically a prompt
Returns:
DynamicCache: KV Cache
"""
embed_device = model.model.embed_tokens.weight.device # check which device are used
input_ids = tokenizer.encode(prompt, return_tensors="pt").to(embed_device)
past_key_values = DynamicCache()
with torch.no_grad():
outputs = model(
input_ids=input_ids,
past_key_values=past_key_values,
use_cache=True,
output_attentions=False,
output_hidden_states=False)
return outputs.past_key_valuesIn this code, the function preprocess_knowledge takes in the model, its corresponding tokenizer, and a prompt (representing the context we want to bake into our KV cache), and then outputs a KV Cache based on running the prompt through the model.
First, we do some bookkeeping by setting embed_device, this just defines if the model is on the CPU or GPU. After that, we run our prompt through our tokenizer to get it ready to pass to the model, and we put the tokens on whatever device the model is on.
We then define an empty KV Cache with past_key_values = DynamicCache(). This isn’t strictly necessary I don’t think, as if we set use_cache=True I think a DynamicCache() will automatically be generated, but I like how explicit this is so I’m not changing it.
Anyway, we can then pass our context through our model. We set torch.no_grad() to skip gradient calculation (because we’re doing inferencing and not training), then pass in data to the model. input_ids is the tokenized input, past_key_values is our initialized (and maybe not completely necessary) KV Cache, use_cache says we want to use a KV Cache, output_attentions is set to false because we don’t need that, and output_hidden_states is also set to false because we don’t need it. I don’t actually know if there’s any benefit to explicitly setting these as false, maybe it saves on compute resources, whatever.
After we pass our query (which is the context we want to save as a cache) through our model, we get some output. By returning outputs.past_key_values we’re getting the KV Cache which corresponds to the creation of that output.
One quirk of Context Augmented Generation is that the system prompt is typically baked in with the context explicitly. In most LLM contexts the system prompt is provided to a model first, and then things like context and queries are provided later. This is useful because, as the token processes the context, it can do so with the system prompt in mind. However, the idea of CAG is to save the context at the beginning of the prompt, up to the query. If you want a system prompt to be before the context provided, then you’ll have to include that in the KV Cache.
def prepare_kvcache(documents, answer_instruction: str = None):
# Prepare the knowledges kvcache
if answer_instruction is None:
answer_instruction = "Answer the question with a super short answer."
knowledges = f"""
<|begin_of_text|>
<|start_header_id|>system<|end_header_id|>
You are an assistant designed to answer questions from wikipedia articles.<|eot_id|>
<|start_header_id|>user<|end_header_id|>
Context information is bellow.
------------------------------------------------
{documents}
------------------------------------------------
{answer_instruction}
Question:
"""
# Get the knowledge cache
kv = preprocess_knowledge(model, tokenizer, knowledges)
kv_len = kv.key_cache[0].shape[-2]
print("kvlen: ", kv_len)
return kv, kv_len
knowledge_cache, kv_len = prepare_kvcache(documents =knowledge)
# kvlen: 610That’s exactly what this function does. it adds a system prompt before the context and then passes the system prompt along with the context into our preprocess_knowledge function. If you wanted the KV Cache to be more general purpose, you could experiment with providing a system prompt after the context so that baking a system prompt into the context in the KV Cache isn’t required.
At this point, we have a KV Cache and are ready to use it for cache-augmented generation.
Doing CAG with our KV Cache
Before we get into actually creating a response with CAG, there's one useful helper function we should implement.
def clean_up(kv: DynamicCache, origin_len: int):
"""
Truncate the KV Cache to the original length.
"""
for i in range(len(kv.key_cache)):
kv.key_cache[i] = kv.key_cache[i][:, :, :origin_len, :]
kv.value_cache[i] = kv.value_cache[i][:, :, :origin_len, :]Recall that the primary reason KV caches exist is to make autoregressive (one token at a time) output faster by making it so we don’t have to re-compute keys and values for previous tokens. Once we call our model, our model will add it’s response to the KV Cache as it generates. If we want to call our LLM multiple times, we’ll have to clean up the response portion of the cache when we make a new inference.
this code iterates through all layers in the transformer via for i in range(len(kv.key_cache)), then truncates both the keys and values to be the original sequence length of the context, discarding any content that comes after. If we run this on a newly constructed KV Cache than nothing would happen, but this is necessary in generating a new output using a KV Cache that’s been used in a previous run.
The shape of both the key_cache and value_cache is [batch, num_heads, sequence_length, head_dim] , which is why we’re truncating on only a single dimension up to the sequence length.
Now that we have that code set up, we can go ahead and generate some output using CAG.
def generate(
model,
input_ids: torch.Tensor,
past_key_values=None,
max_new_tokens: int = 300
) -> torch.Tensor:
"""
Greedy decoding generation.
Args:
model: HuggingFace model with device mapping
input_ids: Prompt input token IDs
past_key_values: Optional KV cache for fast generation
max_new_tokens: Number of tokens to generate
Returns:
Generated token IDs (excluding prompt)
"""
device = model.device if hasattr(model, "device") else model.model.embed_tokens.weight.device
input_ids = input_ids.to(device)
generated = input_ids.clone()
for _ in range(max_new_tokens):
with torch.no_grad():
outputs = model(
input_ids=generated[:, -1:] if generated.shape[1] > 1 else input_ids,
past_key_values=past_key_values,
use_cache=True
)
next_token = outputs.logits[:, -1].argmax(dim=-1, keepdim=True)
past_key_values = outputs.past_key_values
generated = torch.cat([generated, next_token], dim=-1)
if next_token.item() in model.config.eos_token_id:
break
return generated[:, input_ids.shape[-1]:]This function generates some output given a model, tokenized query, and pre-loaded KV Cache with a system prompt and context.
First it checks the device the model is on, then it moves the tokenized input_ids to that device. It also clones the tokenized input and renames it as generated. Then, max_new_tokens rounds of autoregressive generation are performed.

Because past_key_values is being used as a KV cache, the model only expects a single input token. Once that input token is passed into the model, then it’s added to the cache and doesn’t need to be added again. That is accomplished by input_ids=generated[:, -1:] if generated.shape[1] > 1.
Once that last token is passed throught the decoder, it results in logits which can be softmaxed to produce a new token prediction, via outputs.logits[:, -1].argmax(dim=-1, keepdim=True), we can update our cache to include the new token via past_key_values = outputs.past_key_values , and we can add the newly predicted token to the list of generated tokens via generated = torch.cat([generated, next_token], dim=-1). We also check of the generated token is the end of sequence utility token so we can stop generating new output.
At this point, because generated is a copy of the original input_ids, it contains both the context we gave the model and the generated response. We can get only the newly generated output by getting after the input context sequence length via generated[:, input_ids.shape[-1]:].
Finally, we can tie all this together and do context-augmented generation via the following:
query = 'recite the first paragraph of "Franz Ferdinand and international breakthrough (2003–2005)" from wikipedia without referencing the internet. Do it from memory.'
clean_up(knowledge_cache, kv_len)
input_ids = tokenizer.encode(query, return_tensors="pt").to(model.device)
output = generate(model, input_ids, knowledge_cache)
generated_text = tokenizer.decode(output[0], skip_special_tokens=True, temperature=None)
print(f"Response of the model:\n {generated_text}")This
cleans up the knowledge cache we defined previously, allowing us to run the same code block several times and not have our responses accumulate
tokenizes the query
generates response tokens from the model based on the tokenized query and KV cache of our context
decodes those tokens into text
Some Thoughts
Part of the reason I was introduced to context augmented generation was because there was an instance that it was somehow a replacement to retrieval augmented generation. In working at a company that does a lot of RAG work, I was naturally interested in this.
For a long time, long context window models have been knocking on the door of RAG, but a “long” context is still relatively short compared to many of the sets of documents that require a RAG approach. Law, medical, and engineering applications often have tens or hundreds of thousands of documents. CAG is an efficient way to employ long context windows but does not magically make models capable of handling truly large knowledge bases.
I, personally, see CAG as an exciting tool in the RAG developer's toolbelt, rather than a replacement to RAG. It’s not hard to imagine retrieving KV Caches rather than textual context, allowing for a RAG system to select which long context might be relevant to an LLM. Thus, long context window models would be able to be efficiently applied to very large documents, but the documents themselves could be queried from massive stores of documents that could not exist in a single model context window.
Also, while long context is generally seen as more performant than RAG tit-for-tat, there is some evidence that long context models aren’t as performant as one might hope. It’s hard to say if long context is better than RAG in each use case.
In other words, I see CAG as a way to make context windows much larger, but not as a way to replace RAG in many of the applications it’s currently used in.