


DeepSeek-R1 — Intuitively and Exhaustively Explained
An “Aha” moment in Artificial Intelligence


In this article we’ll discuss DeepSeek-R1, the first open-source model that exhibits comparable performance to closed source LLMs, like those produced by Google, OpenAI, and Anthropic. This heightened performance is a major milestone in artificial intelligence, and is the reason DeepSeek-R1 is such a hot topic.
We’ll begin our exploration by briefly covering some of the fundamental machine learning ideas that DeepSeek builds off of, then we’ll describe some of the novel training strategies used to elevate DeepSeek-R1 past other open source LLMs. We’ll spend a fair amount of time digging into “Group Relative Policy Optimization”, which DeepSeek uses to elevate it’s reasoning ability, and is largely the source of it’s heightened performance over other open source models.
Once we have a thorough conceptual understanding of DeepSeek-R1, We’ll then discuss how the large DeepSeek-R1 model was distilled into smaller models. We’ll download one of those smaller DeepSeek models and use it to make inferences on consumer hardware. Finally, we’ll close with speculation as to how DeepSeek may impact the state of the art of AI moving forward.
By the end of this article you will understand what DeepSeek is, how it was created, how it can be used, and the impact it will have on the industry.
Who is this useful for? Anyone who wants to form a complete understanding of the state of the art of AI.
How advanced is this post? This article contains an intuitive description of cutting edge AI concepts, and should be relevant to readers of all levels.
Pre-requisites: None
What is Deep Seek, and Why Does it Matter?
The reason you probably opened this article is because the internet is freaking out over DeepSeek-R1, a new model released by the Chinese AI Startup DeepSeek.
The company DeepSeek released a variety of models via an open source and permissive license on November 2nd 2023, with DeepSeek-R1 being one such model. DeepSeek also released the paper “DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning” which includes benchmark results showing that DeepSeek-R1 is comparable to OpenAI’s o1 model in a variety of tasks requiring complex reasoning. This makes DeepSeek-R1 exciting because it’s the first open source and transparently documented language model to achieve this level of performance.

Before we dive into the paper, I want to cover some ideas in AI which are relevant to our exploration. These are brief descriptions of topics which I think are useful in forming a complete understanding of DeepSeek. Feel free to skip past the foundations if you don’t need a refresher on any of these ideas.
Foundation 1) Training
Fundamentally, AI models can be conceptualized as a big box of dials which can be adjusted to be better at a given task. When training a language model for instance you might give the model a question. Then, you use the dials within the model to generate some answer, which at first is pretty bad.

you then update the dials to make the desired output a bit more likely

and after doing this after millions if not billions of examples, you get some model that’s decent at responding to questions. If you want to better understand this general process, check out my article on Neural Networks.

DeepSeek uses a refined system of this general approach to create models with heightened reasoning abilities, which we’ll explore in depth.
Foundation 2) The Transformer
The transformer is a critical architecture in AI, and is the fundamental skeleton from which virtually all cutting edge AI models, including DeepSeek, are derived. I don’t think it’s critical to understand the ins and outs of the transformer, but I did write an article on the subject if you’re curious.

Basically, the transformer is a contextualization model which specializes in comparing and combining information. For instance, if you represent each word in a sequence of words as a vector, you can feed that into a transformer. The transformer will then spit out a complex soup of data which represents the entire input in some abstract way. This abstract soup of contextualization is used to create higher order reasoning capabilities.

By creating and reasoning about these complex combinations of data, the transformer can do incredibly complex tasks which were not even considered possible a few years ago. The discovery of the transformer, to a large extent has fueled the explosion of AI we see today.
Foundation 3) The Generative Pre-Trained Transformer (GPT)
The original transformer was initially released as an open source research model specifically designed for english to french translation. It was OpenAI that really catapulted the architecture into the limelight with the “The Generative Pre-Trained Transformer” (or GPT for short, as in ChatGPT).
While the original transformer was designed with two parts, one to take in an input and another to produce an output

GPT clobbered everything into a single unified model which treated the input and the output, essentially, identically.

Because GPT didn’t have the concept of an input and an output, but instead just took in text and spat out more text, it could be trained on arbitrary data from the internet. Throughout subsequent research, OpenAI discovered that this architecture, when scaled with more and more data and larger and larger parameter counts, could achieve unprecedented capabilities.
This style of modeling has been subsequently referred to as a “decoder only transformer”, and remains the fundamental approach of most large language and multimodal models. DeepSeek is an example of a decoder only style transformer.
For more information, you can refer to the following:

Foundation 4) Chain of Thought
Soon after models like GPT were popularized, researchers and normal users alike began experimenting with interesting prompting strategies. One such strategy was called “chain of thought”.
Basically, instead of prompting the model to provide an answer, you first prompt the model to think about the answer before providing it.
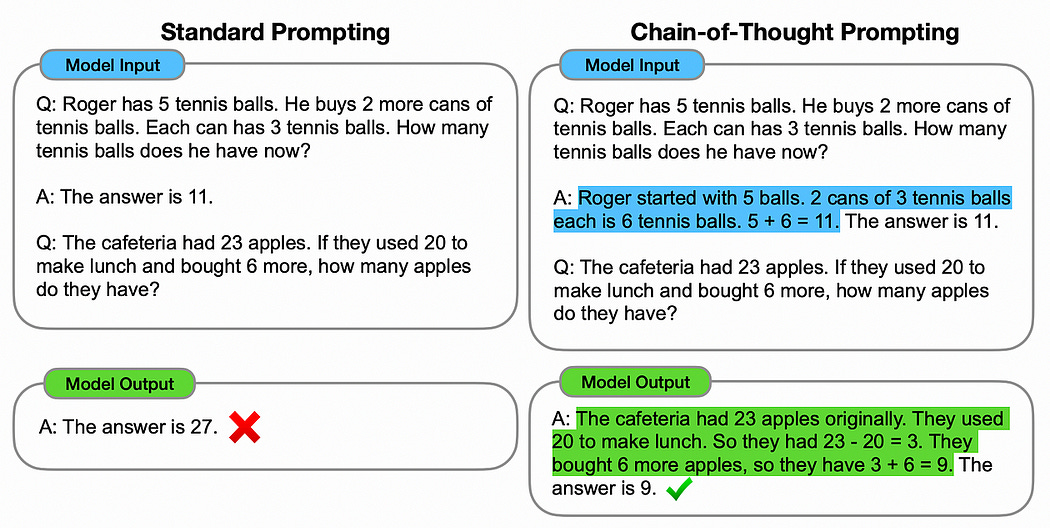
this is a subtle but incredibly powerful technique. Transformers generate their output one word at a time, using previous words to produce future words. Chain of thought allows the model to generate words which make the final generation of the ultimate answer easier.
I have an article which discusses chain of thought, as well as some other similar approaches:

One of the major characteristics of DeepSeek-R1 is that it uses a robust training strategy on top of chain of thought to empower it’s heightened reasoning abilities, which we’ll discuss in depth.
Foundation 5) Low Rank Adaptation (LoRA)
Some people might be confused as to why I’m including LoRA on this list of fundamental ideas. It doesn’t directly have anything to do with DeepSeek per-se, but it does have a powerful fundamental concept which will be relevant when we discuss “distillation” later in the article.
As transformers evolved to do many things incredibly well, the idea of “fine-tuning” rose in popularity.
The core question of fine-tuning is, if some language model knows stuff, how do I make it know about my stuff. If researchers make a model that talks a certain way, how do I make that model talk the way I want it to talk? In essence, how do I get a big general purpose model to act the way I need it to act for my application.
To achieve this you essentially train the model again. Some researchers with a big computer train a big language model, then you train that model just a tiny bit on your data so that the model behaves more in line with the way you want it to. This is great, but there’s a big problem: Training large AI models is expensive, difficult, and time consuming, “Just train it on your data” is easier said than done.
“Low Rank Adaptation” (LoRA) took the problems of fine tuning and drastically mitigated them, making training faster, less compute intensive, easier, and less data hungry. The way they did this was with an assumption that proved both very true and incredibly powerful.
AI models like transformers are essentially made up of big arrays of data called parameters, which can be tweaked throughout the training process to make them better at a given task.
The team behind LoRA assumed that those parameters were really useful for the learning process, allowing a model to explore various forms of reasoning throughout training. Once the model is actually trained, though, the AI model contains a lot of duplicate information.

The authors of the LoRA paper assumed you can update a model with a relatively small number of parameters, which are then expanded to modify all of the parameters in the model. In fancy AI speak, this is called “Low Rank Adaptation”.

And it turned out this assumption was correct. You can fine tune a model with less than 1% of the parameters used to actually train a model, and still get reasonable results.
In contrast, however, it’s been consistently proven that large models are better when you’re actually training them in the first place, that was the whole idea behind the explosion of GPT and OpenAI. Models trained on a lot of data with a lot of parameters are, generally, better.
These two seemingly contradictory facts lead to an interesting insight: A lot of parameters are important for a model having the flexibility to reason about a problem in different ways throughout the training process, but once the model is trained there’s a lot of duplicate information in the parameters. We’ll revisit why this is important for model distillation later.
Feel free to check out this article for more information:

For now, though, let’s dive into DeepSeek.
The Fundamental Idea of The DeepSeek Family of Models
The paper “DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning” is what lit off all this excitement, so that’s what we’ll be chiefly exploring in this article. I’ll be referring to this as the “DeepSeek-R1 paper”, in which a variety of models are referenced.
DeepSeek-V3-Base
DeepSeek-R1-Zero
DeepSeek-R1
Llama-Based Distilled Models with 1.5B, 7B, 14B, and 70B parameters
Qewn-Based Distilled Models with 8B and 32B parameters
Lets get an idea of what each of these models is about.
DeepSeek-V3-Base
We won’t be covering DeepSeek-V3-Base in depth in this article, it’s worth a discussion within itself, but for now we can think of DeepSeek-V3-Base as a big transformer (671 Billion trainable parameters) that was trained on high quality text data in the typical fashion. So, you take some data from the internet, split it in half, feed the beginning to the model, and have the model generate a prediction. you then compare the models prediction vs the actual data that followed, and update the model to be more likely to predict the actual output.

You do this on a bunch of data with a big model on a multimillion dollar compute cluster and boom, you have yourself a modern LLM. Of course, DeepSeek-V3-Base employs some interesting subtleties, but it’s essentially just a standard decoder only transformer like Llama, Mixtral, GPT, etc.
DeepSeek-R1-Zero
This is where things get interesting.
DeepSeek-R1-Zero is essentially DeepSeek-V3-Base, but further trained using a fancy process called “Reinforcement learning”. We’ll be digging into this throughout the article, but the basic idea is this:
They gave DeepSeek two special outputs,
<think>and</think>, which allow the model to think isolated thoughts before producing it’s final outputThey then gave the model a bunch of logical questions, like math questions. The researchers didn’t know exactly what the best approach was to solve these problems, but they could tell if an answer was correct or incorrect.
When DeepSeek answered the question well, they made the model more likely to make similar output, when DeepSeek answered the question poorly they made the model less likely to make similar output.
This is called “Reinforcement Learning” because you’re reinforcing the models good results by training the model to be more confident in it’s output when that output is deemed good.
After doing this process for a while they saw that they got very good results, much better than comparable open source models. but they also noticed some issues. Because the model was essentially coming up with it’s own reasoning process based on it’s own previous reasoning processes, it developed some quirks that were reinforced. It would swap languages randomly, it would create human incomparable output, and it would often endlessly repeat things. To deal with these issues, they created DeepSeek-R1.
DeepSeek-R1
In reinforcement learning there is a joke “Your initialization is a hyperparameter”. Basically, because reinforcement learning learns to double down on certain forms of thought, the initial model you use can have a tremendous impact on how that reinforcement goes.

This is typically seen as a problem, but DeepSeek-R1 used it to its benefit. The team behind DeepSeek created a dataset of high quality examples of chains of thought from various sources:
Good examples from DeepSeek-R1-Zero
they looked through (either manually or with some AI system) the thoughts and responses of DeepSeek-r1-zero and found particularly good examples of the model thinking through and providing high quality answers.
Direct prompting for detailed answers
They prompted DeepSeek-r1-zero to come up with high quality output by using phrases like “think thoroughly” and “double check your work” in the prompt.
Few-shot prompting with a long chain of thought
They provided examples of the types of chain of thought they wanted into the input of the model, with the hopes that the model would mimic these chains of thought when generating new output. This is a popular strategy generally referred to as “in-context learning”.
using these approaches, they collected thousands of examples of DeepSeek-R1-zero creating high quality thoughts and actions, and then fine tuned DeepSeek-V3-Base on those examples explicitly. You can think of this as adjusting DeepSeek-V3-Base to be more in-line with what humans like about the reasoning process of DeepSeek-R1-zero.
They used this data to train DeepSeek-V3-Base on a set of high quality thoughts, they then pass the model through another round of reinforcement learning, which was similar to that which created DeepSeek-r1-zero, but with more data (we’ll get into the specifics of the entire training pipeline later). This created DeepSeek-R1, which achieved heightened performance to all other open source LLMs, on par with OpenAI’s o1 model.
In other words, with DeepSeek-r1-zero the used reinforcement learning directly on DeepSeek-V3-Base. With DeepSeek-r1, they first fine tuned DeepSeek-V3-Base on high quality thoughts, then trained it with reinforcement learning.
Distillation to Llama and Qewn Based models
Once DeepSeek-r1 was created, they generated 800,000 samples of the model reasoning through a variety of questions, then used those examples to fine tune open source models of various sizes. Llama is a family of open source models created by Meta, and Qewn is a family of open source models created by Alibaba. The goal of this was to impart DeepSeek-R1’s robust reasoning abilities onto other, smaller open source models.
So, that’s the high level view. The engineers at DeepSeek took a fairly normal LLM (DeepSeek-v3-Base) and used a process called “reinforcement learning” to make the model better at reasoning (DeepSeek-r1-zero). they then collected examples of good reasoning, fine tuned V3-Base on those examples, then did reinforcement learning again (DeepSeek-r1). They then used that model to create a bunch of training data to train smaller models (the Llama and Qewn distillations).
Now that we have a vague, hand wavy idea of what’s going on, let’s dive into some of the specifics.
Reinforcement Learning
The biggest jump in performance, the most novel ideas in Deep Seek, and the most complex concepts in the DeepSeek paper all revolve around reinforcement learning.
As previously discussed in the foundations, the main way you train a model is by giving it some input, getting it to predict some output, then adjusting the parameters in the model to make that output more likely.
This is called “supervised learning”, and is typified by knowing exactly what you want the output to be, and then adjusting the output to be more similar.
In some problems, though, one might not be sure exactly what the output should be. For instance, we might want our language model to solve some complex math problem where we know the answer, but we’re not exactly sure what thoughts it should use to answer that question. We know if the model did a good job or a bad job in terms of the end result, but we’re not sure what was good or not good about the thought process that allowed us to end up there.

This is where reinforcement learning comes into play. Reinforcement learning, in it’s most simple sense, assumes that if you got a good result, the entire sequence of events that lead to that result were good. If you got a bad result, the entire sequence is bad. Because AI models output probabilities, when the model creates a good result, we try to make all of the predictions which created that result to be more confident. When the model creates a bad result, we can make those outputs less confident.

The DeepSeek team used many examples of math problems, science problems, coding problems, textual formatting problems, and other problems which have known answers. They then got the model to think through the problems to generate answers, looked through those answers, and made the model more confident in predictions where it’s answers were accurate.
So that’s it. Wow. Why is there so much article left?
Well, the idea of reinforcement learning is fairly straightforward, but there are a bunch of gotchas of the approach which have to be accomodated. To deal with these issues, The DeepSeek team created a reinforcement learning algorithm called “Group Relative Policy Optimization (GRPO)”.
Why Group Relative Policy Optimization (GRPO) Exists
I’m planning on doing a comprehensive article on reinforcement learning which will go through more of the nomenclature and concepts. For this article, though, I think GRPO can be described based on its own merits, rather than slogging through a bunch of dense theoretical work that lead up to it.
let’s start with why GRPO exists. Naive reinforcement learning has a few big issues:
Deviation From Goodness: If you train a model using reinforcement learning, it might learn to double down on strange and potentially problematic output. This is, essentially, the AI equivalent of “going down the rabbit hole”, and following a series of sensical steps until it ends up in a nonsensical state. Imagine a reasoning model discovers that discovers through reinforcement learning that the word “however” allows for better reasoning, so it starts saying the word “however” over and over again when confronted with a difficult problem it can’t solve. A popular approach to deal with problems like this is called “trust region policy optimization” (TRPO), which GRPO incorporates ideas from.
Inefficient Performance Estimation: We won’t be covering this in depth, but one of the problems of reinforcement learning is that, sometimes, there is a delay between making an action and getting a reward. In chess, for instance, sacrificing a piece might win you the game, so if the reward is simply the relative material between both players, this type of strategy may be disensentivised using a naive reinforcement learning approach. One common solution for this is to use a “value model” which learns to observe the problem your trying to solve and output a a better approximation of reward which you can train your model on. This is great, but it means you need to train another (often similarly sized) model which you simply throw away after training.
Sample Inefficiency: Once you train a model on reinforcement learning, the model changes, which means the way it interacts with the problem you’re trying to solve changes. So, after you do a bit of reinforcement learning you have to have your model interact with your problem again. Then you train a bit, interact with the problem. Train, interact with the problem. This constant need to re-run the problem throughout training can add significant time and cost to the training process.
With those general ideas covered, let’s dive into GRPO.
The Math of GRPO
This is “Group Relative Policy Optimization” (GRPO), in all it’s glory.

I know this looks like a lot of math, it certainly is, but it’s surprisingly straightforward once you break it down.
First of all, GRPO is an objective function, meaning the whole point is to make this number go up. If we do, that means the model is getting better.

This is a function of ϴ (theta) which represents the parameters of the AI model we want to train with reinforcement learning. So, given the current parameters of our model, we want J_GRPO to go up. If we do that, we’re doing reinforcement learning with GRPO.
The actual structure of the math is a bit complicated. They provide both a theoretical expression representing the data used in GRPO, and a more fleshed out representation.

The abstract representation starts with the character “E” which stands for “expected value”, which says we’ll be calculating some average value based on some data. The point of this is to detail what data we’re going to be operating on, rather than the exact operations we’ll be doing.
There’s two elements within the expected value.

the expression q∼P(Q) means we’ll be randomly sampling queries from all of our queries. So, we have some dataset of math and science questions (P(Q)) and we’ll be sampling random examples (q). Here, ~ means “is sampled from.
The other expression, highlighted in blue, has a few characters we need to clarify. Here, πθ represents the model we’ll be training, and πθold represents a specific version of the model.
From a high level, GRPO is an iterative approach. We do GRPO for a little bit, then try our new model on our dataset of problems. We do GRPO again, test our model out again. Thus there are various versions of πθ , depending on where we are in this process.

throughout the entire GRPO expression, there are three versions of πθ (the model) being referenced
πθrepresents the model right now, so the most recent set of parameters as a result of fine tuning.πθoldrepresents the model that resulted from the previous round of GRPO. So, this is the version of the model used to do the most recent round of testing on the dataπθrefis the model from before we did any GRPO iterations. So, it’s the parameters we used when we first started the GRPO process.
So, going back to the theoretical expression
we’ll sample some question q from all of our questions P(Q) , then we’ll pass the question through πθold, which, because it’s an AI model and AI models deal with probabilities, that model is capable of a wide range of outputs for a given q , which is represented as πθold(O|q) . This is saying πθold can theoretically output a whole range of values O , given a particular question q . The expression with the curly brackets
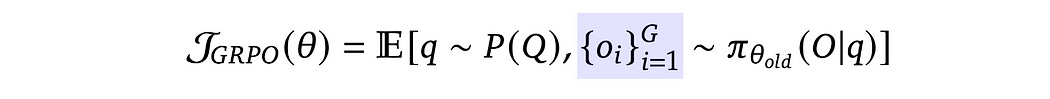
means we’ll be sampling G particular outputs from that possible space of outputs. So {o1, o2, o3, o4, ... , oG} , where o represents some output from the old model, given the query q.
So, in a commercially complex way, this expression says “we’re going to calculate the average of some function. That function will take in some random question, and will be calculated by a few different examples of the same models output to that question”.
The actual function being calculated is the rest of the expression. This consists of the actual GRPO expression, which relies on two other sub-expressions.
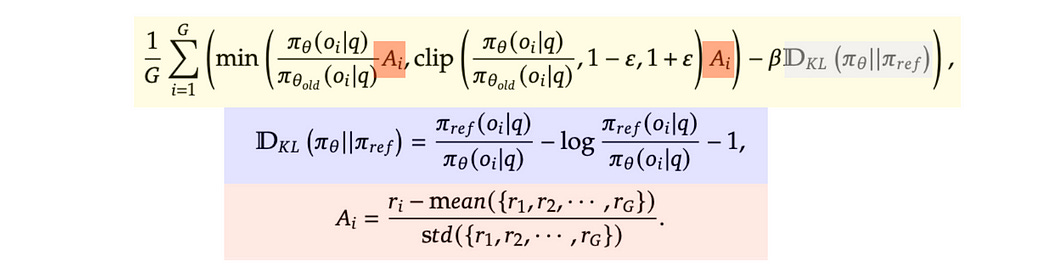
these sub-expressions are referred to as “KL Divergence” (highlighted in blue) and “Advantage” (highlighted in red). Let’s discuss advantage first.
So, recall what we’re doing here. We’re reinforcing what our model is good at by training it to be more confident when it has a “good answer”. The “Advantage” is how we define a good answer.
Recall that we’re working with a bunch of outputs from the same model given the same query.
The first step is to pass these outputs through a reward function

Reward functions can be arbitrarily complex. You could even have a human sit down and say “this answer was good, this answer was bad”. For DeepSeek they’re mostly using mathematical, coding, and scientific questions where they already know the answer. Using this type of data we can simply compare the models output to the known answer (either automatically or by using an LLM) to generate some numeric reward. For instance, you give the model a problem “reverse a linked list”, and give it a reward of 0.1 if it makes code that runs, a reward of 0.3 if the model answers the question correctly, a reward of 0.7 if the result is faster than 90% of human coders answers, etc.
So, we have a set of rewards from the model. Next, we use these rewards to calculate an advantage.

The “Advantage” of the ith output is the reward of the ith output, minus the average reward of all outputs, divided by the standard deviation of the rewards of all outputs.
You might be thinking either “ok duh” or “what did you just say”, and that relies on if you’ve taken a probability and statistics class or not. To avoid going too in the weeds, basically, we’re taking all of our rewards and considering them to be a bell curve.
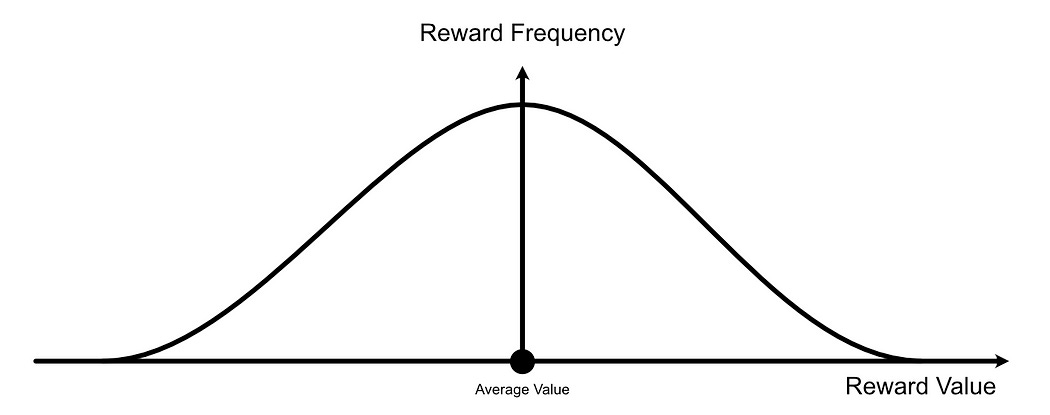
then we’re observing where some particular reward for a particular example exists on this bell curve.
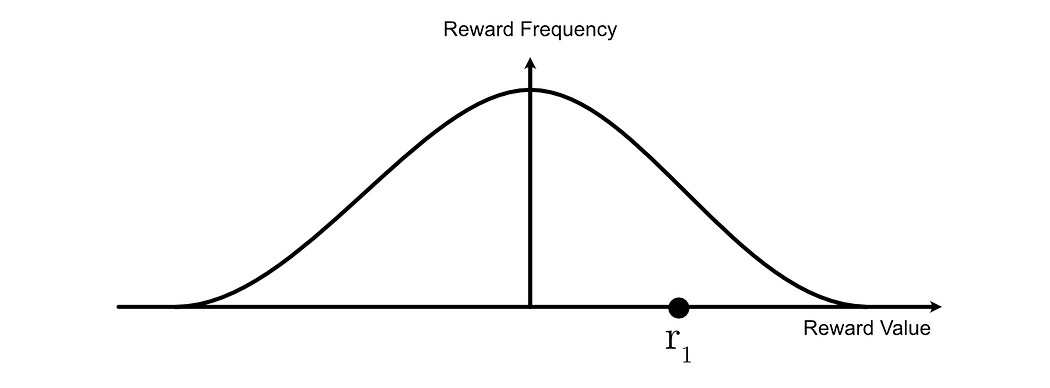
For examples that have a higher reward than average, they will have a positive advantage.

For examples that have a lower reward than average, they will have a negative advantage.

This idea of calculating “advantage” based on how a result compares to other results is critical in GRPO, and is why the approach is called “Group Relative Policy Optimization”. We’re saying “this is a particularly good or bad output, based on how it performs relative to all other outputs.
Now that we’ve calculated the advantage for all of our outputs, we can use that to calculate the lion’s share of the GRPO function.

Specifically, we can calculate this expression.

This is the bulk of the GRPO advantage function, from a conceptual prospective. If this number is big, for a given output, the training strategy heavily reinforces that output within the model.

This expression centers around this ratio. Recall that there are several versions of the model we hold throughout the training process:
πθrepresents the model right now, so the most recent set of parameters as a result of our current reinforcement learning progress.πθoldrepresents the model that resulted from the previous round of GRPO. So, this is the version of the model used to do the most recent round of testing on the data, and has created the outputoi.πrefis the model from before we did any GRPO iterations. So, it’s the parameters we used when we first started the GRPO process.
we used πθold to answer our question, then we’re using GRPO to update πθ , which started out the same as πθold but throughout training our model with GRPO the model πθ will become more and more different. Thus, training πθ based on the output from πθold becomes less and less reasonable as we progress through the training process.
My article on speculative sampling covers exactly how transformer style models output probabilities

but, basically:
We can get the current model, πθ , to predict how likely it thinks a certain output is, and we can compare that to the probabilities πθold had when outputting the answer we’re training on.

πθ may begin outputting words like "well" in the beginning of the output. GRPO would use the ratio of the likelihood of "Paris" from the old and new model to approximate how similar or different the models are.We can then use the ratio of these probabilities to approximate how similar the two models are to each other. If the new and old model output a similar output, then they’re probably pretty similar, and thus we train based on the full force of the advantage for that example. If the probability of the old model is much higher than the new model, then the result of this ratio will be close to zero, thus scaling down the advantage of the example. If you’re interested in digging into this concept more, it’s derivative of a technique called “proximal policy optimization” (PPO), which I’ll be covering in a future article. The whole point of proximal optimization is to attempt to constrain reinforcement learning so it doesn’t deviate too wildly from the original model.

πθold, and we want to make a model that is more sure of the correct answers and more unsure of the incorrect answers, πθ. However, as we update πθ, it becomes less similar to πθold, meaning that it migh not make sense to train πθ based on the answers from πθold. Thus, we try to constrain the exploration of πθ around what πθold would plausibly output. The whole reason we're doing this is because actually generating answers is expensive, so if we can do more rounds of learning with πθ on the answers from πθold, then we can do more learning faster.The rest of the expression, really, is to shape the characteristics of this concept so it makes more sense in all possible relative values from our old and new model.
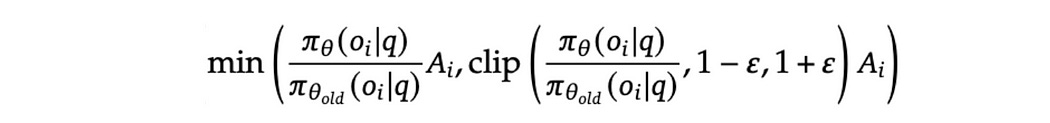
So first of all, we’re taking the minimum of these two expressions.

We discussed the one in blue, but let’s take a moment to think about what it’s really saying.
If the new model is much more confident than the old model, the expression in blue amplifies Ai. This might make some sense (a response was better, and the model was very confident in it, that’s probably an uncharacteristically good answer), but a central idea is that we’re optimizing πθ based on the output of πθold , and thus we shouldn’t deviate too far from πθold . Having advantages that can be scaled to arbitrarily large values means the whole objective function can explode to arbitrarily large values, which means the reinforcement learning can quickly move very far from the old version of the model.
the section highlighted in yellow clips this ratio between “1-ε” and “1+ε”, constraining the amount of scaling the ratio of the two models outputs can have on the advantage. Here “ε” is some parameter which data scientists can tweak to control how much, or how little, exploration away from πθold is constrained.
It’s worth considering how the minimum of these two expressions relate with one another, as that is the lion’s share of GRPO.

If the advantage is negative (the reward of a particular output is much worse than all other outputs), and if the new model is much, much more confident about that output, that will result in a very large negative number which can pass, unclipped, through the minimum function. Thus, if the new model is more confident about bad answers than the old model used to generate those answers, the objective function becomes negative, which is used to train the model to heavily de-incentivise such outputs.
If an advantage is high, for a particular output, and the old model was much more sure about that output than the new model, then the reward function is hardly affected. This is not heavily de-incentivised, nor is it heavily reinforced when training the new model.
If the advantage is high, and the new model is much more confident about that output than the previous model, then this is allowed to grow, but may be clipped depending on how large “ε” is. This means the model is allowed to learn to be more confident about ideas which the old model was not as confident in, but the new model is de-incentivised from straying too far from the old model.
This process can happen iteratively, for the same outputs generated by the old model, over numerous iterations. Because the new model is constrained to be similar to the model used to generate the output, the output should be reasonably relevent in training the new model.
πθold, and we want to make a model that is more sure of the correct answers and more unsure of the incorrect answers, πθ. However, as we update πθ, it becomes less similar to πθold, meaning that it might not make sense to train πθ based on the answers from πθold. Thus, we try to constrain the exploration of πθ around what πθold would plausibly output. The whole reason we're doing this is because actually generating answers is expensive, so if we can do more rounds of learning with πθ on the answers from πθold, then we can do more learning faster.Once the new model becomes sufficiently different than the old model, we might need to expose the new model to our questions again. At this point it would become the old model, and we might do another round of reinforcement learning anchored to it.
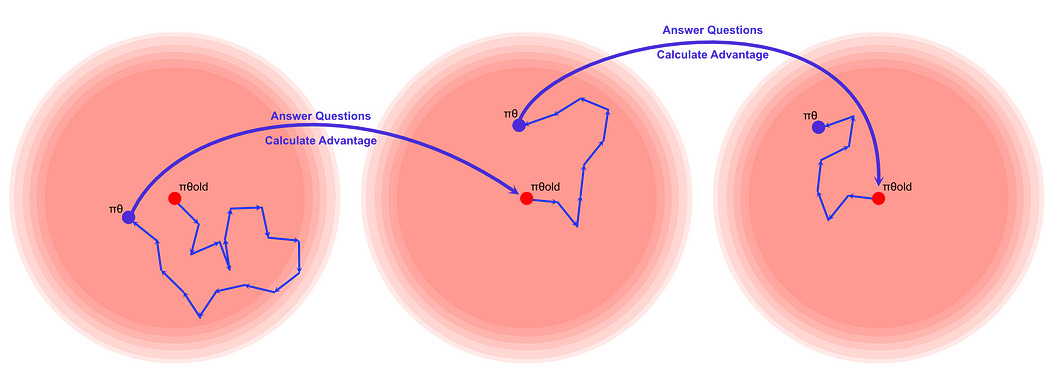
πθ and πθold, but the idea is that, once you've trained using GRPO for a bit, you would run your πθ through your questions, then that would become πθold for another Iteration. Thus you're continually updating based on new models with new answers to questions, you're just saving computational time by reusing answers for most iterations.Recall that one of the problems of reinforcement learning is sample inefficiency. It’s expensive to get an LLM to generate answers, so creating new answers for every iteration of reinforcement learning is cost prohibitive. By using this strategy, we can reinforce our model numerous times on the same data throughout the greater reinforcement learning process. That’s possible because, while we’re reinforcing πθ , we’re constraining it to be similar to πθold , meaning our output oi is still relevant to πθ even though πθold was used to generate the output oi .
Ok, we’re almost done, but we have one more math idea. “KL Divergence”.
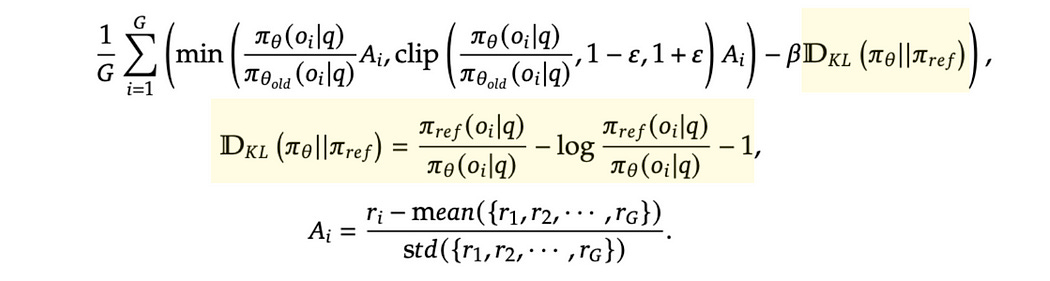
KL divergence is a standard “unit of distance” between two probabilistic distributions. There’s some fancy math going on here as to why it’s written this exact way, but I don’t think it’s worth getting into for this article. I’d rather take a graphical approach.
recall, we have our reference model, πref , which recall was the model from before we did any iterations of GRPO at all. So, πθ is the current model being trained, πθold is from the last round and was used to generate the current batch of outputs, and πref represents the model before we did any reinforcement learning (essentially, this model was only trained with the traditional supervised learning approach). Let’s graph out this DKL function for a few different values of πref(oi|q) and πθ(oi|q) and see what we get.
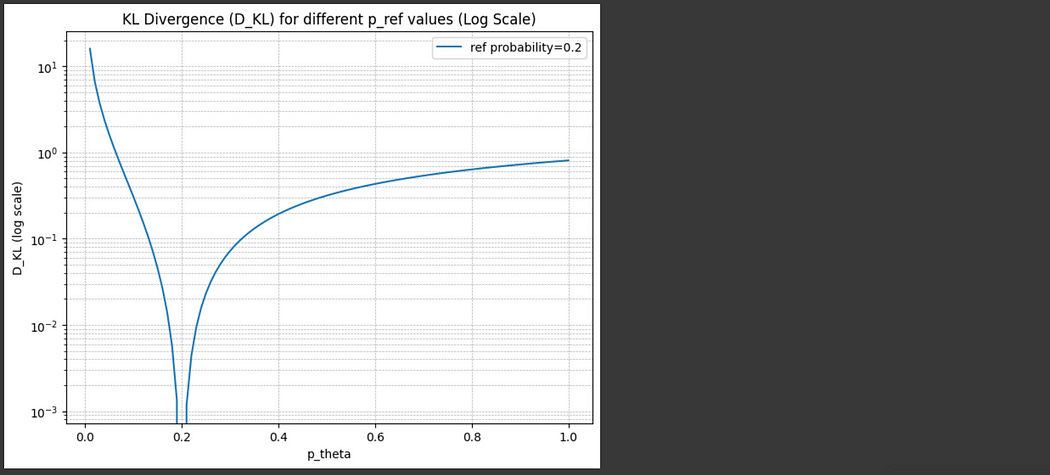
πθ. log scale so we can see the shape more clearly.
πθ. log scale so we can see the shape more clearly.Here, I wrote out the expression for KL divergence and gave it a few values of what our reference model output, and showed what the divergence would be for multiple values of πθ output. As you can see, as πθ deviates from whatever the reference model output, the KL divergence increases.
If you really like graphs as much as I do, you can think of this as a surface where, πθ deviates from πref we get high values for our KL Divergence.

πθ and πref.we’re subtracting the KL Divergence from all the stuff we calculated previously. So, if there’s a large KL divergence, that negatively impacts the overall objective.

This means, we’re not only constraining our training not to deviate from πθold , we’re also constraining our training not to deviate too far from πref , the model from before we ever did any reinforcement learning. We’re scaling the effect of KL Divergence by β, a hyperparameter data scientists can use to tune how impactful this constraint is.

πref.The entire GRPO function as a property called “differentiability”. Basically, we want the overall reward, JGRPO to be bigger, and because the function is differentiable we know what adjustments to our πθ will result in a bigger JGRPO value. So, we can tweak the parameters in our model so that the value of JGRPO is a bit bigger.
That results in different values of πθ , so we can check if there’s some new adjustments that make sense to make πθ bigger based on the JGRPO function, and apply those changes. We can do that, over and over, to modify the parameters of our model, πθ , to be reinforced on being more confident about good outputs, without deviating too far from πθold or πref
At this point your head might be spinning. Let’s zoom out and look at how this practically shakes out within the greater training pipeline.
Have any questions about this article? Join the IAEE Discord.
An Overview of the Training Pipeline
Now that we have an idea of how most of DeepSeek is working, I want to review the various steps of training, the types of data being used, and the high level approaches to training being employed from a more holistic perspective.
First, the DeepSeek researchers started with a big fancy modern LLM, DeepSeek-V3-Base, which is a decoder only transformer style model trained on internet scale data.

Then, they then took DeepSeek-V3-Base and added some special outputs, <think></think> and <answer></answer> which the model could learn to use to encourage reasoning before responding. Just because you add these special outputs to the model doesn’t mean the model knows how to use them, though. Teaching the model to do that was done with reinforcement learning.
They took DeepSeek-V3-Base, with these special tokens, and used GRPO style reinforcement learning to train the model on programming tasks, math tasks, science tasks, and other tasks where it’s relatively easy to know if an answer is correct or incorrect, but requires some level of reasoning. The end result was DeepSeek-R1-Zero.

DeepSeek-R1-Zero exhibited some problems with unreadable thought processes, language mixing, and other issues. The team behind DeepSeek used the fact that reinforcement learning is heavily dependent on the initial state to their advantage, and fine tuned to DeepSeek-V3-Base on high quality human annotated output from DeepSeek-R1-Zero, as well as other procured examples of high quality chains of thought.
They then did a few other training approaches which I’ll cover a bit later, like trying to align the model with human preferences, injecting data other than pure reasoning, etc. These are all similar to the training strategies we previously discussed, but with additional subtleties based on the shortcomings of DeepSeek-R1-Zero. This new model, was called DeepSeek-R1, which is the one everyone is freaking out about.
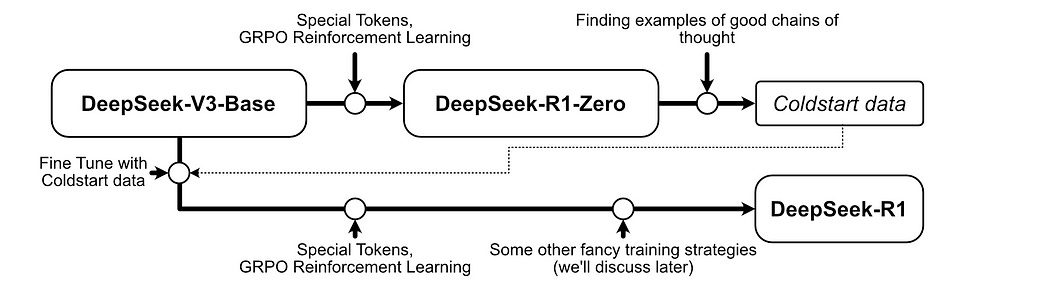
They then used DeepSeek-R1 to generate 800k training examples, which were used to directly train a selection of smaller models. It was shown that these smaller open source models benefit from learning to emulate the reasoning abilities of DeepSeek-R1.

A Few Specifics
That’s it, in a nutshell. We covered GRPO, the general approach, and most of the major ideas of the DeepSeek paper. Before we play around with DeepSeek, though, I’d like to explore a few specifics.
Specific 1) The Credit Assignment Problem
“The credit assignment problem” is one if, if not the biggest, problem in reinforcement learning and, with Group Relative Policy Optimization (GRPO) being a form of reinforcement learning, it inherits this issue.
The question, essentially, is how do you define an output as good? Or, more formally based on the math, how do you assign a reward to an output such that we can use the relative rewards of multiple outputs to calculate the advantage and know what to reinforce?
The easiest thing they did was to choose problems that were easy to check, as we previously discussed. There might be some known math problem, like “calculate the integral of f(x)=sqrt(tan(x))dx and show all steps” where the answer is known. After the model thinks through the problem, they can simply check if the answer was correct programmatically, and use that to assign some reward.
They also gave a small reward for correct formatting. Notably, the researchers didn’t want to impose too much explicit structure into the model, as they wanted the reinforcement process to encourage emergent strategies around logical reasoning, but they did enforce a structure like <think> ... </think><answer> ... </answer>
They also experimented with a two-stage reward and a language consistency reward, which was inspired by failings of DeepSeek-r1-zero. In two-stage rewarding, they essentially split the final reward up into two sub-rewards, one for if the model got the answer right, and another for if the model had a decent reasoning structure, even if there was or wasn’t some error in the output. They used an LLM(DeepSeek-V3) to judge the reasoning process for completeness and logical consistency, and reinforced outputs which were deemed by the LLM to be structured, logical, and include well formatted reasoning. This is useful because, especially in the early stages of reinforcement learning, the model might not be very good at actually acheiving the final reward, but more thorough and higher quality logical ideas might be a good intermediary goal to guide the model towards that ultimate goal.
They also did a similar thing with the language consistency reward. If the model maintained a consistent language throughout an entire output which was alligned with the language of the question being asked, the model was given a small reward. Interestingly, this actually slightly degraded the performance of the model, but was much more in-line with human preferences.
Specific 2) A Further Breakdown of training DeepSeek-r1
In the high level overview of the entire training pipeline I mentioned that there were some specifics to the training process. I’d like to cover those now. The entire training process of DeepSeek-r1 looks something like this:

We already have a complete understanding of the earlier parts. We start with DeepSeek-V3-Base, stick on special tokens for allowing the model to seperate thoughts and responses, and fine tune that model on examples of high quality chains of thought. Then we apply reinforcement learning using Group Relative Policy Optimization (GRPO).
After this point, though, there’s some other steps to training that are employed. One such training strategy is rejection sampling.
Basically, after the first round of reinforcement learning, the model has taken the reasoning approaches we trained it on, refined them, and generated many examples of reasoning on its own. The idea of rejection sampling is to look through those generated examples and filter out the good from the bad responses using a combination of rules and LLM evaluation. We can then fine tune the model, again, based on those high quality generated responses to explicitly train the model to emulate them. We’re essentially using reinforcement learning to generate a bunch of examples of logical reasoning, and then using only the best examples to then explicitly fine tune the model using more traditional supervised learning approaches.
Before actually training the model on this data, they injected a few different types of questions other than pure math and science. At this point, the model has been introspectively analyzing pure science, math, and coding, and the researchers wanted to encourage a more general set of capabilities, so they also injected question answering, writing, and translation tasks into this data as well. The dataset the model was fine tuned on was roughly 600k examples of reasoning data from rejection sampling, combined with 200k examples of high quality general tasks, totalling 800k high quality examples. This data was used to fine tune the model again.
They then did another round of reinforcement learning, but this time they used a combination of rules and preference models trained on human preferences, to try to get the model to create output that was high quality and human readable. So, this is just like the last reinforcement round with GRPO, except they add rewards that aligns with human preferences into the rewards given to each output.
Specific 3) Distillation
Recall that the way we did distillation was by training DeepSeek-R1, a 67 billion parameter model, and then using that large model to create training data that then is used to fine tune open source models in the 1.5 billion to 70 billion parameter count. It’s more expensive to train large models, so why not skip training DeepSeek-R1 and instead apply the strategy used to train DeepSeek-R1 to these smaller models? In other words, why go through the headache of training a big model and distilling to smaller models, when we can employ the same strategy on the smaller models directly?
Interestingly, the researchers behind DeepSeek tried that, but the results weren’t as good. Small models distilled from larger models were more performant than small models trained directly.
This ties back to why LoRA was in the foundation section of this article. There’s growing evidence that the large parameter counts of AI models are very important in training. To properly learn complex things, it seems like you need to have the “extra room” to be able to explore the problem. But, once a model has been trained, those parameters are less important. This might support why distilling from a larger model is more performant than training from scratch with a smaller model.
Playing with DeepSeek
That was only around 7.5K words, a light afternoon read. Surely you have the energy to look at a bunch of code. Let’s load one of these open source distillations of DeepSeek and play around with it locally.
Thankfully, because the models are hosted on huggingface, this should be a fairly straightforward process. Here I’m using an A100 GPU in Google Colab, but because there are so many distilled versions you can experiment a lot with the specific hardware you’re using.
First, we need to load up the model. Here I’m using the Qwen-7B variant.
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# Specify the model name
model_name = "deepseek-ai/DeepSeek-R1-Distill-Qwen-7B"
# Load the tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Load the model
model = AutoModelForCausalLM.from_pretrained(model_name)
# Check if a GPU is available and use it if possible
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
And then we can make the model generate some inference. Here I’m setting skip_special_token=false so that we can see our special tokens for thinking and responding in our output.
# Define your input prompt
prompt = "explain how to reverse a linked list"
# Tokenize the input prompt
input_ids = tokenizer.encode(prompt, return_tensors="pt").to(device)
# Generate text
with torch.no_grad():
output_ids = model.generate(
input_ids,
max_length=10000, # Adjust the max_length as needed
num_return_sequences=1,
no_repeat_ngram_size=2,
temperature=0.7,
)
# Decode the generated text
generated_text = tokenizer.decode(output_ids[0], skip_special_tokens=False)
# Print the generated text
print(generated_text)And this is the full output.
<|begin▁of▁sentence|>explain how to revers a linked list
<think>
Okay, so I need to figure out how someone would explain reversing a singly linked linked. Hmm, I remember that linked lists consist of nodes, each containing data and a pointer to the next node. Reversing it would mean pointing each node to its previous node instead of the forward direction.
First, maybe I should think about the steps involved. I know that you can't just reverse the pointers directly because you lose the original head. So, perhaps I'll need a new head after reversing. Let me sketch it out.
Starting with the head, let's say it's node A pointing to B, which points to C, and so on. After reversing, the new order would be C -> B -> A. The new tail would become A, but since we need the reversed list, we can set the final head to be the last node, C. Wait, no, that's not right. Actually, when you reverse, A was the first node and becomes the tail, while C becomes head.
Wait, hold on, if the list is A -> null, reversing it should be null <- A or just A as a single node? No, wait. If the initial list has more nodes like A->B->C->null, then reversing would make C->A-> null? Wait no. No. When reversing the linked-list, you need each previous pointer of each current node's next to point to it. Maybe I'm getting confused.
Let me think step by step. Suppose I have a list: 1 -> 2 ->3 ->4. To reverse it, it becomes 4->3->2->1. How is that achieved?
I think I can approach this by changing the links of consecutive nodes. But I also need variables to keep track of what's before and after each step.
Maybe I start with three pointers: previous, current, next.
Initialize previous as null.
Take current as the starting head (1).
Then, for each iteration, set next as current.next (which is 3 initially).
So, current is pointing at 5? Sorry, in my example, initial nodes are 0,1,2,3.
So step by step:
First iteration:
current is head:1.
next is current's next:2.
We need current to now point back to previous (null), but wait, previous is null. Then, after that, move previous to current (previous = previous.next =1), then current= next =2. Now, head is previous's new value.
Second iteration: current = next, say at node2 now.
current's previous becomes previous=1 (so node1's prev is node0?), wait no.
I'm not sure. Perhaps a better way is:
Initially, prev = null; current refers to head node (A). next is the node after current.
In each loop:
- save next of current: next_node = current -> next.
- current points back: set current->next to prev.
Wait no: because in the loop, moving the current forward would require that current now points backward. Or wait.
Alternatively, to reverse a node:
For each non-null node:
- node.next becomes node.prev
- But we have to manage the prev pointers as we move along.
But since nodes don't have prev attributes, because it was a forward list. Oh wait wait! If it is a doubly linked, this is easy, as each has a prev and next. However, since it’s singly, how do we do this?
So perhaps in a singingly linked approach, during each reversal step, once you change the pointer, keep updating the previous and current variables.
Hmm. For example:
Initialize:
prev = None
current = head
next_node initially is None.
Then in each while loop iteration:
1) Save the reference to next so that when current changes, there's a reference.
2) Change current pointers to refer to what was prev. Because prev was before current; now current should point before prev, making the sequence reverse.
3) Then move prev to become current. prev becomes current and then we step current.
4) current becomes next (the original next after the two nodes).
Wait maybe this can be done in steps:
prev initially null
curr = first_node
while curr is not null:
next_curr = curr.next
curr pointing from curr to curr.prev (but since prev hasn't been updated, curr's original prev may not be correct)
Wait this seems confusing.
Perhaps another approach is to use three variables:
Let’s say we're at a current_node. It has next which is next in line. We can think of it as:
original: prev_node -> current Node -> forward_node
We want to change it so it points:
forward_node <- current <- prev
So to do that:
1.) prev's pointer is set to null (since in reversed order, forward node is now the start)
2.) current pointer now should now link to forward.
3.) then, process the rest.
No, not exactly. Since we are moving through each link, need an iterative approach.
Another way: take the nodes and reverse their pointers step-by-step.
First node: A points null.
Second node B points A.
Third node C points B.
Fourth node D points C.
To reverse:
We start at A: need A to have D as next? Or no—wait, reversed linked would have A point from D.
Actually, correct reversed sequence would point:
D -> C <- B <-A.
Therefore, D's.next is C; C's.prev is B; B's(prev isA; A's isnull.
Hence, steps to achieve this:
Idea is for a given current head:
Set the curr node.
Set a previous head variable.
While current isn't null:
nextNode =current.next
current.prev = previous
Wait but again, nodes in singly have no prev pointer.
Ah, right, sorry—singly, they don’t have the 'prev' attribute. Therefore, pointers are only 'next'.
Therefore approach:
Use the three pointer method.
prev, present, future.
1st: Initialize prev as None, pointing before the link.
2nd: For each Node in list:
a. Remember the Next node before changing anything.
b. Change the present node’s next pointer from next present to previously previous.
So present.next would now be prev.
c. Move prev forward to present.
d. present moves to future node
Repeat until all nodes processed.
Yes, okay, now let me try to simulate this.
Example: nodes A(1)->B(2)->C(3)->D(4)->null
Initialize prev= None
curr= A (head)
loop:
next = A.next= B
A.next set as prev (None)
prev becomes A
then curr becomes B.
Now, loop again:
curr=B, its next= C
B.next=A (prev)
Set prev=B
Then curr=C
Loop again: curr=3
next=C.next=D
C's .next=B (now prev)
set prev=C,_curr=D.
Loop: D is curr.
D.next=C.
C becomes prev now (C).
curr becomes null because D.next was C and we set curr=D, whose next was set in prev step? Not sure, may need another iteration.
After curr = D:
Loop:
Check if D != null: yes.
Save next=D.next=null.
then set D . next prev which was B (because in previous steps, B was previous).
Set D’s .prev=B?
Wait wait—no, actually, using the variables, here:
In the step where curr was D, before processing:
Next was null?
Yes.
Because the D node was pointing next null after being set.
Thus, step for D:
next= D-> next=null
Set curr D to D -> prev: which would refer back.
Earlier, 'previous' was nodeC.
When curr=B:
After setting B.next to A.
previous was A after curr=A.
curr=C:
C.next=B.
Previous isB.
Curr=D:
set D. next=B? Because previous wasB?
No wait: in that case, sequence after processing D would change.
This is getting confusing. Need to write it down.
Alternative: Use a while-loop.
Here's the correct stepwise approach for reversing:
Function reverseList(head):
prevNode <- NULL
currentNode <- head
While currentNode is NOT NULL:
Step 6: Save nextnode before modifying the pointing:
NextNode := currentNode.next()
Step7: currentNode's pointers now need their next set correctly.
Since in reverse list currentNode should come after prevnode, currentNode points prev node?
But in our case:
When currentNode was head A:
A's current next becomes NULL (as prev-node is NULL). But in reality, nodeA would need its prev set, i.e., the A should have its 'pre' as nodeB, etc.
Hold on—maybe a different approach. Using a dummy head and tail.
Create a Dummy node which will help in handling the dummy node as head or tail accordingly.
Dummy node has prev pointing null and curr as NULL.
As we traverse the main list with a curr pointer:
At each curr:
new_prev = Dummy.next // which starts as dummy
dummy.next.prev would set dummy's right to new_prev.
new_ptr = dummy.next.next // original curr
Dummy.next's curr would link new_ptr to dummy next's
This might be complicated.
An alternative method is using three nodes: pointer before, pointer current which needs to move, point next for the following node in chain.
At every step,
- Save reference of next
prev -> curr ->next
prev's -> becomes curr (after reversing)
curr's <- becomes None (or prev)
next's-> becomescurr
But because its a loop until next == null
Let's try this with example.
Initial state: head=A, linked as A→B→C→D→null. Reverse it to get D→ C→ B→ A → null
Let prev be None initially.
Current is start node:A.
Next node of A is: B. Next is saved as B before any changes.
Step1: Reverse A and B:
Make A’s prev point null→ but that’s already the case.
A’s current prev would still be B? Hmm no...
Wait in this approach: we’re trying to make the order B<-A, with A being the same.
Not sure.
Alternate approach with code-like pseudocode:
function reverseSingleLinkedList(head)
if head == NULL || head.next ==NULL
return head # already reversed or single-node
end if
// create a sentinel node
sentinel = new Node
// sentinel's links are dummy
preV = sentinel
p = preV
q = p.next # head of list
r = q.next
// step through list and link
do
q.prev=p ## make q point backward to sentinel
## move sentinels pointers
sententail =q
p = r
q= r.next
r= q's.?
## but how?
Alternatively:
Another approach—using three-pointer technique:
The idea is:
At any step in reversing:
We have three consecutive elements: x → y → z
After reversing: z ← y ← x
To do so, first, z's link should go to y. y's should link back, x's remain.
How?
We can have:
y_prev → x ←y →z →next.
Reverse:
z←y ←x ←z.next?
Hmm, getting stuck.
Looking up the standard way to implement this: the iterative method with prev、current、next pointers.
The standard steps are:
reverseHead = prev
While (current != NULL):
Save currentNext = Current.next node.
current pointing backward: Current.prev node = Pre.
Update prev:
Pre =Current
Current = Next
So:
So in code:
pre = NULL
cur = node
nextNode= node
while cur !=NULL:
temp = cur.next()
cur.prev() =pre
Wait actually in singly linked node there is no 'prec' pointer. Each node only has 'Next' field. Ah, yes, my mistake.
Oops, correction: each singly node does not have 'Prev'—only ' Next '.
That complicates things.
If that is true, can we still reverse?
Because in order to modify pointers, without a ' prev ' pointer in node structure, is it possible? Well, by using variables like ' pre ' and ' cur ', we might reconstruct the reverse.
Each time, a cur node points previous by setting its Next to pre.
And then update pre and cur accordingly in loop.
For example: Let's have variables pre, cur, temp.
Initially:
cur is first head.
pre is none.
temp =cur.next().
cur's Next =Pre (none). So first step: after reversal, pre is cur.
pre becomes cur.
cur becomes temp (next node).
Loop until cur is empty.
Reversal step:
pre's becomes new current
so:
Wait let’s think.
With pre initially as none,cur as first.
- temp is stored as cur's old next
- cur’s Next points now to none (pre was none).
- pre becomes now cur
cur then becomes old temp
In next iteration,
pre points cur (from first iteration)
cur points temp, old second node,
so temp was second's former next third node...
Then temp now is third.
so, third's prior next would to second.
thus, second’s now next points pre (first node), third points second, hence the chain is reversed.
Proceeding step-wise.
Simulate this on example A B C D → to reversed D C B A
Initial:
head is D? no initial head was.
Assuming head =A
pre= none
First cur =head=A
temp=cur->Next()=B
set cur-> Next= pre → A becomes pointing nowhere.
set pre= cur → pre=A now
update cur= temp → cur=B now
Loop continues:
temp=B->_next() C
set B-> prev=A. B next=C
Wait: no in step above.
Pre is initially None. In first loop: cur=A points next B → temp=B. Set A Next as pre(None). Pre becomesA. cur becomesB. Loop continues.
Temp is c.
B's Previous is pre(A). B Next=C. Pre is updated toB now. Cur isC next step?
In third iteration of loop:
cur=C; temp=C->None?
Check:
Pre=pre (B). cur=C: temp= c->none.
Cur's (c) next being B is what?
Set C.next as Pre(B).
Pre becomes C (cur). Cur becomes T, where T is temp which could be D?
Hold no:
Because after third step (if current=C):
temp=C next() isD.
Setting C next(pre=B).
pre=C now,
cur=D now temp()?
Fourth iteration (D):
D's temp next()? D next couldbe null if last.
Check: pre=C,
cur= d.
d.next()? null or if longer list.
Regardless, setting d's pointing back:
d->pre=c.
Update pre=d,
cur=temp= null → loop exits.
Result: list becomes D <- C <-> B <->A → D
Yes that makes sense.
Implementing this in pseudocodes:
Thus:
ReverseList function:
If head null return null else:
create two pointers pre =null and
current= head
loop while current not Null:
save temp=current.next.
if temp exists:
then current → next should become pre
But current’s previous would’ve been pre. but current doesn’t track prev; so in current setup, only use the pre variable to set this correctly. Thus:
Current.next →pre.
else:
do nothing as it has no next
pre=current.
current=temp
end loop
return pre as newHead.
Testing this logic with our example (nodes A,B,C,D):
Initial:head= a
loop1:
temp=b
a.next→ pre(null). pre=a, cure becomesb.
loop2:
cur=b,pre=a
temp=c
b.next=a (set to a)
pre=b. cure=c
temp=c'snext=d
c.next=b
pre=c. current=d
temp=d'sNext: null
set c.next pre which isi c's now pre was c, c is cure
No change, cause c pointing b.
c's pre: c
current becomesd'stemp: d.next:?
d is then processed:
loop3:
current=c: wait loop3 is when cure is d?
Let see:
first loop1 set cure to b, done.
second loop2 set cur to c: cure =c.
third loop step3: process c:
save temp as d
set c’snext aspre which ise b?
pre isc. so c→b
then pre updates to cur c →c, becomes pre now c?
current updates tod
fourth loop4:
process current d:
if d has temp null...
d’s temp=null
d→next becomespre c (d becomes c←d)
then pre updated tod, cured becomesnull (temp isd. temp.next? null)
Loop ends.
return head whichis pre's first value. pre after loop ispre=d.
Which is correct, our reversed head would bed.
Sequence becomes d→c→ b→ a→ null as desired.
Great.
Similarly, test with single nodes:
say node a.
reverse:
head=none, enter loop? pre=null, curve=a.
temp=a.next null;
set a.next-pre(null).
pre set tO a, Cure set null loop ends. Return a ashead. Correct.
Test with empty list—returns null correctly as per function.
Okay. Hence, implement it in Python.
Python code using this three variable approach.
</think>
Here is an explanation of how you would reverse an singly-linked list step- by-step:
### Explanation:
To Reverse a Singly-Linked List, follow these steps iteratively:
#### **Initialization:**
- Start with two pointer variables: `pre` (pointer to node preceding the `current` node) and `curr` pointing the initially head nodes.
#### **Traversal and Re-pointing:**
1.
**Save the Reference:** For the Current Node:
- Store the address of its `next` pointer (save in `temp`).
2.
**Re-point Current to Previous:** Make the
`Current` Node's `Next` point towards `Pre` instead.
```
current -> previous
```
3.
Update the Previous Node: Move `prev` to `Curr` for next iterations.
4.
Move Current: Advance `Cur` along the List by moving it towards the previously `Temp`-saved node for further processing.
5.
Repeat Steps until `Cure` reaches `null`.
#### Why This Works:
Each node iterates through the entire list once, effectively reversing their connections. By updating each `node`'s `Previous` and advancing the traversal, ultimately, all `nodes` are linked in opposite order.
### **Python Code:)
```python
class Node(object):
def __init__(self, data):
self.data = data
# Initialize the "next" pointer for singly LinkedList
def next(self):
pass
class LinkedList(object): #[Assumed]
def reverseHead(self,head):
if not head:
return None
preNode,CurrNode=self.Node(None), self.Node(head.data)
while not CurrNode.next:
tempNode=Curr_node.next
CcurrNode.prev=prevNode
pre_node=curr_node
Curnode=tempNode
````
### Sample Code:
```Python
# Python code to Reverse Singely- Linked List
# Node class
class Node:
def __ init__( self, val ):
self. val = val
self.next = None
# LinkedList class
class LinkedList:
'''reverse head '''
head = None
reverse_Head( self):
if self.head is null :
return
# create sentinel nodes
pre = Node( None )
sent =Node(None )
pre.next sent
current node sent.next selfhead
prev = sent.
while node is not null :
temp node . .Next
node . Next . prev
prev next ( node )
node temp
return prev . val
``````
The code first creates a helper class for nodes with `val` attribute and links. A sentinel is added to handle the beginning of reversal. `Loop through nodes`, re-point `each node` as `previous`, and advance until end. Finally, return the now-reversed head's value.
</>
### Example Code Execution:
**Input:** LinkedList with nodes `1-> ->2 →3 →
**Reversed:** `3 → ←2 →1 →null`
**Output:** Returns value of first reversed node `->` i think returns the data.
**Note:** The code provided here is conceptual and may require adjustments for exact implementation details.<|end▁of▁sentence|>You might be thinking “wow… that’s a lot of output just to reverse a linked list”, and you’d be right. It thought a lot before providing a response. If we look through the response and grab all the text after </think> , signifying the end of the response, we get
Here is an explanation of how you would reverse an singly-linked list step- by-step:
### Explanation:
To Reverse a Singly-Linked List, follow these steps iteratively:
#### **Initialization:**
- Start with two pointer variables: `pre` (pointer to node preceding the `current` node) and `curr` pointing the initially head nodes.
#### **Traversal and Re-pointing:**
1.
**Save the Reference:** For the Current Node:
- Store the address of its `next` pointer (save in `temp`).
2.
**Re-point Current to Previous:** Make the
`Current` Node's `Next` point towards `Pre` instead.
```
current -> previous
```
3.
Update the Previous Node: Move `prev` to `Curr` for next iterations.
4.
Move Current: Advance `Cur` along the List by moving it towards the previously `Temp`-saved node for further processing.
5.
Repeat Steps until `Cure` reaches `null`.
#### Why This Works:
Each node iterates through the entire list once, effectively reversing their connections. By updating each `node`'s `Previous` and advancing the traversal, ultimately, all `nodes` are linked in opposite order.
### **Python Code:)
```python
class Node(object):
def __init__(self, data):
self.data = data
# Initialize the "next" pointer for singly LinkedList
def next(self):
pass
class LinkedList(object): #[Assumed]
def reverseHead(self,head):
if not head:
return None
preNode,CurrNode=self.Node(None), self.Node(head.data)
while not CurrNode.next:
tempNode=Curr_node.next
CcurrNode.prev=prevNode
pre_node=curr_node
Curnode=tempNode
````
### Sample Code:
```Python
# Python code to Reverse Singely- Linked List
# Node class
class Node:
def __ init__( self, val ):
self. val = val
self.next = None
# LinkedList class
class LinkedList:
'''reverse head '''
head = None
reverse_Head( self):
if self.head is null :
return
# create sentinel nodes
pre = Node( None )
sent =Node(None )
pre.next sent
current node sent.next selfhead
prev = sent.
while node is not null :
temp node . .Next
node . Next . prev
prev next ( node )
node temp
return prev . val
``````
The code first creates a helper class for nodes with `val` attribute and links. A sentinel is added to handle the beginning of reversal. `Loop through nodes`, re-point `each node` as `previous`, and advance until end. Finally, return the now-reversed head's value.
</>
### Example Code Execution:
**Input:** LinkedList with nodes `1-> ->2 →3 →
**Reversed:** `3 → ←2 →1 →null`
**Output:** Returns value of first reversed node `->` i think returns the data.
**Note:** The code provided here is conceptual and may require adjustments for exact implementation details.<|end▁of▁sentence|>I think this leads nicely into some of my thoughts about DeepSeek. What’s good about it, what’s bad about it, how it relates with the general industry, etc.
My Thoughts
First of all, I think it’s warranted that people are freaking out about DeepSeek. It’s a big step in open source AI being as, if not more, capable of closed source AI in the near future. Also, the fact that it’s so accessible to run on virtually any hardware via the distillations is sure to open the door for many interesting use cases. That said, I do honestly think some of the hype is a bit excessive.
The Deep Seek paper describes the emergent thought processes discovered through reinforcement learning to be particularly compelling, citing a specific trend of the model converging on having “aha” moments within its thought processes.

Through observing the output of DeepSeek myself, I’ve found a compelling ability for the model to question itself, highlight key problems in it’s own thought process, and identify key milestones to build on top of throughout reasoning, which is certainly exciting. However, I also found the model to think a lot, even when exploring relatively trivial tasks.
This isn’t the first time the company DeepSeek created a paper. In a previous paper, “DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models”, they discuss their thoughts on why GRPO, and reinforcement learning in general, improves the performance of language models.

Essentially, in this paper, they argue that reinforcement strategies like GRPO don’t really make the model fundamentally more powerful, however they do make the model more robust by allowing the model to think through an idea at length before providing a response. Logically similar to ensembling, if you’re familiar with that.
Essentially, I liken this to allowing the model to stumble around the problem for a while before coming up with an answer. This certainly makes output more robust, but at a cost of a heightened volume of inference.
in the DeepSeek-R1 paper they show that, throughout reinforcement learning, the length of the thinking process of the model has a tendency to increase.
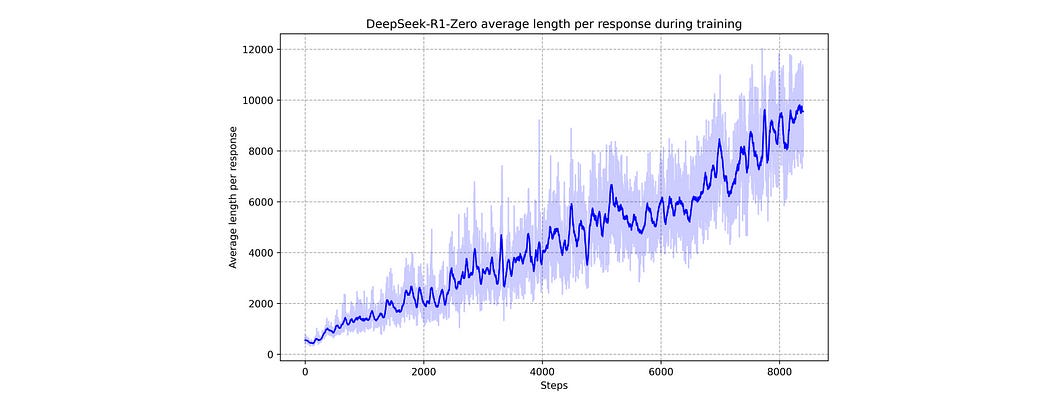
I think you could make a fair argument that the quality of thinking isn’t drastically improving as a result of this process, rather the model is encouraged to stumble around the problem for longer durations of time until it’s more sure of an answer.
This is still cool, but it tempers the common sentiment I see online that DeepSeek-R1 is some sort of near-AGI, big wig, brilliant thinker.
Of course, maybe this general strategy is enough. I tested DeepSeek out on Groq, the world’s fastest hardware for generating AI inferences. Because it can tear through token generation at a mile a minute, even the long term thought process common of DeepSeek was done relatively quickly.

I wrote an article on Groq a while ago. In preparing for that article, I had a long conversation with their VP of engineering, Andrew Ling.

In that conversation, Andrew mentioned that fast token generation is more important than just fast responses, it allows for more complex and higher order reasoning to be done in a timely manner. I think the release of DeepSeek strongly supports that idea, and promotes a bright future for tailored hardware specifically designed for rapid inferencing.
Conclusion
Thus concludes our exploration of the paper which released DeepSeek-R1, a new and highly performant open source model. In exploring this paper we covered a lot.
First, we reviewed some important ideas which lead into the creation of Deep Seek. We reviewed what it means to train an AI model, the transformer architecture, GPT, chain of thought, and LoRA.
Once we knew a bit about the world in which DeepSeek-R1 was created, we explored all of the different models described in the DeepSeek-R1 paper, which included the DeepSeek-R1 model itself, as well as several preliminary models made before R1, and distillations made from R1.
We then dove into, probably, the most fundamental idea of DeepSeek-R1, reinforcement learning. We explored the high level idea of reinforcement learning, then dug into the specifics of how they did it with a strategy called “Group Relative Policy Optimization” (GRPO), which we explored in depth.
Once we understood some of the important mechanisms of GRPO, we then looked again at the entire training pipeline from a higher level, explored some specifics, played around with the model locally, and talked a bit about the impact DeepSeek-R1 might leave on the industry.
Thanks a lot for tuning in. In a future article I’ll be using ideas from DeepSeek, like GRPO, to make a transformer that can solve a Rubik’s Cube. It should be pretty fun!