
Claude’s Computer Use — Intuitively and Exhaustively Explained
How Anthropic made AI that can control your computer


Yesterday (at the time of writing), Anthropic released a demo of their new computer use functionality. Now Claude, Anthropic’s flagship LLM, can be used to perform actions on your computer.
I sent a quick email to my subscribers about how this worked, but I’d like to take some time to dive more in depth. In that pursuit, we’ll be covering the following:
Why this is important
A breakdown of the demo
How Claude’s computer interaction (probably) works, explained in two parts: Agents and Multimodal Interaction.
Who is this useful for? Anyone who’s interested in understanding new and exciting AI powered tools.
How advanced is this post? This article contains beginner accessible descriptions of advanced and relevant AI concepts.
Pre-requisites: None.
Disclaimer: During the time of writing I am not affiliated with Anthropic in any way. All opinions are my own and are unsponsored.
What’s The Big Deal?
The internet is blowing up over this demo:
And I get why. I think this demo strikes two major chords in the greater AI industry:
Anthropic has been duking it out against OpenAI for a while now. To see such a mature and novel demo come out of Anthropic feels like a continuation of a much anticipated shift in the balance of AI power.
AI has been cooling off in hype over the last few months. We’ve come down from the high of AGI being right around the corner, and the public is seeing the reality of AI innovation for what it really is: amazing but imperfect. Chat apps and image generation are cool, but people want more robust tools. This seems like a step in that direction.
The promise of this demo is a system that can do complex operations automatically on your computer based on your natural language prompt.
“Please move all these files from here to here”
“Can you modify this component to work within my React project, and show me the result?”
“I don’t really understand Blender, but I want to modify my scene to have a better lighting setup”
“Can you make a split column layout in my MS Word document?”
Instead of spending a bunch of time summarizing what you’re working on in a prompt so the language model can understand what’s going on, it can jump right in your actual computer and make changes within your system.
So, the promise is cool. Let's take a closer look at the demo, then talk about some of the technologies that might be ticking away under the covers to make this whole song and dance happen.
The Demo
First of all, 12 seconds in, we see this:

Using a controlled environment for these types of demos is common, and I like the fact that they made this clear and explicit. There is a massive difference between making a fully realized product and making a demo. Products take time and significant investment, and consequently it’s a good idea to roll them out slowly with a lot of feedback. What we’re looking at is the start of realizing a vision.
At this stage, it is still experimental — at times cumbersome and error-prone. We’re releasing computer use early for feedback from developers, and expect the capability to improve rapidly over time. — Source
In the demo itself, the goal is to make a fun 90s theme website, something like this:
It’s important to note that this website is created with a single HTML page, and is much simpler than most modern websites. The fact that this project exists on a single page, I imagine, makes it much easier for an LLM to understand and work within the project.
To kick this project off, we ask the Claude on our computer to navigate to claude.ai and ask Claude in the browser to create our website.

This is absurd if you don’t have some practical experience with AI. We’re using an AI model controlling our computer to open up an AI model in our browser, then we’re asking the AI model to ask the other AI model to make our website for us.
We’ll dig into this more later, but the AI model running on the computer is likely abstracted into something called an “agent”. In essence, the Claude controlling our computer is responsible for a lot of things, and it makes sense to open up a different instance of Claude to handle the simple and atomic task of “make me a 90s themed website with HTML”. You could probably ask the Claude on your computer to just make the website itself, but there is some method to the madness in using an instance of Claude which can focus on the task at hand without distraction.
The website actually gets created via the following steps:
Claude first constructs a plan
Claude takes a screenshot of the desktop
Claude finds Chrome, moves the cursor to it, then clicks on it.

Now that Chrome is open it then moves the cursor to the search bar, clicks the search bar, then searches for claude.ai.
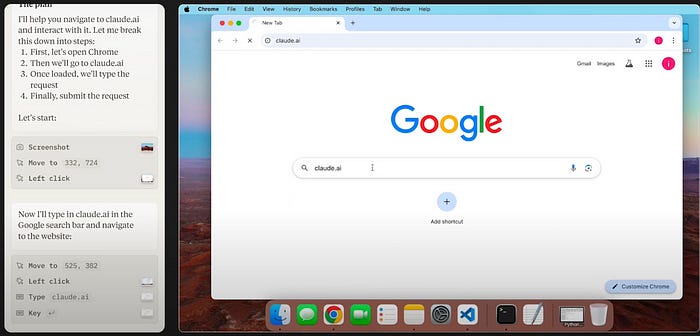
Etc. You get the idea. The Claude running on the computer ultimately asks the Claude running in the browser to make our website for us.
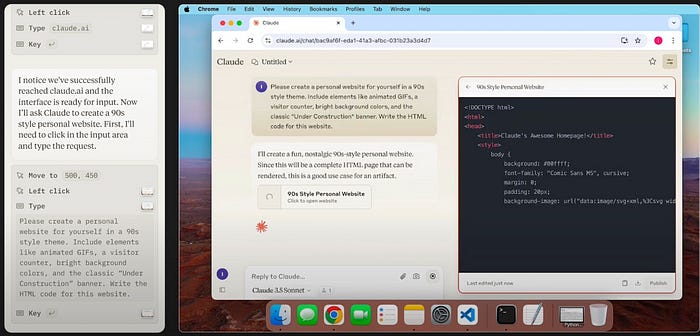
After this HTML is generated, and thus the first task is concluded, the user then asks Claude to open that code up in VS Code and run it locally on their own computer. After Claude downloads the code and opens it up in VS Code, the user asks Claude to run the website in the terminal, which it attempts to do before encountering an error: A fairly common one, the command python does not work on this computer. Claude sees this error and tries python3 instead, and the website is successfully served.
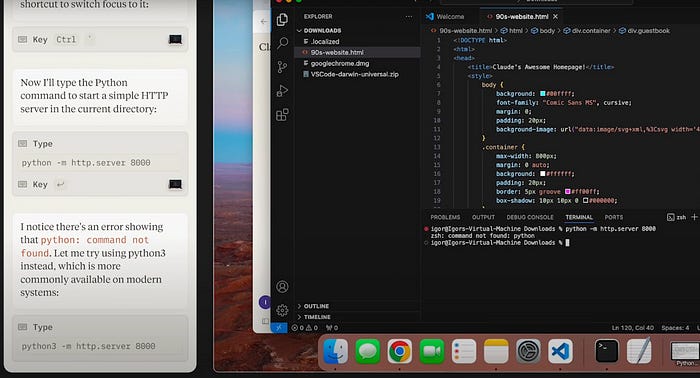
The demo explores a few more examples of overcoming obstacles and executing actions which require a general understanding of the operating system, which is pretty neat.
Let’s talk about what’s going on to make this work. There’s two key concepts in how Claude works which we’ll explore separately: Agents and Multimodality.
How It Works — Agents
The most fundamental concept within Claud’s computer use system is an “Agent”. The general idea of an agent is to allow a language model to break a task up into steps, then execute those steps over time. This is typically done by wrapping an LLM within some pre-defined logical structure and then using prompting techniques to guide the LLM into following that structure.
For instance, it seems like Claude is using something similar to a ReAct style of agent. The ReAct Agent framework, which I cover in depth in my article on agents, is designed to guide a model to first reason about what it should do, then make actions based on that plan, then observe the results of those actions. It does this in a loop until it comes up with the final output.

It seems like the folks at Anthropic created an application that can do things like navigate the cursor to a certain part of the screen, click things, and take screenshots, then defined those as explicit tools which the LLM can call within a ReAct style agent.
If we take a look at the video again, though, we notice something a bit strange.
After the command python -m http.server 8000 was called, the model creates an observation that an error was found. It’s not exactly obvious how the model was made aware of that error. Unless they’re using magic, I suspect one of two things:
The application running the agent uses screenshots as feedback after actions are performed and provides information about those screenshots to the language model, without bothering to clutter up the UI with that information.
Perhaps the application running Claude has the ability to not only see screenshots, but can also observe data from some applications.
The first option is the more likely one, in my opinion, based on these quotes:
Instead of making specific tools to help Claude complete individual tasks, we’re teaching it general computer skills — allowing it to use a wide range of standard tools and software programs designed for people. — Source
On OSWorld, which evaluates AI models’ ability to use computers like people do, Claude 3.5 Sonnet scored 14.9% in the screenshot-only category — Source
ReAct style agentic systems can have limitations that are surprising. An LLM might understand certain tools implicitly via a textual description, allowing for simple integration. A tool for clicking might be described as “If you want to click something on the screen, tell me, and I’ll click it for you”. Other tools, like scrolling, might not be so clear. “If you tell me to scroll down, I will scroll by some amount on the window which is currently active”. It seems that Claude’s new computer use ability, in it’s early version, is grappling with this problem:
While we expect this capability to improve rapidly in the coming months, Claude’s current ability to use computers is imperfect. Some actions that people perform effortlessly — scrolling, dragging, zooming — currently present challenges for Claude and we encourage developers to begin exploration with low-risk tasks. — Source
Of course, I don’t know exactly what Anthropic is doing behind the scenes, but to me it seems pretty obvious that they’re using some derivative of a ReAct style agent, likely with some minor task-specific modifications. If you want to know how to make A ReAct agent yourself from scratch, check out this article:

You might be wondering how the Claude computer use agent can deal with screenshots. If the agent is fundamentally a language model under the hood, how can it observe, reason on, and intelligibly decide actions based on screenshots? We’ll talk about that in the next section.
How It Works — Multimodality
In the last section we briefly discussed what a ReAct style agent is and how it works from a high level: It plans, chooses to perform actions, then makes observations based on those actions. In the original ReAct paper this was done using only text, but computer use requires visual comprehension as well.
In my estimation there are two ways this can be done:
Using a multimodal model
Offloading multimodal operations onto purpose-built models
Claude is a multimodal model (inheriting ideas from the OG Flamingo model) meaning it can understand both images and text. Giving Claude a quick back of the napkin test, it appears that the model is capable of localizing specific objects on a screen.
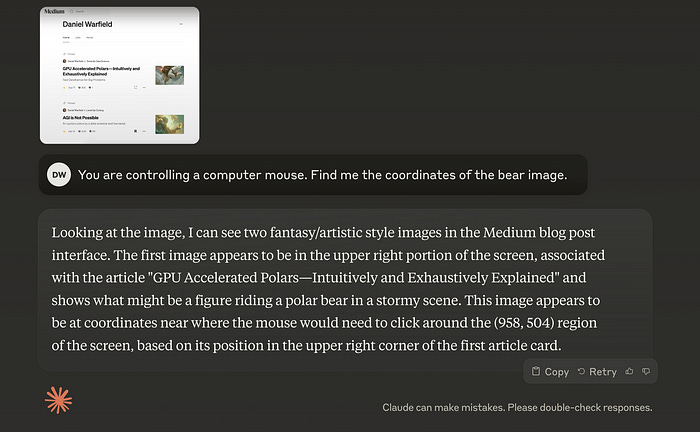
To validate this functionality, I asked it to convert those coordinates to a percentage

And here’s that point overlayed over the original image provided.

Definitely in the right ballpark, but not good enough for computer use. I think it’s also possible that they’re using specific, tailor-made vision models to help the agent execute some tasks within specific use cases.
As an example, one could define a tool which takes in a textual query, like “a picture of a polar bear”, and then tries to find a bounding box for an image that is described by that query using an object detection model. This bounding box could be used to decide where the cursor should click on the image.

Using an out of the box object detection model seems untenable to me, though. Here’s a screenshot from Blender, a 3D modeling tool:
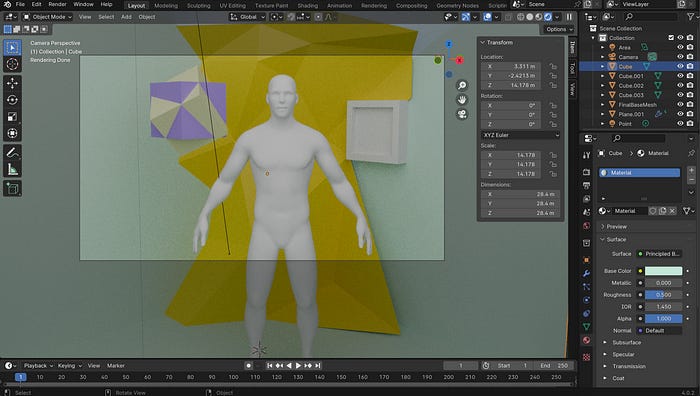
Saying something like “Change the rotation mode to individual origins” would require clicking this little guy up here:

For clicking on a picture of a polar bear on a simple website an object detection model is probably fine, and maybe this type of model is used somewhere in the pipeline of interaction, but for these more nuanced navigational tasks I don’t feel like detection models cut the mustard.
Anthropic doesn’t say a ton about what they’re doing under the hood (which is why I’m doing a lot of guessing), but it seems possible they might be using a fine-tuned model, perhaps using a technology like LoRA, to achieve accurate computer interaction:
The upgraded Claude 3.5 Sonnet and Claude 3.5 Haiku models demonstrate improved facility in tool use and agentic tasks, specifically in the ability to act autonomously, self correct from mistakes, and call external functions. We evaluated these models using several benchmarks, including two external evaluations new to our testing suite: SWE-bench Verified[1] and TAU-bench (τ -bench)[2]. — Source
And it also seems like they’re developing robust tools that have separate models integrated within them.
While Claude’s reliability on computer tasks is not yet on par with human performance, we are establishing several monitoring protocols and mitigations to ensure a safe and measured release of this capability. We’ve also developed sophisticated tools to assess potential Usage Policy violations, such as new classifiers to identify and evaluate the use of computer capabilities. — Source
We can also take a look at the leaderboards for OS World to see what the runner up in the screenshot category, Cradle, is doing in order to guess at some of the things Anthropic might be doing.
Based on my reading, Cradle does use a multimodal LLM as the backbone, but uses a variety of supplemental tools to allow for more robust navigation.
Moreover, for each environment, we enhance LMMs’ abilities with different tools such as template matching [8], Grounding DINO [35], and SAM [29] to provide additional grounding for object detection and localization. — Source
So, between Anthropic’s hints and the approach of similar systems, it seems likely that a lot of the computer interaction is guided by the multimodal LLM, fine tuned for the task of computer interaction, and supported with some additional external tooling/models to make interaction more robust.
I suspect that, as LLM powered agents start to interact with the world in more complex ways, this area of research will mature. Right now it seems like there’s a lot of ways to do this type of interaction sort of well. To me, intelligent navigation and perception of complex textual, spacial, and visual data is the biggest path towards progress in computer use, and maybe AI as a whole.
Conclusion
I’ve been saying this for a while: AI principles are starting to leak into application design. While this functionality is still fairly immature, it feels like we’re rounding the bend on a new and exciting set of capabilities for AI systems. It seems like Agents and rich multimodal comprehension are leading that charge.
If you want to mess around with this yourself, I recommend using a dockerized sandbox so the new fancy AI model can’t take pictures of your bank statements by accident. Here’s a one liner, if you swing that way.
export ANTHROPIC_API_KEY=%your_api_key%
docker run \
-e ANTHROPIC_API_KEY=$ANTHROPIC_API_KEY \
-v $HOME/.anthropic:/home/computeruse/.anthropic \
-p 5900:5900 \
-p 8501:8501 \
-p 6080:6080 \
-p 8080:8080 \
-it ghcr.io/anthropics/anthropic-quickstarts:computer-use-demo-latestBefore pressing play, give this a read, which includes Anthropic’s recommendations on how to use this system safely and securely.
Join Intuitively and Exhaustively Explained
At IAEE you can find:
Long form content, like the article you just read
Thought pieces, based on my experience as a data scientist, engineering director, and entrepreneur
A discord community focused on learning AI
Regular Lectures and office hours
