
Agent To Agent Protocol — Intuitively and Exhaustively Explained
An in-depth exploration of modern networking in an AI world


In this article we’ll discuss “Agent to Agent Protocol” (A2A), the new and hot communication protocol designed to allow LLM agents to talk to one another. The internet is bright with speculation about an AI-first internet featuring websites talking to each other with natural text. We’ll explore A2A, how it works, what it’s useful for, and how realistic that vision of the future is. We’ll also explore how A2A and MCP (model context protocol) might work together to build modern AI-powered applications.
Who is this useful for? Anyone interested in forming a complete understanding of AI
How advanced is this post? This article is conceptually accessible to all readers, especially the earlier sections. The implementation sections are intended for more advanced readers and developers.
Prerequisites: The earlier conceptual sections are approachable to anyone. Later sections are geared towards people with some knowledge of LLM agents and MCP servers. Supplementary material is provided throughout the article.
Some Important Background Concepts
To thoroughly understand this article, I think it’s important to first understand the context in which A2A is currently being developed. Feel free to skip any of the following subsections if you’re already familiar, or check out the supporting material if you’d like a more in-depth explanation.
Background: LLMs
You probably have an idea of what LLMs are and how they work. As a refresher, LLM stands for “large language model”, and is a large AI model designed to be able to output text based on input text. This approach lit up in popularity thanks to models like GPT

The essential idea is that LLMs are next word predictors. They guess the next word in an input, then guess the next word, then repeatedly guess more words until an entire output is predicted.

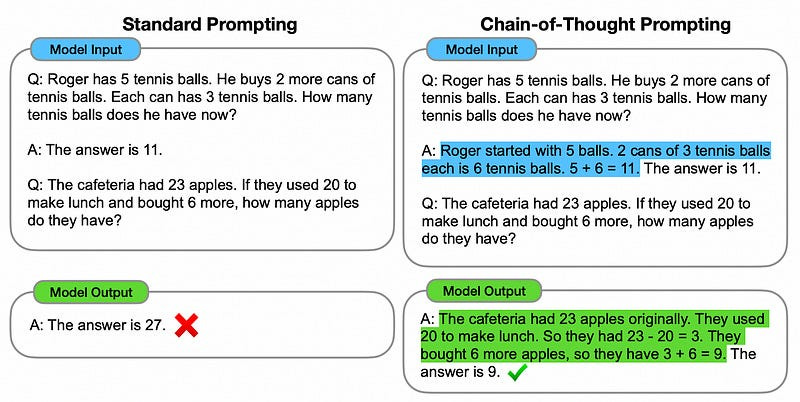
Background: Chain of Thought Prompting
LLMs are like big fancy next-word predictors; they use previous words to predict future words. The user's input is included in those “previous words”, so the user's query influences the output generation from the model. Thus, prompt engineering was born.
One of the most important ideas of prompting is “chain of thought”, which is a method of prompting that coaxes the model into thinking through a problem before solving it.
Because the LLM uses previous words to predict future words, if the LLM solved sub-components of a user's query, it can use that previous output when constructing the final output.
Background: Retrieval Augmented Generation
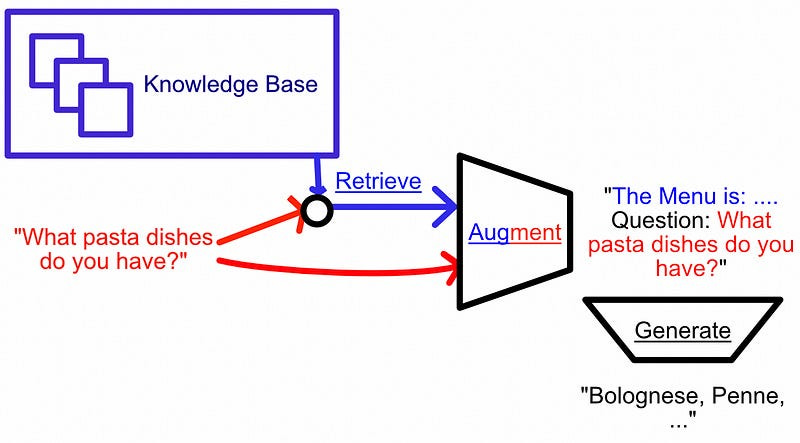
Retrieval Augmented Generation (RAG) is an approach to adding external information into a model's prompts in order to make the model better at answering certain types of questions. As the name implies, the approach consists of three key parts:
Retrieval: When the user submits a query, we look through a knowledge base to find information that is relevent to that query.
Augment: We construct an “augmented prompt”, which is just a combination of the user's question and whatever knowledge was retrieved in the retrieval step.
Generate: We pass the augmented prompt to the LLM for generation.
This is an incredibly powerful general approach as it allows for, essentially, arbitrary information to be injected into a language model as needed. I describe the fundamentals of the subject in the following article:

I also regularly film a podcast that covers more advanced RAG concepts in depth. In that podcast, I cover more advanced RAG topics:
and also happened to cover the exact topic that we’ll be discussing today:
Background: Agents
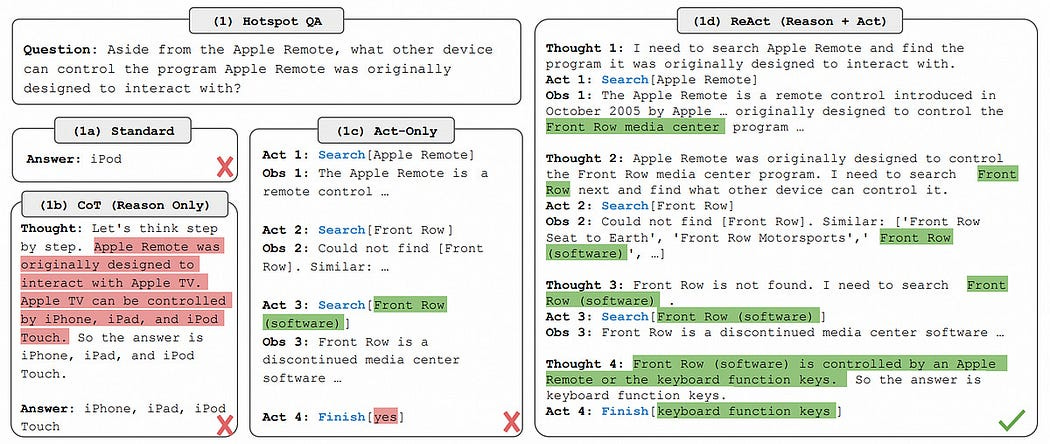
Generally speaking, an “Agent” is what you get when wrapping an LLM inside some greater logical loop. There are a ton of different types of Agents, but the most common I see is a “ReAct” style of agent.
When defining a ReAct agent, you usually start by defining some collection of “tools”. A tool, from an agentic perspective, is a piece of code that the agent can decide to run. You might have tools for looking up weather forcasts, running pieces of code, interacting with the user via a UI, whatever.
Once you have some tools, you define a ReAct style agent by telling the model it will be able to do three things:
Think: The model will be prompted to output a thought as to what to do next.
Act: The model will be able to decide to execute a certain tool.
Observe: The model will have an opportunity to observe results of tool use, and say what is useful in the output. This allows the agent to extract useful information and put it into the continuum of chat memory.
Conceptually, you can think of this as a marriage between chain of thought and RAG. I cover Agents in general, including ReAct style agents, in the following article:

Background: Model Context Protocol
Model Context Protocol (MCP) has been the latest hotness in the AI space. Recently released by Anthropic, MCP is a communication protocol (sort of) that standardizes how LLM agents interact with tools. The idea is that you can define an MCP server, which in turn defines a selection of tools, and you can plug that server into any compatible MCP client (which has an LLM agent under the hood), and that agent can run those tools.
MCP has some abstractions on top of LSPs that allow for some approaches that don’t make sense for LSPs, but the core workflow is identical.
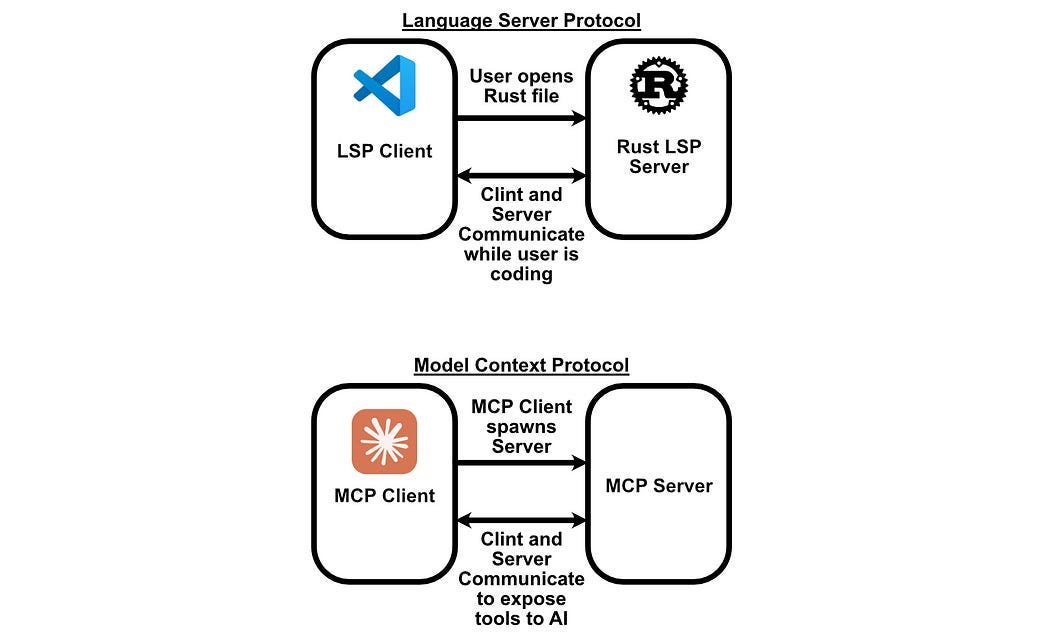
The main difference between MCP and LSPs is in resource definitions. While LSPs have a bunch of resources that are useful to code editors, MCP is designed to have resources that are convenient for AI models.
I cover MCP in depth in another article, if you want to take a look:

MCP was originally designed to allow Claude Desktop to interact with local tools, but Anthropic open-sourced the technology, sparking a wave of excitement around arbitrarily interoperable AI agents. Agent to agent protocol is largely an extension of this excitement.
Agent to Agent Protocol, In a Nutshell
It’s important to note, both MCP and A2A are recently introduced protocols, and as such they are very much in the maturation state. Exactly what these protocols do, and what they’re used for, is likely to evolve as both MCP and A2A mature, and as new protocols are proposed within the greater LLM Agent communication space.
As of now, if model context protocol (MCP) is designed to connect LLM agents to tools, then A2A is designed to connect LLM agents with each other. A2A is largely a complement to MCP, with MCP functioning as a hierarchical tool based exposure, and A2A functioning as a peer-to-peer exposure.
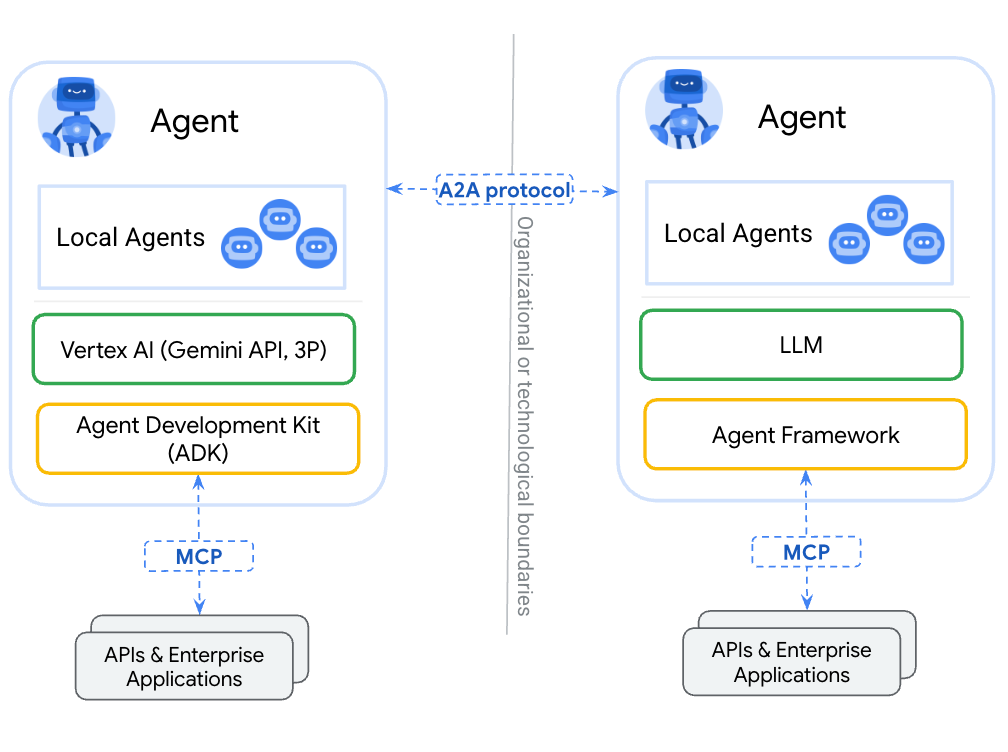
A2A, in its most essential conceptualization, has two fundamental parts:
Agent Cards: These are JSON objects that provide textual descriptions of what the agent is designed to do, which tasks it can perform, etc. This is designed to allow agents to discover each other's capabilities so that they can choose when it’s necessary to talk to another agent, and what that agent might be able to help with.
Tasks: These are units of work which the client (usually an AI agent) requests of a server (also usually an AI agent). Depending on how the A2A server is implemented, the response might be streamed in, or it might be received as a big lump response.
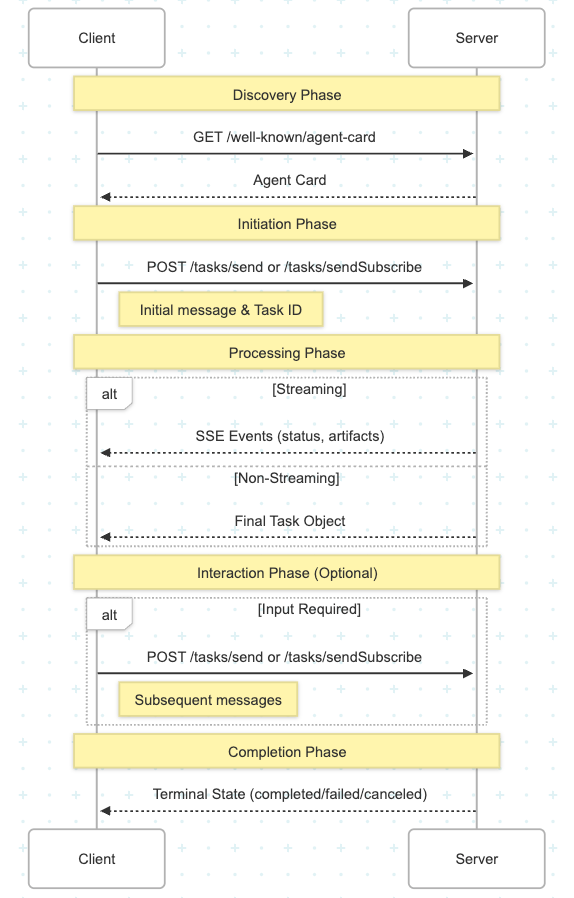
So, let’s say some company has an agent you want to talk to. You could build an A2A client, request the agent card from the company, then an LLM agent in your A2A client could choose when it might need to talk with this foreign agent.
This is super exciting because, now, companies can define their own AI agents and expose them to external users. The agent can operate on behalf of the user, but in a secure and controllable environment. Just like how websites allow humans to talk with servers using pre-defined APIs, the idea of A2A is that A2A will allow agents to talk with servers using pre-defined A2A interfaces.
The Fundamental Protocols and Frameworks of A2A
We’ll be using Python in this tutorial. The Python implementation of A2A is derivative of a few pre-existing protocols and frameworks that I think would be useful to understand before diving into the intricacies of A2A itself.
Fundamental Protocol: ASGI
ASGI stands for “Asynchronous Server Gateway Interface”, and is a Python-specific standard for implementing asynchronous servers. If you’re familiar with Django or FastAPI, then you’re familiar with ASGI. A2A is built on top of ASGI, which is why it’s relevant for this discussion.
The fundamental idea of ASGI is to create a simple and universal interface for developing asynchronous web applications in Python. An ASGI application is as simple as a single function that takes three arguments: scope, receive, and send.
async def app(scope, receive, send):
#...These arguments are defined as follows:
Scope: A dictionary containing details about the specific connection or incoming request. This information includes details like the protocol type (e.g., “http” or “websocket”), headers, path, and potentially other metadata specific to the connection.
Receive: An asynchronous callable that allows the application to receive events or messages from the server. For instance, in an HTTP request, the
receivecallable would be used to obtain the request body.Send: An asynchronous callable that enables the application to send events or messages back to the server, ultimately relaying information to the client. For example, in an HTTP response, the
sendcallable would be used to send back the response headers and body.
The specifics of how receive and send are defined is, I’m sure, pretty complicated, but you don’t actually need to understand them to use ASGI. If you want to build a simple ASGI application, you simply invoke receive to get the content of the request, and invoke send to send a response.
Here’s an example of me implementing an ASGI application that responds to any request with a Hello from ASGI! response. Full code for this example can be found here.
async def app(scope, receive, send):
"""simple ASGI app that accepts an HTTP request, then sends a response
"""
assert scope["type"] == "http"
# Wait for HTTP request event
request = await receive()
print("Received request:", request)
# Send HTTP response start
await send({
"type": "http.response.start",
"status": 200,
"headers": [
[b"content-type", b"text/plain"]
]
})
# Send HTTP response body
await send({
"type": "http.response.body",
"body": b"Hello from ASGI!",
})Then, you can use an ASGI web server to run the application. Uvicorn is the most popular one. In this particular example I’m using the uv package manager (the name similarity between uvicorn and uv is a coincidence). So, we can run this server via the following command:
uv uvicorn asgi_app:app --port 8000where the script name is asgi_app.py, the function we want to call within that script is app, and we want to run the ASGI server on port 8000. We can then define a simple client application that sends a request to our ASGI-enabled server.
import httpx
import asyncio
async def main():
async with httpx.AsyncClient() as client:
response = await client.get("http://127.0.0.1:8000")
print("Response status code:", response.status_code)
print("Response text:", response.text)
if __name__ == "__main__":
asyncio.run(main())here 127.0.0.1 is local host, and we defined our ASGI server on port 8000. If we go ahead and run this client via
uv run asgi_client.pywe get the following response:
Response status code: 200
Response text: Hello from ASGI!This particular example is simple and thus doesn’t communicate the power of ASGI. The whole reason ASGI is to allow for parallel requests. We can make a simple modification to this application to simulate some load. Full code for this example can be found here.
We’ll modify the server to wait for a specified time based on a query string on the request. The content of the query string can be extracted via the scope.
import asyncio
import time
async def app(scope, receive, send):
assert scope["type"] == "http"
# Extract query param for duration
path = scope["path"]
query = scope.get("query_string", b"").decode()
duration = float(query.split("=")[-1]) if "duration=" in query else 1.0
start = time.time()
await asyncio.sleep(duration) # Simulate async work
end = time.time()
message = f"Waited {duration:.1f} seconds. Elapsed: {end - start:.2f}s"
await send({
"type": "http.response.start",
"status": 200,
"headers": [[b"content-type", b"text/plain"]],
})
await send({
"type": "http.response.body",
"body": message.encode(),
})Then, we can create a new client that submits five requests in rapid succession, each of which has a delay specified of duration seconds (in this case, two seconds).
import httpx
import asyncio
import time
async def fetch(session_id, duration=2.0):
url = f"http://127.0.0.1:8000/?duration={duration}"
async with httpx.AsyncClient() as client:
response = await client.get(url)
print(f"[Session {session_id}] {response.text}")
async def main():
start = time.time()
tasks = [fetch(i, duration=2.0) for i in range(5)]
await asyncio.gather(*tasks)
end = time.time()
print(f"Total elapsed time: {end - start:.2f}s")
if __name__ == "__main__":
asyncio.run(main())So, we’re sending five requests, each of which takes two seconds long. If this were happening synchronously, we would expect to be done in 10 seconds. However, because requests are being executed in parallel, it all gets done in around 2 seconds. Here’s the output from the sample client:
[Session 0] Waited 2.0 seconds. Elapsed: 2.00s
[Session 1] Waited 2.0 seconds. Elapsed: 2.00s
[Session 2] Waited 2.0 seconds. Elapsed: 2.00s
[Session 3] Waited 2.0 seconds. Elapsed: 2.00s
[Session 4] Waited 2.0 seconds. Elapsed: 2.00s
Total elapsed time: 2.12sWe don’t have to go too far in the weeds of ASGI. I wanted to cover it briefly, though, because A2A uses an ASGI-enabled framework called Starlette.
Fundamental Framework: Starlette
Starlette is a framework built around ASGI. It obeys the core ideas of ASGI, but with some quality of life stuff built on top of it.
Given a simple ASGI application
import asyncio
async def app(scope, receive, send):
assert scope['type'] == 'http'
body = b"Hello from raw ASGI!"
await send({
'type': 'http.response.start',
'status': 200,
'headers': [
(b'content-type', b'text/plain'),
(b'content-length', str(len(body)).encode())
]
})
await send({
'type': 'http.response.body',
'body': body,
})We can build a similar thing with Starlette
from starlette.applications import Starlette
from starlette.responses import PlainTextResponse
from starlette.routing import Route
async def homepage(request):
return PlainTextResponse("Hello from Starlette!")
app = Starlette(routes=[
Route("/", homepage),
])It’s basically the same thing, but Starlette has some quality of life abstractions. You can launch either application
uvicorn raw_asgi:app
uvicorn starlette_app:appThen run a simple client
import httpx
def call_server():
response = httpx.get("http://localhost:8000")
print("Response:", response.text)
if __name__ == "__main__":
call_server()with
uv run client.pywhich will talk to either server. You’ll get the response Hello from Starlette! or Hello from raw ASGI!, depending on which server you ran.
Of course, there’s some other stuff running under the hood, but A2A in Python is essentially an abstraction on top of Starlette. You don’t need to know the ins and outs of Starlette to use A2A, but it’s useful to have a high-level understanding. We can get started with A2A by simply mimicking this simple hello world Starlette app.
Getting Started with A2A
In being an early-stage protocol without a convenient abstracted framework, A2A implementation can be a bit cumbersome. There are a lot of imports that aren’t super well documented. Most of the A2A code I’ll be showing you is derived from examples defined in this repo of examples. The full code for this example can be found here.
Alright, here’s an A2A server, which mimics the “hello world” examples from the previous few examples.
from a2a.server.agent_execution import AgentExecutor, RequestContext
from a2a.server.apps import A2AStarletteApplication
from a2a.server.request_handlers import DefaultRequestHandler
from a2a.server.tasks import InMemoryTaskStore
from a2a.server.events import EventQueue
from a2a.utils import new_agent_text_message
from a2a.types import AgentCard, AgentSkill, AgentCapabilities
import uvicorn
class HelloExecutor(AgentExecutor):
async def execute(self, context: RequestContext, event_queue: EventQueue) -> None:
# Respond with a static hello message
event_queue.enqueue_event(new_agent_text_message("Hello from A2A!"))
async def cancel(self, context: RequestContext, event_queue: EventQueue) -> None:
pass # No-op
def create_app():
skill = AgentSkill(
id="hello",
name="Hello",
description="Say hello to the world.",
tags=["hello", "greet"],
examples=["hello", "hi"]
)
agent_card = AgentCard(
name="HelloWorldAgent",
description="A simple A2A agent that says hello.",
version="0.1.0",
url="http://localhost:9000",
skills=[skill],
capabilities=AgentCapabilities(),
authenticationSchemes=["public"],
defaultInputModes=["text"],
defaultOutputModes=["text"],
)
handler = DefaultRequestHandler(
agent_executor=HelloExecutor(),
task_store=InMemoryTaskStore()
)
app = A2AStarletteApplication(agent_card=agent_card, http_handler=handler)
return app.build()
if __name__ == "__main__":
uvicorn.run(create_app(), host="127.0.0.1", port=9000)From a high level, there are some familiar suspects. In the final __main__ expression we’re running our A2A app with uvicorn.run. The app itself is an A2AStarletteApplication which, I guess, is a class that abstracts implementing the A2A protocol within a starlette application.
Recall that the core of A2A exists in two key concepts:
Agent Cards: JSON objects defining what the agent can do, which are used to communicate the capabilities of the agent to other agents.
Tasks: An agent can be given a task, which it can then execute (asynchronously, because A2A is built on ASGI in Python).
Within this application, the agent card is defined with the following:
skill = AgentSkill(
id="hello",
name="Hello",
description="Say hello to the world.",
tags=["hello", "greet"],
examples=["hello", "hi"]
)
agent_card = AgentCard(
name="HelloWorldAgent",
description="A simple A2A agent that says hello.",
version="0.1.0",
url="http://localhost:9000",
skills=[skill],
capabilities=AgentCapabilities(),
authenticationSchemes=["public"],
defaultInputModes=["text"],
defaultOutputModes=["text"],
)The agent card is chiefly a description of the agent, and a description of the tasks which the agent can perform. Based on the A2A documentation, the agent card consists of:
details the agent’s identity (name, description), service endpoint URL, version, supported A2A capabilities (like streaming or push notifications), specific skills it offers, default input/output modalities, and authentication requirements. — Source
On top of the agent card, we also need to build the logic that defines the agent itself. Normally, this is an LLM agent, but because we’re mimicking our simple startlette app from before, our “agent” will simply return a hello.
class HelloExecutor(AgentExecutor):
async def execute(self, context: RequestContext, event_queue: EventQueue) -> None:
# Respond with a static hello message
event_queue.enqueue_event(new_agent_text_message("Hello from A2A!"))
async def cancel(self, context: RequestContext, event_queue: EventQueue) -> None:
pass # No-opnormally the execute function would be more complicated and include some fancy AI stuff.
We can talk to this agent with an A2A-compatible client.
import asyncio
from uuid import uuid4
import httpx
from a2a.client import A2ACardResolver, A2AClient
from a2a.types import MessageSendParams, SendMessageRequest
async def main():
base_url = "http://localhost:9000"
async with httpx.AsyncClient() as httpx_client:
# Resolve the agent card
resolver = A2ACardResolver(httpx_client=httpx_client, base_url=base_url)
agent_card = await resolver.get_agent_card()
# Create client from card
client = A2AClient(httpx_client=httpx_client, agent_card=agent_card)
# Build request payload
message = {
"role": "user",
"parts": [{"kind": "text", "text": "hello"}],
"messageId": uuid4().hex,
}
request = SendMessageRequest(
id=str(uuid4()),
params=MessageSendParams(message=message),
)
# Send message and print response
response = await client.send_message(request)
print("Response:", response.model_dump(mode='json', exclude_none=True))
if __name__ == "__main__":
asyncio.run(main())There’s some weirdness I still don’t completely understand. You might notice the agent_card has a url, but you also pass a base_url to the A2ACardResolver. I’ve noticed, in my experimentation, that there are issues when the agent card isn’t configured correctly, even when a base url is specified correctly. I think the base_url can be used to discover agent cards which point to the actual agent. I’ll cover some of the more subtle workflows like that in future articles.
Anywho, we get the agent_card and then connect to the agent with A2AClient(httpx_client=httpx_client, agent_card=agent_card). We can then send messages to that agent, and get responses.
A2A messages consist of the following:
Role: either a “user” or “agent”.
Message Id: A unique id for each message.
Part: a component of the message.
Parts contain the core components of the message. A2A is designed to be multimodal, so parts can consist of “Text”, but can also consist of “File” or “Data”, allowing A2A to communicate various types of data.
We can turn the message into a request, get a response, and bada bing bada boom, the world's most over-complicated hello world application.
if we run the server with
uv run a2a_server.py and the client with
uv run a2a_client.py then we get the following response from the client
Response: {'id': '48d2ef86-d9f5-4382-9f53-2c926dbf1f64', 'jsonrpc': '2.0', 'result': {'kind': 'message', 'messageId': 'c802cb80-2cf8-497c-a9ad-267da60eb1aa', 'parts': [{'kind': 'text', 'text': 'Hello from A2A!'}], 'role': 'agent'}}And, in essence, that’s A2A. It really has nothing to do with LLM agents intrinsically, but is rather a standardized communication protocol designed to assist in building interoperable LLM agents.
But this wouldn’t be an IAEE article if we didn’t dig into it. Let’s build an LLM-powered application with A2A to see how it ticks.
The Plan
The whole idea of A2A is to allow for the creation of arbitrary interoperable agents. Like countless programmers before me, I thought vacation booking was a decent test bed for this type of functionality.
Imagine you’re a company like Trivago or Kayak, and your job consists of booking things like flights and car rentals. In the future, one might be able to imagine an AI agent that’s defined by a car rental company, and another agent that’s maintained by an airline. Trivago can’t (and shouldn’t) be able to modify the database in these booking companies directly, but perhaps Trivago could have an agent that can talk to the car rental and airline agents. Thus these agents could work together to help a customer book their vacation without exposing their information to each other.
This application will mature as we explore it practically. When setting off, I imagined something like this:

A good first step to making this work would probably be to figure out how to get an MCP server to connect to an A2A server, so we can provide tools to each agent.
Launching MCP from A2A
Full code for this example can be found here.
First, we can define a simple MCP server for our agent to use.
from mcp.server.fastmcp import FastMCP
mcp = FastMCP("server")
@mcp.tool()
def say_hello(name: str) -> str:
return f"Hello, {name}! This is MCP."This MCP server exposes a single tool called say_hello , which simply returns a hello string from the MCP server.
We can then implement an A2A server, which functions as an MCP client.
from a2a.server.agent_execution import AgentExecutor, RequestContext
from a2a.server.apps import A2AStarletteApplication
from a2a.server.request_handlers import DefaultRequestHandler
from a2a.server.tasks import InMemoryTaskStore
from a2a.server.events import EventQueue
from a2a.utils import new_agent_text_message
from a2a.types import AgentCard, AgentSkill, AgentCapabilities
import uvicorn
from mcp import ClientSession, StdioServerParameters, types
from mcp.client.stdio import stdio_client
from contextlib import AsyncExitStack
class MCPClient:
def __init__(self):
# Initialize session and client objects
self.session = None
self.exit_stack = AsyncExitStack()
async def connect_to_server(self):
"""Connect to an MCP server
Args:
server_script_path: Path to the server script (.py or .js)
"""
server_params = StdioServerParameters(
command="mcp",
args=["run", "mcp_server.py"],
)
stdio_transport = await self.exit_stack.enter_async_context(stdio_client(server_params))
self.stdio, self.write = stdio_transport
self.session = await self.exit_stack.enter_async_context(ClientSession(self.stdio, self.write))
await self.session.initialize()
# List available tools
response = await self.session.list_tools()
tools = response.tools
print("\nConnected to server with tools:", [tool.name for tool in tools])
async def call_tool(self, tool_name, tool_args):
response = await self.session.call_tool(tool_name, tool_args)
return response
async def cleanup(self):
"""Clean up resources"""
await self.exit_stack.aclose()
class HelloExecutor(AgentExecutor):
def __init__(self, mcp_client):
super().__init__()
self.mcp_client = mcp_client
async def execute(self, context: RequestContext, event_queue: EventQueue) -> None:
#talking to MCP server
mcp_response = await self.mcp_client.call_tool('say_hello', {'name': 'a2a Server'})
mcp_response = mcp_response.content[0].text
response = f'Hello from A2A server! This server functions as an MCP client.\nThe MCP server told me:\n\n{mcp_response}'
await event_queue.enqueue_event(new_agent_text_message(response))
async def cancel(self, context: RequestContext, event_queue: EventQueue) -> None:
pass # No-op
def create_app():
skill = AgentSkill(
id="hello",
name="Hello",
description="Say hello to the world.",
tags=["hello", "greet"],
examples=["hello", "hi"]
)
agent_card = AgentCard(
name="HelloWorldAgent",
description="A simple A2A agent that says hello.",
version="0.1.0",
url="http://localhost:9000",
skills=[skill],
capabilities=AgentCapabilities(),
authenticationSchemes=["public"],
defaultInputModes=["text"],
defaultOutputModes=["text"],
)
# Placeholder executor to be set during startup
handler = DefaultRequestHandler(
agent_executor=None,
task_store=InMemoryTaskStore()
)
app = A2AStarletteApplication(agent_card=agent_card, http_handler=handler)
starlette_app = app.build()
mcp_client = MCPClient()
@starlette_app.on_event("startup")
async def _startup():
print('startup procedure!')
await mcp_client.connect_to_server()
handler.agent_executor = HelloExecutor(mcp_client)
print('startup completed!')
@starlette_app.on_event("shutdown")
async def _shutdown():
print('shutdown: cleaning up MCP client...')
await mcp_client.cleanup()
return starlette_app
if __name__ == "__main__":
uvicorn.run(create_app(), host="127.0.0.1", port=9000)This is pretty much the same as the previous A2A server we defined, but with a few important modifications.
In the create_app function, we convert the A2AStarletteApplication into a Starlette app with app.build(). That allows us to do some starlette specific stuff, like defining functions that run when the starlette app starts and ends.
These two functions allow us to launch the MCP server on startup, and tear it down when we close the A2A server.
@starlette_app.on_event("startup")
async def _startup():
print('startup procedure!')
await mcp_client.connect_to_server()
handler.agent_executor = HelloExecutor(mcp_client)
print('startup completed!')
@starlette_app.on_event("shutdown")
async def _shutdown():
print('shutdown: cleaning up MCP client...')
await mcp_client.cleanup()We connect to the MCP server with the following:
async def connect_to_server(self):
"""Connect to an MCP server
Args:
server_script_path: Path to the server script (.py or .js)
"""
server_params = StdioServerParameters(
command="mcp",
args=["run", "mcp_server.py"],
)
stdio_transport = await self.exit_stack.enter_async_context(stdio_client(server_params))
self.stdio, self.write = stdio_transport
self.session = await self.exit_stack.enter_async_context(ClientSession(self.stdio, self.write))
await self.session.initialize()
# List available tools
response = await self.session.list_tools()
tools = response.tools
print("\nConnected to server with tools:", [tool.name for tool in tools])I won’t get too in the weeds of how launching an MCP server works, if you want some more information on that, I have an article that covers the subject:
Our agent executor takes the query and passes it over to the say_hello tool defined in the MCP server.
class HelloExecutor(AgentExecutor):
def __init__(self, mcp_client):
super().__init__()
self.mcp_client = mcp_client
async def execute(self, context: RequestContext, event_queue: EventQueue) -> None:
#talking to MCP server
mcp_response = await self.mcp_client.call_tool('say_hello', {'name': 'a2a Server'})
mcp_response = mcp_response.content[0].text
response = f'Hello from A2A server! This server functions as an MCP client.\nThe MCP server told me:\n\n{mcp_response}'
await event_queue.enqueue_event(new_agent_text_message(response))
async def cancel(self, context: RequestContext, event_queue: EventQueue) -> None:
pass # No-opThus, when we query our A2A server to say hello, it will tell our MCP server to say hello and return the response to the user.
If we whip up a client and ask our A2A server to say hello
import asyncio
from uuid import uuid4
import httpx
from a2a.client import A2ACardResolver, A2AClient
from a2a.types import MessageSendParams, SendMessageRequest
import json
async def main():
base_url = "http://localhost:9000"
async with httpx.AsyncClient() as httpx_client:
# Resolve the agent card
resolver = A2ACardResolver(httpx_client=httpx_client, base_url=base_url)
agent_card = await resolver.get_agent_card()
# Create client from card
client = A2AClient(httpx_client=httpx_client, agent_card=agent_card)
# Build request payload
message = {
"role": "user",
"parts": [{"kind": "text", "text": "hello"}],
"messageId": uuid4().hex,
}
request = SendMessageRequest(
id=str(uuid4()),
params=MessageSendParams(message=message),
)
# Send message and print response
response = await client.send_message(request)
print("Response:\n", json.dumps(response.model_dump(mode='json', exclude_none=True),indent=2))
if __name__ == "__main__":
asyncio.run(main())we get the following response
{
"id": "97aa4793-36fb-4bde-8bff-959bcbaa2894",
"jsonrpc": "2.0",
"result": {
"kind": "message",
"messageId": "950e2b38-0ce0-43e1-ace1-a76323fe2bdb",
"parts": [
{
"kind": "text",
"text": "Hello from A2A server! This server functions as an MCP client.\nThe MCP server told me:\n\nHello, a2a Server! This is MCP."
}
],
"role": "agent"
}
}As you can see, our A2A server said hello, and also forwarded the MCP server's response, which also said hello.
Alright, things are looking up. Let’s get an AI model in the mix.
Defining an AI Agent In The A2A Server
In the previous section, we defined an A2A server that talks to and communicates with an MCP server. We’re going to keep this same structure, but instead stick an actual LLM in the A2A server, which is the whole point of A2A to begin with. We’ll use Anthropic for this application, but you could swap it out for OpenAI or Google or whatever. Most major LLMs support MCP. Full code for this example can be found here.
import os
import uvicorn
import anthropic
import httpx
from contextlib import AsyncExitStack
from a2a.server.agent_execution import AgentExecutor, RequestContext
from a2a.server.apps import A2AStarletteApplication
from a2a.server.request_handlers import DefaultRequestHandler
from a2a.server.tasks import InMemoryTaskStore
from a2a.server.events import EventQueue
from a2a.utils import new_agent_text_message
from a2a.types import AgentCard, AgentSkill, AgentCapabilities
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from dotenv import load_dotenv
load_dotenv()
ANTHROPIC_API_KEY = os.getenv("ANTHROPIC_API_KEY")
MODEL_NAME = "claude-3-opus-20240229"
class MCPClient:
def __init__(self):
self.session = None
self.exit_stack = AsyncExitStack()
async def connect_to_server(self):
server_params = StdioServerParameters(
command="mcp",
args=["run", "mcp_server.py"],
)
stdio_transport = await self.exit_stack.enter_async_context(stdio_client(server_params))
self.stdio, self.write = stdio_transport
self.session = await self.exit_stack.enter_async_context(ClientSession(self.stdio, self.write))
await self.session.initialize()
async def cleanup(self):
await self.exit_stack.aclose()
class ClaudeSessionManager:
"""Manages a full Claude session with optional MCP tool usage."""
def __init__(self, mcp_session: ClientSession, anthropic_client: anthropic.Anthropic, model: str = MODEL_NAME):
self.session = mcp_session
self.anthropic = anthropic_client
self.model = model
self.verbose = True
async def run_session(self, user_input: str) -> str:
tools_response = await self.session.list_tools()
tools = [{
"name": tool.name,
"description": tool.description,
"input_schema": tool.inputSchema
} for tool in tools_response.tools]
if self.verbose: print('running Claude session')
messages = [{"role": "user", "content": [{"type": "text", "text": user_input}]}]
final_output = []
if self.verbose: print('initializing with message to Claude:')
if self.verbose: print(messages)
response = self.anthropic.messages.create(
model=self.model,
max_tokens=1000,
tools=tools,
messages=messages,
)
if self.verbose: print('response received from Claude')
if self.verbose: print(response)
while True:
assistant_content = []
for part in response.content:
if part.type == "text":
final_output.append(part.text)
assistant_content.append(part)
elif part.type == "tool_use":
try:
tool_result = await self.session.call_tool(part.name, part.input)
messages.append({"role": "assistant", "content": assistant_content})
messages.append({
"role": "user",
"content": [{
"type": "tool_result",
"tool_use_id": part.id,
"content": tool_result.content
}]
})
response = self.anthropic.messages.create(
model=self.model,
max_tokens=1000,
tools=tools,
messages=messages
)
break
except Exception as e:
return f"❌ Tool call failed: {e}"
else:
break
return "\n".join(final_output)
class ClaudeAgentExecutor(AgentExecutor):
"""Handles A2A requests by invoking Claude for tool reasoning."""
def __init__(self, session_manager: ClaudeSessionManager):
super().__init__()
self.session_manager = session_manager
async def execute(self, context: RequestContext, event_queue: EventQueue):
try:
#unpacking the message request from the a2a client
request = context.message.parts[0].root.text
print(f'request from A2A Client: {request}')
response = await self.session_manager.run_session(request)
except Exception as e:
response = f"❌ Error: {e}"
await event_queue.enqueue_event(new_agent_text_message(response))
async def cancel(self, context: RequestContext, event_queue: EventQueue):
pass
def create_app():
skill = AgentSkill(
id="claude_tool_agent",
name="Tool Agent",
description="An agent powered by Claude with access to MCP tools.",
tags=["llm", "tools", "claude"],
examples=["Say hello", "What tools can you use?", "Get me a summary"]
)
agent_card = AgentCard(
name="ClaudeToolAgent",
description="An A2A agent that uses Anthropic Claude 3 with tool calling via MCP.",
version="0.1.0",
url="http://localhost:9000",
skills=[skill],
capabilities=AgentCapabilities(),
authenticationSchemes=["public"],
defaultInputModes=["text"],
defaultOutputModes=["text"],
)
handler = DefaultRequestHandler(agent_executor=None, task_store=InMemoryTaskStore())
app = A2AStarletteApplication(agent_card=agent_card, http_handler=handler)
starlette_app = app.build()
mcp_client = MCPClient()
anthropic_client = anthropic.Anthropic(api_key=ANTHROPIC_API_KEY)
@starlette_app.on_event("startup")
async def _startup():
await mcp_client.connect_to_server()
session_manager = ClaudeSessionManager(mcp_client.session, anthropic_client)
handler.agent_executor = ClaudeAgentExecutor(session_manager)
print("✅ A2A server connected to MCP and Claude 3.")
@starlette_app.on_event("shutdown")
async def _shutdown():
await mcp_client.cleanup()
print("🛑 Cleaned up MCP session.")
return starlette_app
if __name__ == "__main__":
uvicorn.run(create_app(), host="127.0.0.1", port=9000)It’s a lot of code, chiefly because of boilerplate. The main difference is that the agent executor (now called ClaudeAgentExecutor, thanks to LLMs having a fun time renaming random stuff in my codebase) interfaces with a new class called ClaudeSessionManager. This is the bit that talks to the LLM.
The run_session function in the ClaudeSessionManager unpacks the tools and passes them to the LLM in the initial prompt, allowing the model to know which tools it has access to. The user's prompt is passed into the initial pass to the LLM, and then we enter an evaluation loop.
while True:
assistant_content = []
for part in response.content:
if part.type == "text":
final_output.append(part.text)
assistant_content.append(part)
elif part.type == "tool_use":
try:
tool_result = await self.session.call_tool(part.name, part.input)
messages.append({"role": "assistant", "content": assistant_content})
messages.append({
"role": "user",
"content": [{
"type": "tool_result",
"tool_use_id": part.id,
"content": tool_result.content
}]
})
response = self.anthropic.messages.create(
model=self.model,
max_tokens=1000,
tools=tools,
messages=messages
)
break
except Exception as e:
return f"❌ Tool call failed: {e}"
else:
breakThis is the bulk of the agent. If the model responds that a tool should be used, we call that tool and add the response to the chat continuum, then prompt the model again. We keep doing that until the model doesn’t think more tool use is necessary.
Full disclosure, most of this is AI-generated, so there might be some janky stuff going on. I have some more scratch-made agentic implementation ideas in a few other articles.

Agentic design isn’t really the point of this article, though, so let’s move on.
In this particular example we didn’t modify our mcp_server.py at all
from mcp.server.fastmcp import FastMCP
mcp = FastMCP("server")
@mcp.tool()
def say_hello(name: str) -> str:
return f"Hello, {name}! This is MCP."But we did modify the sample client. Here, we’re asking the agent to tell us which tools it has access to.
import asyncio
from uuid import uuid4
import httpx
from a2a.client import A2ACardResolver, A2AClient
from a2a.types import MessageSendParams, SendMessageRequest
import json
async def test_a2a_server():
base_url = "http://localhost:9000"
async with httpx.AsyncClient(timeout=httpx.Timeout(30.0)) as httpx_client:
# Resolve the agent card
resolver = A2ACardResolver(httpx_client=httpx_client, base_url=base_url)
agent_card = await resolver.get_agent_card()
# Create A2A client from the card
client = A2AClient(httpx_client=httpx_client, agent_card=agent_card)
# Define the user message
text_input = "What tools can you use?"
# Build the A2A-compliant message payload
message = {
"role": "user",
"parts": [
{"kind": "text", "text": text_input}
],
"messageId": uuid4().hex
}
request = SendMessageRequest(
id=str(uuid4()),
params=MessageSendParams(message=message),
)
# Send message to A2A agent
response = await client.send_message(request)
# Print out formatted response
print("Response:\n", json.dumps(response.model_dump(mode='json', exclude_none=True), indent=2))
if __name__ == "__main__":
asyncio.run(test_a2a_server())Here, the a2a server is called travel_agent.py (I thought I’d get further along in this particular example), and the client is called a2a_test_client.py.
if we run
uv run travel_agent.pythen
uv run a2a_test_cleint.pyOur A2A test client gets the following output from Claude, running in the A2A server:
<thinking>
To determine what tools I can use, I’ll look at the JSONSchema provided that lists the available tools and their parameters.It looks like there is just a single tool available called “say_hello”. This tool takes a single required parameter called “name” which is a string.
Since the user just asked what tools are available and did not provide a name to say hello to, I do not have enough information to actually call the say_hello tool at this time. I’ll just inform the user about the one tool that is available.
</thinking>Based on the information provided, there is one tool I can use called “say_hello”. This tool takes a single required parameter “name” which should be a string value.
When given a name, this tool presumably would output a hello greeting to the specified name. For example, if called with the name “Alice”, it may return something like “Hello Alice!”.
Let me know if you would like me to use this tool to say hello to a specific name!
So, the tool we have access to doesn’t do much, but our agent can clearly see and converse about our tool use! Let’s do one more intermediate experiment, building a simple A2A server with MCP, but this time let’s make the MCP server actually do something.
Defining an A2A agent, with a Database Interfacing MCP Server
Alright, I’ve copied virtually the same code with minor modifications a few times now. For the sake of saving a few electrons, let’s just focus on the MCP server. Full code for this example can be found here.
First, I created a file called define_db.py, which defines an SQLite database.
import os
import sqlite3
import random
from datetime import datetime, timedelta
DB_NAME = "flights.db"
# Remove existing database file if it exists
if os.path.exists(DB_NAME):
os.remove(DB_NAME)
print(f"Removed existing database '{DB_NAME}'.")
# Connect to the new SQLite database
conn = sqlite3.connect(DB_NAME)
cursor = conn.cursor()
# Create the flights table
cursor.execute("""
CREATE TABLE flights (
id INTEGER PRIMARY KEY AUTOINCREMENT,
flight_number TEXT NOT NULL,
departure_airport TEXT NOT NULL,
arrival_airport TEXT NOT NULL,
departure_time TEXT NOT NULL,
arrival_time TEXT NOT NULL,
available_seats INTEGER NOT NULL,
status TEXT CHECK(status IN ('scheduled', 'cancelled', 'completed')) NOT NULL DEFAULT 'scheduled'
)
""")
# Sample airport codes
airport_codes = ["JFK", "LAX", "ORD", "DFW", "DEN", "SFO", "ATL", "SEA", "MIA", "BOS", "LHR", "CDG", "FRA", "DXB", "HND"]
# Generate random flights
def generate_random_flight(index: int):
dep_airport, arr_airport = random.sample(airport_codes, 2)
base_time = datetime(2025, 6, 15)
departure_time = base_time + timedelta(hours=random.randint(0, 300))
flight_duration = timedelta(hours=random.randint(1, 15), minutes=random.choice([0, 15, 30, 45]))
arrival_time = departure_time + flight_duration
flight_number = f"{random.choice(['AA', 'DL', 'UA', 'BA', 'LH', 'AF', 'EK'])}{100 + index}"
available_seats = random.randint(0, 200)
status = random.choices(["scheduled", "cancelled", "completed"], weights=[0.7, 0.1, 0.2])[0]
return (
flight_number,
dep_airport,
arr_airport,
departure_time.strftime("%Y-%m-%d %H:%M"),
arrival_time.strftime("%Y-%m-%d %H:%M"),
available_seats,
status
)
# Generate and insert many flights
num_flights = 500
flights_data = [generate_random_flight(i) for i in range(num_flights)]
cursor.executemany("""
INSERT INTO flights (flight_number, departure_airport, arrival_airport, departure_time, arrival_time, available_seats, status)
VALUES (?, ?, ?, ?, ?, ?, ?)
""", flights_data)
conn.commit()
conn.close()
print(f"Database '{DB_NAME}' created with {num_flights} synthetic flight records.")If you’re not familiar with SQL and SQLite, I have an article on the subject.

If you don’t feel like learning about it, don’t sweat it. All that’s important to know is that we now have a file called flights.db that has flight information.
Our mcp_server.py will reference this database and expose access to it in the form of tools.
import html
import aiosqlite
from mcp.server.fastmcp import FastMCP
from typing import Annotated
mcp = FastMCP("sqlite-fastmcp-server")
DB_PATH = "flights.db" # change this or pass via env/arg if needed
@mcp.tool()
async def sqlite_get_catalog() -> str:
"""List tables and columns in the SQLite database."""
async with aiosqlite.connect(f"file:{DB_PATH}?mode=ro", uri=True) as conn:
cursor = await conn.execute("SELECT name FROM sqlite_master WHERE type='table'")
tables = [row[0] for row in await cursor.fetchall()]
catalog = {}
for table in tables:
col_cursor = await conn.execute(f"PRAGMA table_info({table})")
columns = [col[1] for col in await col_cursor.fetchall()]
catalog[table] = columns
return str(catalog)
@mcp.tool()
async def sqlite_execute(sql: Annotated[str, "SQL SELECT statement"]) -> str:
"""Execute a SQL query and return HTML table of results."""
async with aiosqlite.connect(f"file:{DB_PATH}?mode=ro", uri=True) as conn:
cursor = await conn.execute(sql)
if not cursor.description:
return "Statement executed successfully."
headers = "".join(f"<th>{html.escape(col[0])}</th>" for col in cursor.description)
rows_html = f"<tr>{headers}</tr>"
for row in await cursor.fetchall():
row_cells = "".join(f"<td>{html.escape(str(val))}</td>" for val in row)
rows_html += f"<tr>{row_cells}</tr>"
return f"<table>{rows_html}</table>"
if __name__ == "__main__":
mcp.run()In reality, if you were building an actual MCP server to be used in an actual production agent, I imagine you wouldn’t want the agent defining it’s own SQL queries and arbitrarily interacting with the database. For our purposes, though, I think this is fine for now.
At this point, I started playing around with naming conventions as I slowly converged on our end goal. Here, the A2A server is called airline_agent.py and the A2A client is called travel_agent.py. The travel_agent.py isn’t anything special though, it’s just a simple client that asks the A2A server the following question:
Can you tell me the shortest expected flight duration from each airport?
Tell me the response of the query in a markdown table.if we run
uv run airline_agent.py then run
uv run travel_agent.py we get the following output:
<thinking>
To answer this request, I need to:1. Get a list of all the airports in the database by querying the airports table. This will give me the airport codes to use in the next step.
2. For each airport code, find the flight with the minimum expected duration by:
a) Joining the flights and airports tables to get flights.origin_airport = airports.code
b) Grouping by origin airport code
c) Taking the MIN(scheduled_duration)3. Format the results into a markdown table with columns for airport code and minimum expected duration.
I have all the information needed to execute these steps with the given tools.
</thinking>It looks like the `airports` table doesn’t exist in this database. Let me check what tables are available.
The database only contains a `flights` table, not an `airports` table. Let me try this again using just the `flights` table:
Here is the minimum expected flight duration for each departure airport, formatted as a markdown table:
| airport | min_expected_duration |
| — — — — -| — — — — — — — — — — — — |
| ATL | 0 |
| BOS | 0 |
| CDG | 0 |
| DEN | 0 |
| DFW | 0 |
| DXB | 0 |
| FRA | 0 |
| HND | 0 |
| JFK | 0 |
| LAX | 0 |
| LHR | 0 |
| MIA | 0 |
| ORD | 0 |
| SEA | 0 |
| SFO | 0 |Let me know if you need anything else!
As you can see, the agent tried playing around with a few different tools and SQL queries before settling on an answer. I think the answer is wrong, but whatever; we’re moving on.
Implementing The Travel Agent
In previous examples, we:
Implemented A2A Servers that can run mcp tools
Implemented simple LLM agents in those servers
Implemented tools in the MCP server that allow the agent to query the database
Now we’re going to put it all together to build our travel booking demo. Before we do, though, let’s discuss a quirk of how A2A and MCP are conceptualized vs how they’re implemented.
Recall that, in the beginning of the article, we discussed a diagram of how A2A and MCP interoperate with one another.
This is a fine conceptual breakdown, and I’m sure you could build something that respects this flow. However, as I was combing through tutorials, I found another structure that felt much more intuitive.

When integrating MCP with an agent, we can expose arbitrary tools. Needing to manage both tools for talking with different agents and tools for communicating with an MCP server feels overly complex. If we implement our A2A communication as an MCP tool, we only have to integrate MCP into each of our agents.
For this example, I implemented a travel agent, a car agent, and an airline agent. The MCP server for the travel agent looks like the following. (Full code can be found here):
import html
import aiosqlite
from mcp.server.fastmcp import FastMCP
from typing import Annotated
import httpx
from a2a.client import A2ACardResolver
from a2a.client import A2ACardResolver, A2AClient
from a2a.types import MessageSendParams, SendMessageRequest
from uuid import uuid4
import json
mcp = FastMCP("sqlite-fastmcp-server")
DB_PATH = "travel_agent.db"
#defining info to communicate with the airline agent
with open('port_config.json', 'r') as file:
airline_port = json.load(file)['airline_agent_port']
with open('port_config.json', 'r') as file:
car_port = json.load(file)['car_agent_port']
host = "127.0.0.1"
AIRLINE_AGENT_URL = f'http://{host}:{airline_port}'
CAR_AGENT_URL = f'http://{host}:{car_port}'
@mcp.tool()
async def sqlite_get_catalog() -> str:
"""List tables and columns in the SQLite database."""
async with aiosqlite.connect(f"file:{DB_PATH}?mode=ro", uri=True) as conn:
cursor = await conn.execute("SELECT name FROM sqlite_master WHERE type='table'")
tables = [row[0] for row in await cursor.fetchall()]
catalog = {}
for table in tables:
col_cursor = await conn.execute(f"PRAGMA table_info({table})")
columns = [col[1] for col in await col_cursor.fetchall()]
catalog[table] = columns
return str(catalog)
@mcp.tool()
async def sqlite_select(sql: Annotated[str, "SQL SELECT statement"]) -> str:
"""Execute a SQL query and return HTML table of results."""
async with aiosqlite.connect(f"file:{DB_PATH}?mode=ro", uri=True) as conn:
cursor = await conn.execute(sql)
if not cursor.description:
return "Statement executed successfully."
headers = "".join(f"<th>{html.escape(col[0])}</th>" for col in cursor.description)
rows_html = f"<tr>{headers}</tr>"
for row in await cursor.fetchall():
row_cells = "".join(f"<td>{html.escape(str(val))}</td>" for val in row)
rows_html += f"<tr>{row_cells}</tr>"
return f"<table>{rows_html}</table>"
@mcp.tool()
async def sqlite_modify(sql: Annotated[str, "SQL INSERT/UPDATE/DELETE/DDL statement"]) -> str:
"""Execute a SQL statement that modifies the database and return a success message."""
try:
async with aiosqlite.connect(f"file:{DB_PATH}?mode=rwc", uri=True) as conn:
await conn.execute(sql)
await conn.commit()
return "Statement executed successfully."
except Exception as e:
return f"Error: {html.escape(str(e))}"
@mcp.tool()
async def get_agent_cards() -> str:
"""Get cards of connected agents"""
agent_cards = {}
async with httpx.AsyncClient() as httpx_client:
resolver = A2ACardResolver(httpx_client=httpx_client, base_url=AIRLINE_AGENT_URL)
agent_card = await resolver.get_agent_card()
agent_cards['airline_agent_card'] = agent_card
async with httpx.AsyncClient() as httpx_client:
resolver = A2ACardResolver(httpx_client=httpx_client, base_url=CAR_AGENT_URL)
agent_card = await resolver.get_agent_card()
agent_cards['car_agent_card'] = agent_card
return str(agent_cards)
@mcp.tool()
async def query_airline_agent(query: Annotated[str, "Natural language query to send to the airline agent"]) -> str:
"""Send a natural language query to the airline agent via A2A protocol and return the response."""
async with httpx.AsyncClient(timeout=None) as httpx_client:
# Step 1: Resolve the agent card
resolver = A2ACardResolver(httpx_client=httpx_client, base_url=AIRLINE_AGENT_URL)
agent_card = await resolver.get_agent_card()
# Step 2: Create the A2A client
client = A2AClient(httpx_client=httpx_client, agent_card=agent_card)
# Step 3: Create the message
message = {
"role": "user",
"parts": [
{"kind": "text", "text": query}
],
"messageId": uuid4().hex
}
# Step 4: Wrap in SendMessageRequest
request = SendMessageRequest(
id=str(uuid4()),
params=MessageSendParams(message=message),
)
print('travel mcp querying airline agent...')
# Step 5: Send the message and get a response
response = await client.send_message(request)
return response
@mcp.tool()
async def query_car_agent(query: Annotated[str, "Natural language query to send to the car agent"]) -> str:
"""Send a natural language query to the car agent via A2A protocol and return the response."""
async with httpx.AsyncClient(timeout=None) as httpx_client:
# Step 1: Resolve the agent card
resolver = A2ACardResolver(httpx_client=httpx_client, base_url=CAR_AGENT_URL)
agent_card = await resolver.get_agent_card()
# Step 2: Create the A2A client
client = A2AClient(httpx_client=httpx_client, agent_card=agent_card)
# Step 3: Create the message
message = {
"role": "user",
"parts": [
{"kind": "text", "text": query}
],
"messageId": uuid4().hex
}
# Step 4: Wrap in SendMessageRequest
request = SendMessageRequest(
id=str(uuid4()),
params=MessageSendParams(message=message),
)
# Step 5: Send the message and get a response
response = await client.send_message(request)
return response
if __name__ == "__main__":
mcp.run()I played around with the travel agent having it’s own database (like the database for Kayak or trivago), which the agent can interact with given the following functions
@mcp.tool()
async def sqlite_get_catalog() -> str:
...
@mcp.tool()
async def sqlite_select(sql: Annotated[str, "SQL SELECT statement"]) -> str:
...
@mcp.tool()
async def sqlite_modify(sql: Annotated[str, "SQL INSERT/UPDATE/DELETE/DDL statement"]) -> str:
...But there are also tools that query the airline and car agents
@mcp.tool()
async def query_airline_agent(query: Annotated[str, "Natural language query to send to the airline agent"]) -> str:
...
@mcp.tool()
async def query_car_agent(query: Annotated[str, "Natural language query to send to the car agent"]) -> str:
...If we look at the car agent tool, for example:
@mcp.tool()
async def query_car_agent(query: Annotated[str, "Natural language query to send to the car agent"]) -> str:
"""Send a natural language query to the car agent via A2A protocol and return the response."""
async with httpx.AsyncClient(timeout=None) as httpx_client:
# Step 1: Resolve the agent card
resolver = A2ACardResolver(httpx_client=httpx_client, base_url=CAR_AGENT_URL)
agent_card = await resolver.get_agent_card()
# Step 2: Create the A2A client
client = A2AClient(httpx_client=httpx_client, agent_card=agent_card)
# Step 3: Create the message
message = {
"role": "user",
"parts": [
{"kind": "text", "text": query}
],
"messageId": uuid4().hex
}
# Step 4: Wrap in SendMessageRequest
request = SendMessageRequest(
id=str(uuid4()),
params=MessageSendParams(message=message),
)
# Step 5: Send the message and get a response
response = await client.send_message(request)
return responseWe can see that it simply calls the car agent at the CAR_AGENT_URL. The CAR_AGENT_URL is defined, for this example, as localhost , with the port specified in a file called port_config.json , which looks like this:
{
"travel_agent_port": 9000,
"airline_agent_port": 9001,
"car_agent_port": 9002
}I have this lying around so I can easily reference the ports from different agents.
The code for the actual travel agent looks like this:
from a2a_mcp_server_app_creator import create_app
import json
from a2a.types import AgentCard
if __name__ == "__main__":
#getting agent card
with open('travel_agent_card.json', 'r') as file:
agent_card = AgentCard.model_validate(json.load(file))
#defining mcp server
mcp_script = 'travel_mcp.py'
#getting port
with open('port_config.json', 'r') as file:
port = json.load(file)['travel_agent_port']
#defining host (local host)
host = "127.0.0.1"
print('=== creating car agent ===')
print(f'port: {port}')
print(f'mcp_server: {mcp_script}')
print('=== Agent Card ===')
print(agent_card)
create_app(agent_card, mcp_script, host, port)The travel agent is, itself, an A2A application with it’s own model card. We won’t have any agents talking to our travel agent, but we certainly could! Because it’s an A2A agent, it needs an agent card which is defined in travel_agent_card.json. I kept this pretty minimal because no other agents will be talking with this agent.
{
"name": "Travel Agent",
"description": "Travel agent, that talks to the airline and car agent",
"url": "http://localhost:9000/",
"provider": null,
"version": "1.0.0",
"documentationUrl": null,
"capabilities": {
"streaming": "True",
"pushNotifications": "True",
"stateTransitionHistory": "False"
},
"authentication": {
"credentials": null,
"schemes": [
"public"
]
},
"defaultInputModes": [
"text",
"text/plain"
],
"defaultOutputModes": [
"text",
"text/plain"
],
"skills": [
]
}The travel agent leverages the MCP script we previously discussed, meaning it can talk with other agents via A2A.
We actually go about creating the agent via the create_app function. I got sick of copying the same code over and over again. Because I needed to create three agents, I made a function create_app that accepts (agent_card, mcp_script, host, port) and spools up an A2A agent, with access to that MCP server, at the specified host and port.
If we take a gander at a2a_mcp_server_app_creator.py, which contains the create_app function, we’ll see a lot of familiar code. This is essentially a generalized version of the A2A agents we’ve defined previously.
import os
import uvicorn
import anthropic
import httpx
from contextlib import AsyncExitStack
from a2a.server.agent_execution import AgentExecutor, RequestContext
from a2a.server.apps import A2AStarletteApplication
from a2a.server.request_handlers import DefaultRequestHandler
from a2a.server.tasks import InMemoryTaskStore
from a2a.server.events import EventQueue
from a2a.utils import new_agent_text_message
from a2a.types import AgentCard, AgentSkill, AgentCapabilities
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
from dotenv import load_dotenv
load_dotenv()
ANTHROPIC_API_KEY = os.getenv("ANTHROPIC_API_KEY")
MODEL_NAME = "claude-3-opus-20240229"
class MCPClient:
def __init__(self, script):
self.session = None
self.exit_stack = AsyncExitStack()
self.script = script
async def connect_to_server(self):
server_params = StdioServerParameters(
command="mcp",
args=["run", self.script],
)
stdio_transport = await self.exit_stack.enter_async_context(stdio_client(server_params))
self.stdio, self.write = stdio_transport
self.session = await self.exit_stack.enter_async_context(ClientSession(self.stdio, self.write))
await self.session.initialize()
async def cleanup(self):
await self.exit_stack.aclose()
class ClaudeSessionManager:
"""Manages a full Claude session with optional MCP tool usage."""
def __init__(self, mcp_session: ClientSession, anthropic_client: anthropic.Anthropic, model: str = MODEL_NAME):
self.session = mcp_session
self.anthropic = anthropic_client
self.model = model
self.verbose = True
async def run_session(self, user_input: str) -> str:
tools_response = await self.session.list_tools()
tools = [{
"name": tool.name,
"description": tool.description,
"input_schema": tool.inputSchema
} for tool in tools_response.tools]
if self.verbose: print('running Claude session')
messages = [{"role": "user", "content": [{"type": "text", "text": user_input}]}]
final_output = []
if self.verbose: print('initializing with message to Claude:')
if self.verbose: print(messages)
response = self.anthropic.messages.create(
model=self.model,
max_tokens=1000,
tools=tools,
system=(
"You are a helpful support agent. "
"Use the tools provided to answer user questions accurately. "
"If a tool is called, make sure to read and interpret the results. "
"The user can not see tool output. Your final response should use the tool output to answer the users question."
"If a users query requires querying a database, for instance, be sure to provide the actual data in the end response to the user."
"The current date is 2025, 6, 15. The time is 5:00pm"
),
messages=messages,
)
if self.verbose: print('response received from Claude')
if self.verbose: print(response)
while True:
assistant_content = []
for part in response.content:
if part.type == "text":
print(part.text)
final_output.append(part.text)
assistant_content.append(part)
elif part.type == "tool_use":
try:
tool_result = await self.session.call_tool(part.name, part.input)
# Record the assistant response including the tool_use block
messages.append({
"role": "assistant",
"content": [p.model_dump() for p in response.content]
})
# Add the tool result message from the user
messages.append({
"role": "user",
"content": [{
"type": "tool_result",
"tool_use_id": part.id,
"content": tool_result.content
}]
})
# Re-query Claude with the updated conversation
response = self.anthropic.messages.create(
model=self.model,
max_tokens=1000,
tools=tools,
messages=messages
)
break
except Exception as e:
return f"❌ Tool call failed: {e}"
else:
break
return "\n".join(final_output)
class ClaudeAgentExecutor(AgentExecutor):
"""Handles A2A requests by invoking Claude for tool reasoning."""
def __init__(self, session_manager: ClaudeSessionManager):
super().__init__()
self.session_manager = session_manager
async def execute(self, context: RequestContext, event_queue: EventQueue):
try:
#unpacking the message request from the a2a client
request = context.message.parts[0].root.text
print(f'request from A2A Client: {request}')
response = await self.session_manager.run_session(request)
except Exception as e:
response = f"❌ Error: {e}"
await event_queue.enqueue_event(new_agent_text_message(response))
async def cancel(self, context: RequestContext, event_queue: EventQueue):
pass
def create_app(agent_card, mcp_script, host, port):
handler = DefaultRequestHandler(agent_executor=None, task_store=InMemoryTaskStore())
app = A2AStarletteApplication(agent_card=agent_card, http_handler=handler)
starlette_app = app.build()
anthropic_client = anthropic.Anthropic(api_key=ANTHROPIC_API_KEY)
mcp_client = MCPClient(mcp_script)
@starlette_app.on_event("startup")
async def _startup():
await mcp_client.connect_to_server()
session_manager = ClaudeSessionManager(mcp_client.session, anthropic_client)
handler.agent_executor = ClaudeAgentExecutor(session_manager)
print("✅ A2A server connected to MCP and Claude 3.")
@starlette_app.on_event("shutdown")
async def _shutdown():
await mcp_client.cleanup()
print("🛑 Cleaned up MCP session.")
uvicorn.run(starlette_app, host=host, port=port)We have logic for spawning an MCP server, handling communication with Claude, defining an agent executor that’s compatible with A2A, and creating a starlette app run with uvicorn at the specified host and port.
Because we have this generalized code, it’s actually pretty easy to define our airline and car agents; we just need to define their MCP servers and agent cards.
Here’s the MCP script I defined for the car agent
import html
import aiosqlite
from mcp.server.fastmcp import FastMCP
from typing import Annotated
import httpx
from a2a.client import A2ACardResolver
from a2a.client import A2ACardResolver, A2AClient
from a2a.types import MessageSendParams, SendMessageRequest
from uuid import uuid4
import json
mcp = FastMCP("sqlite-fastmcp-server")
DB_PATH = "airline.db" # change this or pass via env/arg if needed
#defining info to communicate with the car agent
with open('port_config.json', 'r') as file:
port = json.load(file)['car_agent_port']
host = "127.0.0.1"
CAR_AGENT_URL = f'http://{host}:{port}'
@mcp.tool()
async def sqlite_get_catalog() -> str:
"""List tables and columns in the SQLite database."""
async with aiosqlite.connect(f"file:{DB_PATH}?mode=ro", uri=True) as conn:
cursor = await conn.execute("SELECT name FROM sqlite_master WHERE type='table'")
tables = [row[0] for row in await cursor.fetchall()]
catalog = {}
for table in tables:
col_cursor = await conn.execute(f"PRAGMA table_info({table})")
columns = [col[1] for col in await col_cursor.fetchall()]
catalog[table] = columns
return str(catalog)
@mcp.tool()
async def sqlite_select(sql: Annotated[str, "SQL SELECT statement"]) -> str:
"""Execute a SQL query and return HTML table of results. This queries the airline data, the structure of which is defined by the sqlite_get_catalog tool"""
async with aiosqlite.connect(f"file:{DB_PATH}?mode=ro", uri=True) as conn:
cursor = await conn.execute(sql)
if not cursor.description:
return "Statement executed successfully."
headers = "".join(f"<th>{html.escape(col[0])}</th>" for col in cursor.description)
rows_html = f"<tr>{headers}</tr>"
for row in await cursor.fetchall():
row_cells = "".join(f"<td>{html.escape(str(val))}</td>" for val in row)
rows_html += f"<tr>{row_cells}</tr>"
return f"<table>{rows_html}</table>"
@mcp.tool()
async def sqlite_modify(sql: Annotated[str, "SQL INSERT/UPDATE/DELETE/DDL statement"]) -> str:
"""Execute a SQL statement that modifies the database and return a success message."""
try:
async with aiosqlite.connect(f"file:{DB_PATH}?mode=rwc", uri=True) as conn:
await conn.execute(sql)
await conn.commit()
return "Statement executed successfully."
except Exception as e:
return f"Error: {html.escape(str(e))}"
@mcp.tool()
async def get_car_agent_card() -> str:
async with httpx.AsyncClient() as httpx_client:
resolver = A2ACardResolver(httpx_client=httpx_client, base_url=CAR_AGENT_URL)
agent_card = await resolver.get_agent_card()
return str(agent_card)
@mcp.tool()
async def query_car_agent(query: Annotated[str, "Natural language query to send to the car agent"]) -> str:
"""Send a natural language query to the car agent via A2A protocol and return the response."""
async with httpx.AsyncClient(timeout=None) as httpx_client:
# Step 1: Resolve the agent card
resolver = A2ACardResolver(httpx_client=httpx_client, base_url=CAR_AGENT_URL)
agent_card = await resolver.get_agent_card()
# Step 2: Create the A2A client
client = A2AClient(httpx_client=httpx_client, agent_card=agent_card)
# Step 3: Create the message
message = {
"role": "user",
"parts": [
{"kind": "text", "text": query}
],
"messageId": uuid4().hex
}
# Step 4: Wrap in SendMessageRequest
request = SendMessageRequest(
id=str(uuid4()),
params=MessageSendParams(message=message),
)
# Step 5: Send the message and get a response
response = await client.send_message(request)
return response
if __name__ == "__main__":
mcp.run()And here’s the MCP script I defined for the airline agent
import html
import aiosqlite
from mcp.server.fastmcp import FastMCP
from typing import Annotated
import httpx
from a2a.client import A2ACardResolver
from a2a.client import A2ACardResolver, A2AClient
from a2a.types import MessageSendParams, SendMessageRequest
from uuid import uuid4
import json
mcp = FastMCP("sqlite-fastmcp-server")
DB_PATH = "airline.db" # change this or pass via env/arg if needed
#defining info to communicate with the car agent
with open('port_config.json', 'r') as file:
port = json.load(file)['car_agent_port']
host = "127.0.0.1"
CAR_AGENT_URL = f'http://{host}:{port}'
@mcp.tool()
async def sqlite_get_catalog() -> str:
"""List tables and columns in the SQLite database."""
async with aiosqlite.connect(f"file:{DB_PATH}?mode=ro", uri=True) as conn:
cursor = await conn.execute("SELECT name FROM sqlite_master WHERE type='table'")
tables = [row[0] for row in await cursor.fetchall()]
catalog = {}
for table in tables:
col_cursor = await conn.execute(f"PRAGMA table_info({table})")
columns = [col[1] for col in await col_cursor.fetchall()]
catalog[table] = columns
return str(catalog)
@mcp.tool()
async def sqlite_select(sql: Annotated[str, "SQL SELECT statement"]) -> str:
"""Execute a SQL query and return HTML table of results. This queries the airline data, the structure of which is defined by the sqlite_get_catalog tool"""
async with aiosqlite.connect(f"file:{DB_PATH}?mode=ro", uri=True) as conn:
cursor = await conn.execute(sql)
if not cursor.description:
return "Statement executed successfully."
headers = "".join(f"<th>{html.escape(col[0])}</th>" for col in cursor.description)
rows_html = f"<tr>{headers}</tr>"
for row in await cursor.fetchall():
row_cells = "".join(f"<td>{html.escape(str(val))}</td>" for val in row)
rows_html += f"<tr>{row_cells}</tr>"
return f"<table>{rows_html}</table>"
@mcp.tool()
async def sqlite_modify(sql: Annotated[str, "SQL INSERT/UPDATE/DELETE/DDL statement"]) -> str:
"""Execute a SQL statement that modifies the database and return a success message."""
try:
async with aiosqlite.connect(f"file:{DB_PATH}?mode=rwc", uri=True) as conn:
await conn.execute(sql)
await conn.commit()
return "Statement executed successfully."
except Exception as e:
return f"Error: {html.escape(str(e))}"
@mcp.tool()
async def get_car_agent_card() -> str:
async with httpx.AsyncClient() as httpx_client:
resolver = A2ACardResolver(httpx_client=httpx_client, base_url=CAR_AGENT_URL)
agent_card = await resolver.get_agent_card()
return str(agent_card)
@mcp.tool()
async def query_car_agent(query: Annotated[str, "Natural language query to send to the car agent"]) -> str:
"""Send a natural language query to the car agent via A2A protocol and return the response."""
async with httpx.AsyncClient(timeout=None) as httpx_client:
# Step 1: Resolve the agent card
resolver = A2ACardResolver(httpx_client=httpx_client, base_url=CAR_AGENT_URL)
agent_card = await resolver.get_agent_card()
# Step 2: Create the A2A client
client = A2AClient(httpx_client=httpx_client, agent_card=agent_card)
# Step 3: Create the message
message = {
"role": "user",
"parts": [
{"kind": "text", "text": query}
],
"messageId": uuid4().hex
}
# Step 4: Wrap in SendMessageRequest
request = SendMessageRequest(
id=str(uuid4()),
params=MessageSendParams(message=message),
)
# Step 5: Send the message and get a response
response = await client.send_message(request)
return response
if __name__ == "__main__":
mcp.run()They’re each essentially the same, except I made it so that the agents can talk to each other; so the airline agent can talk with the car agent, and the car agent can talk to the airline agent. I found this, practically, did nothing. For more complex queries though, one might be able to imagine the Airline and Car agents working together to figure some stuff out on the users behalf. I think the application I’m defining in this example is too simple to warrant such complex use cases, though.
Feel free to check out the full code to peruse the agent cards and stuff. I also defined a simple script that spools up databases for the agents to talk to.
Let’s run this sucker. Because the agents talk with one another, they all should be spooled up before we initiate communication. So, in three separate terminals, we can run the following three commands:
uv run airline_agent.py
uv run car_agent.py
uv run travel_agent.pyThen, in yet another terminal, we can run
uv run test_client.pywhich is an easy way to spool up and talk to the travel_agent. You can see an example of me interacting with the client to the right. Notice how, after interacting with the client, it triggers the travel agent (third from the left) which triggers the airline agent (first from the left) and the car agent (second from the left).
So, that’s the rub! Before we wrap up I’d like to conclude with some of my personal thoughts.
Discussion
I think A2A and MCP are super exciting and are a tremendous step in the right direction. The promise of arbitrarily communicating agents doing cool stuff is compelling. However, I don’t think MCP and A2A alone are enough to revolutionize software development into some “AI first” utopia.
One of the consistent issues I have with this new paradigm of “interoperable AI” is prompt engineering (cue eye roll). I know prompt engineering is often used by quasi-developers who barely know what they’re talking about. However, critically, if you do prompting wrong, it’s very hard to make a good application. When integrating A2A and MCP applications, there’s a lot out of one’s control in terms of prompt engineering, which makes it very hard to control specific workflows. I don’t think this is an insurmountable issue, but I think the state of the art needs to evolve best practices to achieve the consistent performance that’s critical in production applications.
Another problem is implementation. There are too many ways to do things, and there’s a ton of boilerplate. Now that MCP and A2A are a thing, high-level frameworks that define and implement best practices need to be popularized. We saw a similar thing with ASGI being wrapped around Starlette and Uvicorn; I think it’s just a matter of time before MCP and A2A see similar frameworks.
All in all, I think this will be a cornerstone of technology moving forward. If I were building a product today, though, I would be reluctant to use either approach. It’s still important to learn, though. I’ll be covering more sophisticated A2A applications in upcoming articles. Stay tuned!